 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Just in Time" World Modeling Supports Human Planning and Reasoning
Jan 20, 2026Probabilistic mental simulation is thought to play a key role in human reasoning, planning, and prediction, yet the demands of simulation in complex environments exceed realistic human capacity limits. A theory with growing evidence is that people simulate using simplified representations of the environment that abstract away from irrelevant details, but it is unclear how people determine these simplifications efficiently. Here, we present a "Just-in-Time" framework for simulation-based reasoning that demonstrates how such representations can be constructed online with minimal added computation. The model uses a tight interleaving of simulation, visual search, and representation modification, with the current simulation guiding where to look and visual search flagging objects that should be encoded for subsequent simulation. Despite only ever encoding a small subset of objects, the model makes high-utility predictions. We find strong empirical support for this account over alternative models in a grid-world planning task and a physical reasoning task across a range of behavioral measures. Together, these results offer a concrete algorithmic account of how people construct reduced representations to support efficient mental simulation.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
A Baseline Analysis of Reward Models' Ability To Accurately Analyze Foundation Models Under Distribution Shift
Dec 04, 2023
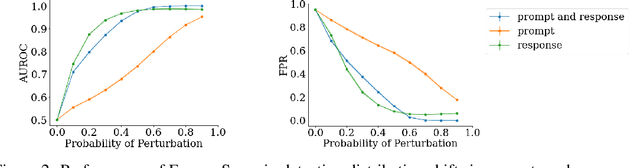
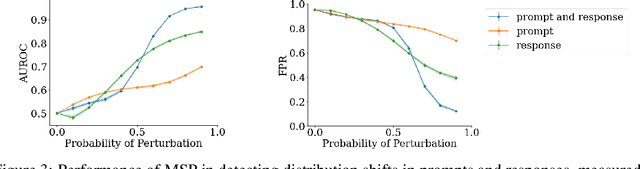
Foundation models, specifically Large Language Models (LLM's), have lately gained wide-spread attention and adoption. Reinforcement Learning with Human Feedback (RLHF) involves training a reward model to capture desired behaviors, which is then used to align LLM's. These reward models are additionally used at inference-time to estimate LLM responses' adherence to those desired behaviors. However, there is little work measuring how robust these reward models are to distribution shifts. In this work, we evaluate how reward model performance - measured via accuracy and calibration (i.e. alignment between accuracy and confidence) - is affected by distribution shift. We show novel calibration patterns and accuracy drops due to OOD prompts and responses, and that the reward model is more sensitive to shifts in responses than prompts. Additionally, we adapt an OOD detection technique commonly used in classification to the reward model setting to detect these distribution shifts in prompts and responses.
Multi-Task Knowledge Enhancement for Zero-Shot and Multi-Domain Recommendation in an AI Assistant Application
Jun 09, 2023Recommender systems have found significant commercial success but still struggle with integrating new users. Since users often interact with content in different domains, it is possible to leverage a user's interactions in previous domains to improve that user's recommendations in a new one (multi-domain recommendation). A separate research thread on knowledge graph enhancement uses external knowledge graphs to improve single domain recommendations (knowledge graph enhancement). Both research threads incorporate related information to improve predictions in a new domain. We propose in this work to unify these approaches: Using information from interactions in other domains as well as external knowledge graphs to make predictions in a new domain that would be impossible with either information source alone. We apply these ideas to a dataset derived from millions of users' requests for content across three domains (videos, music, and books) in a live virtual assistant application. We demonstrate the advantage of combining knowledge graph enhancement with previous multi-domain recommendation techniques to provide better overall recommendations as well as for better recommendations on new users of a domain.
Inferring the Future by Imagining the Past
May 26, 2023A single panel of a comic book can say a lot: it shows not only where characters currently are, but also where they came from, what their motivations are, and what might happen next. More generally, humans can often infer a complex sequence of past and future events from a *single snapshot image* of an intelligent agent. Building on recent work in cognitive science, we offer a Monte Carlo algorithm for making such inferences. Drawing a connection to Monte Carlo path tracing in computer graphics, we borrow ideas that help us dramatically improve upon prior work in sample efficiency. This allows us to scale to a wide variety of challenging inference problems with only a handful of samples. It also suggests some degree of cognitive plausibility, and indeed we present human subject studies showing that our algorithm matches human intuitions in a variety of domains that previous methods could not scale to.
A Boosting Algorithm for Positive-Unlabeled Learning
May 19, 2022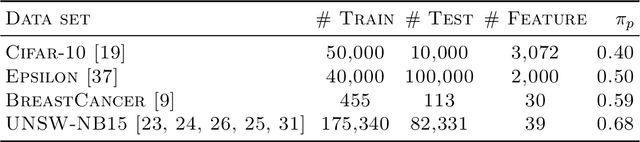
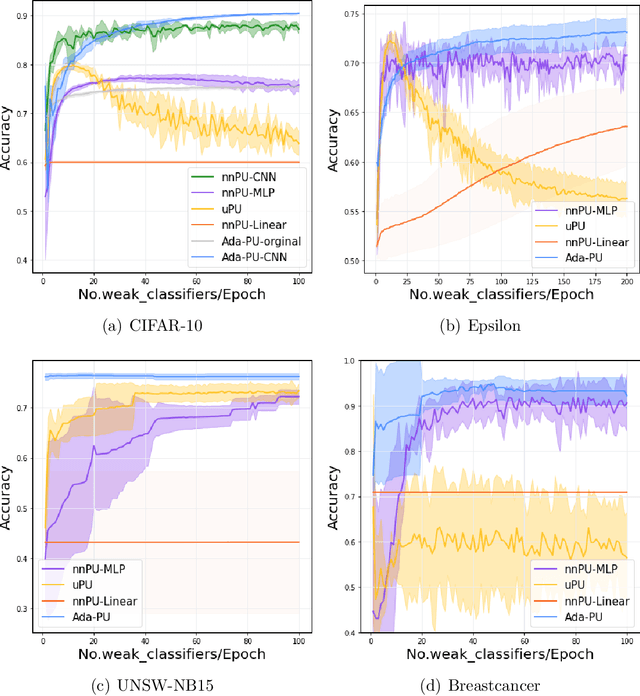

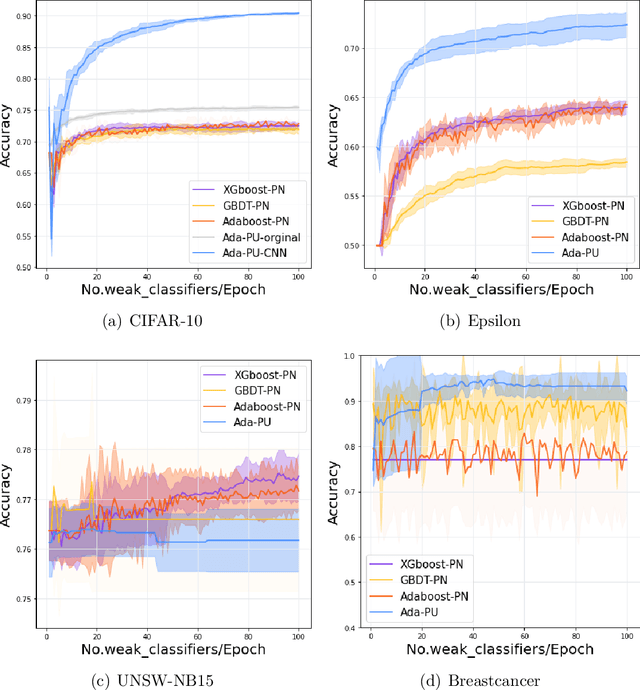
Positive-unlabeled (PU) learning deals with binary classification problems when only positive (P) and unlabeled (U) data are available. A lot of PU methods based on linear models and neural networks have been proposed; however, there still lacks study on how the theoretically sound boosting-style algorithms could work with P and U data. Considering that in some scenarios when neural networks cannot perform as good as boosting algorithms even with fully-supervised data, we propose a novel boosting algorithm for PU learning: Ada-PU, which compares against neural networks. Ada-PU follows the general procedure of AdaBoost while two different distributions of P data are maintained and updated. After a weak classifier is learned on the newly updated distribution, the corresponding combining weight for the final ensemble is estimated using only PU data. We demonstrated that with a smaller set of base classifiers, the proposed method is guaranteed to keep the theoretical properties of boosting algorithm. In experiments, we showed that Ada-PU outperforms neural networks on benchmark PU datasets. We also study a real-world dataset UNSW-NB15 in cyber security and demonstrated that Ada-PU has superior performance for malicious activities detection.