 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Baseline Analysis of Reward Models' Ability To Accurately Analyze Foundation Models Under Distribution Shift
Dec 04, 2023
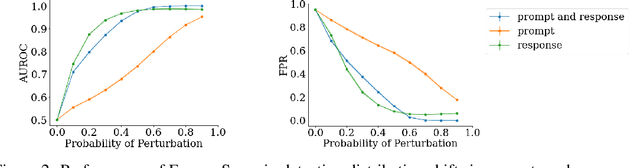
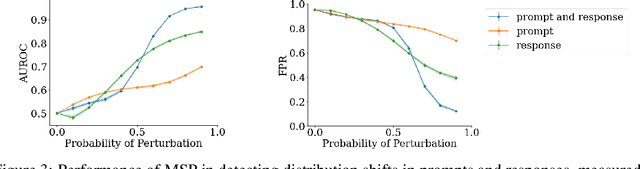
Foundation models, specifically Large Language Models (LLM's), have lately gained wide-spread attention and adoption. Reinforcement Learning with Human Feedback (RLHF) involves training a reward model to capture desired behaviors, which is then used to align LLM's. These reward models are additionally used at inference-time to estimate LLM responses' adherence to those desired behaviors. However, there is little work measuring how robust these reward models are to distribution shifts. In this work, we evaluate how reward model performance - measured via accuracy and calibration (i.e. alignment between accuracy and confidence) - is affected by distribution shift. We show novel calibration patterns and accuracy drops due to OOD prompts and responses, and that the reward model is more sensitive to shifts in responses than prompts. Additionally, we adapt an OOD detection technique commonly used in classification to the reward model setting to detect these distribution shifts in prompts and responses.