 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Actor-Critic with Cross-Entropy Policy Optimization
Paper and Code
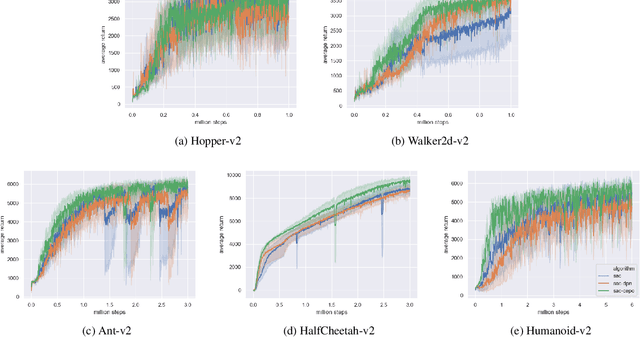

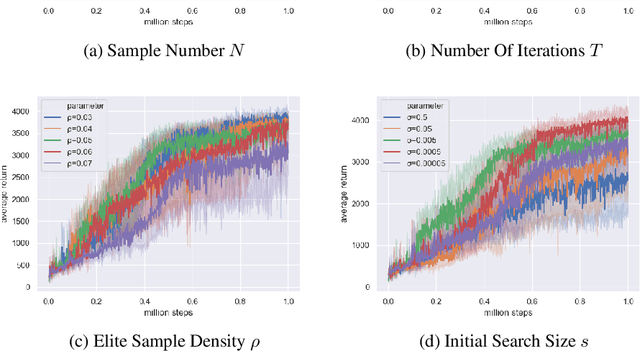

Soft Actor-Critic (SAC) is one of the state-of-the-art off-policy reinforcement learning (RL) algorithms that is within the maximum entropy based RL framework. SAC is demonstrated to perform very well in a list of continous control tasks with good stability and robustness. SAC learns a stochastic Gaussian policy that can maximize a trade-off between total expected reward and the policy entropy. To update the policy, SAC minimizes the KL-Divergence between the current policy density and the soft value function density. Reparameterization trick is then used to obtain the approximate gradient of this divergence. In this paper, we propose Soft Actor-Critic with Cross-Entropy Policy Optimization (SAC-CEPO), which uses Cross-Entropy Method (CEM) to optimize the policy network of SAC. The initial idea is to use CEM to iteratively sample the closest distribution towards the soft value function density and uses the resultant distribution as a target to update the policy network. For the purpose of reducing the computational complexity, we also introduce a decoupled policy structure that decouples the Gaussian policy into one policy that learns the mean and one other policy that learns the deviation such that only the mean policy is trained by CEM. We show that this decoupled policy structure does converge to a optimal and we also demonstrate by experiments that SAC-CEPO achieves competitive performance against the original SAC.