 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRubricRefine: Improving Tool-Use Agent Reliability with Training-Free Pre-Execution Refinement
May 10, 2026Iterative self-refinement is a popular inference-time reliability technique, but its effectiveness in code-mode tool use depends heavily on the structure of the feedback signal: unstructured critique helps inconsistently across models, and even revision with real execution feedback improves only modestly ($0.75$ vs. $0.65$ baseline). The dominant failures are inter-tool contract violations - wrong output shape, incorrect tool routing, broken argument provenance - that run to completion without raising errors, making runtime feedback insufficient. We introduce RubricRefine, a training-free pre-execution reliability layer that generates task- and registry-specific rubrics, scores candidate code against explicit contract checks, and iteratively repairs failures before any execution occurs. With zero execution attempts, RubricRefine reaches $0.86$ on M3ToolEval averaged across seven models-improving over prior inference-time baselines on every model tested on this benchmark, at $2.6X$ lower latency than the strongest non-iterative alternative - and remains flat on the predominantly single-step API-Bank, consistent with the method's reliance on inter-tool contract structure. A rubric-category ablation and calibration analysis further characterize when and why the method works.
Out-of-Distribution Detection & Applications With Ablated Learned Temperature Energy
Jan 22, 2024As deep neural networks become adopted in high-stakes domains, it is crucial to be able to identify when inference inputs are Out-of-Distribution (OOD) so that users can be alerted of likely drops in performance and calibration despite high confidence. Among many others, existing methods use the following two scores to do so without training on any apriori OOD examples: a learned temperature and an energy score. In this paper we introduce Ablated Learned Temperature Energy (or "AbeT" for short), a method which combines these prior methods in novel ways with effective modifications. Due to these contributions, AbeT lowers the False Positive Rate at $95\%$ True Positive Rate (FPR@95) by $35.39\%$ in classification (averaged across all ID and OOD datasets measured) compared to state of the art without training networks in multiple stages or requiring hyperparameters or test-time backward passes. We additionally provide empirical insights as to how our model learns to distinguish between In-Distribution (ID) and OOD samples while only being explicitly trained on ID samples via exposure to misclassified ID examples at training time. Lastly, we show the efficacy of our method in identifying predicted bounding boxes and pixels corresponding to OOD objects in object detection and semantic segmentation, respectively - with an AUROC increase of $5.15\%$ in object detection and both a decrease in FPR@95 of $41.48\%$ and an increase in AUPRC of $34.20\%$ on average in semantic segmentation compared to previous state of the art.
A Baseline Analysis of Reward Models' Ability To Accurately Analyze Foundation Models Under Distribution Shift
Dec 04, 2023
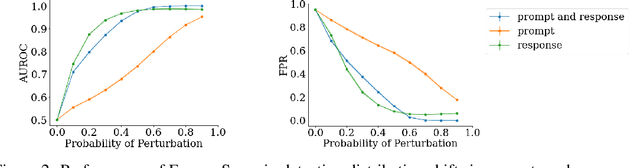
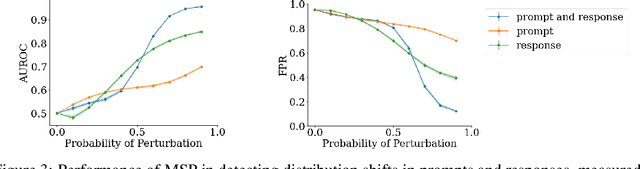
Foundation models, specifically Large Language Models (LLM's), have lately gained wide-spread attention and adoption. Reinforcement Learning with Human Feedback (RLHF) involves training a reward model to capture desired behaviors, which is then used to align LLM's. These reward models are additionally used at inference-time to estimate LLM responses' adherence to those desired behaviors. However, there is little work measuring how robust these reward models are to distribution shifts. In this work, we evaluate how reward model performance - measured via accuracy and calibration (i.e. alignment between accuracy and confidence) - is affected by distribution shift. We show novel calibration patterns and accuracy drops due to OOD prompts and responses, and that the reward model is more sensitive to shifts in responses than prompts. Additionally, we adapt an OOD detection technique commonly used in classification to the reward model setting to detect these distribution shifts in prompts and responses.
Enabling Calibration In The Zero-Shot Inference of Large Vision-Language Models
Mar 11, 2023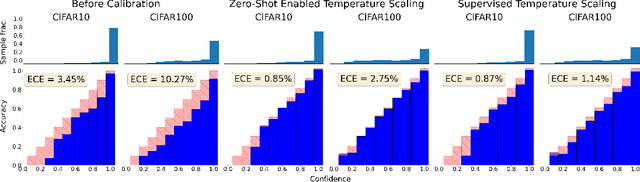
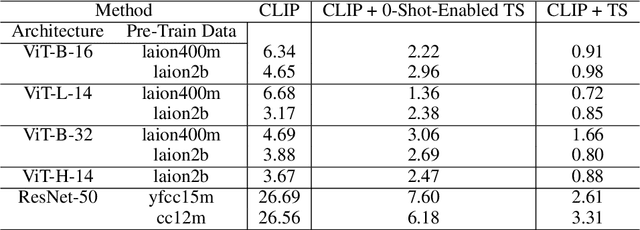
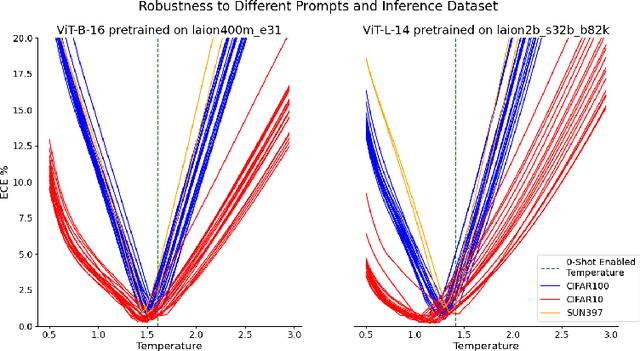
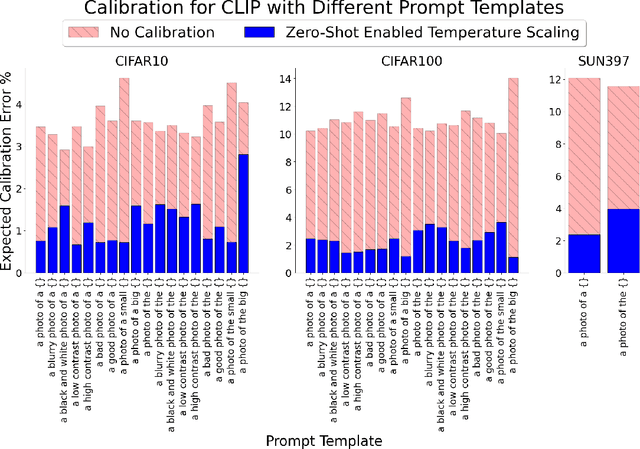
Calibration of deep learning models is crucial to their trustworthiness and safe usage, and as such, has been extensively studied in supervised classification models, with methods crafted to decrease miscalibration. However, there has yet to be a comprehensive study of the calibration of vision-language models that are used for zero-shot inference, like CLIP. We measure calibration across relevant variables like prompt, dataset, and architecture, and find that zero-shot inference with CLIP is miscalibrated. Furthermore, we propose a modified version of temperature scaling that is aligned with the common use cases of CLIP as a zero-shot inference model, and show that a single learned temperature generalizes for each specific CLIP model (defined by a chosen pre-training dataset and architecture) across inference dataset and prompt choice.
Out-of-distribution and in-distribution posterior calibration using Kernel Density Polytopes
Feb 14, 2022

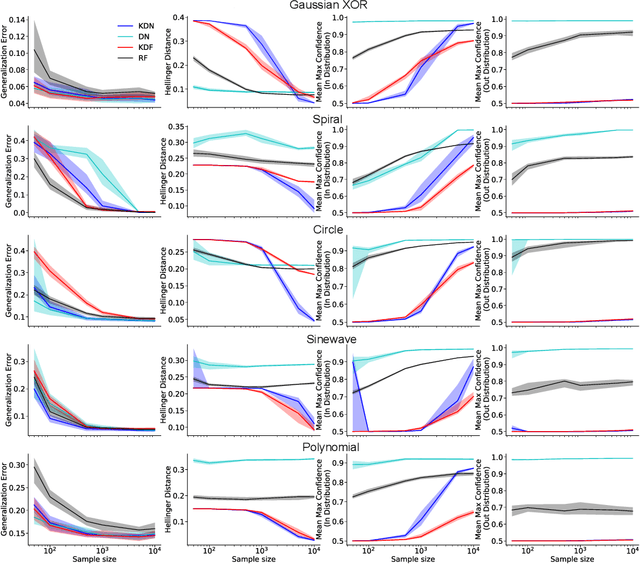
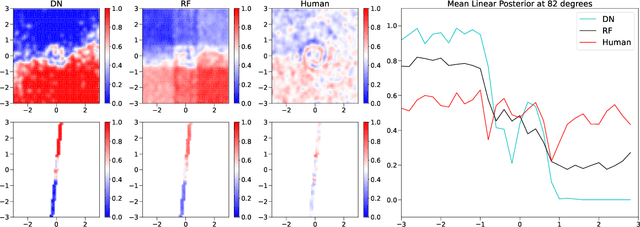
Any reasonable machine learning (ML) model should not only interpolate efficiently in between the training samples provided (in-distribution region), but also approach the extrapolative or out-of-distribution (OOD) region without being overconfident. Our experiment on human subjects justifies the aforementioned properties for human intelligence as well. Many state-of-the-art algorithms have tried to fix the overconfidence problem of ML models in the OOD region. However, in doing so, they have often impaired the in-distribution performance of the model. Our key insight is that ML models partition the feature space into polytopes and learn constant (random forests) or affine (ReLU networks) functions over those polytopes. This leads to the OOD overconfidence problem for the polytopes which lie in the training data boundary and extend to infinity. To resolve this issue, we propose kernel density methods that fit Gaussian kernel over the polytopes, which are learned using ML models. Specifically, we introduce two variants of kernel density polytopes: Kernel Density Forest (KDF) and Kernel Density Network (KDN) based on random forests and deep networks, respectively. Studies on various simulation settings show that both KDF and KDN achieve uniform confidence over the classes in the OOD region while maintaining good in-distribution accuracy compared to that of their respective parent models.
A general approach to progressive learning
Apr 28, 2020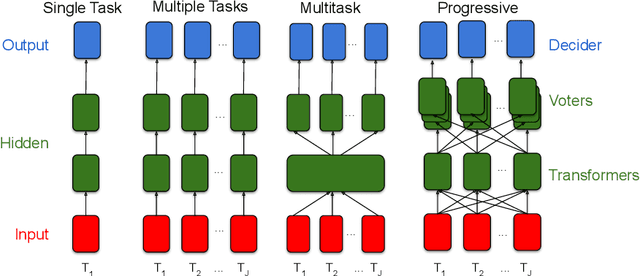
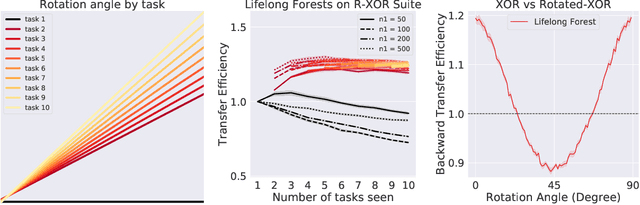

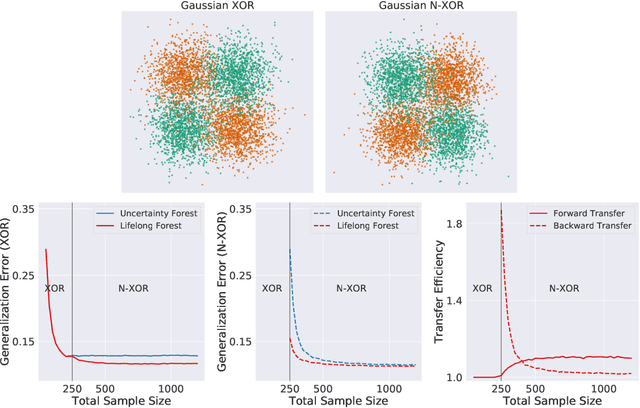
In biological learning, data is used to improve performance on the task at hand, while simultaneously improving performance on both previously encountered tasks and as yet unconsidered future tasks. In contrast, classical machine learning starts from a blank slate, or tabula rasa, using data only for the single task at hand. While typical transfer learning algorithms can improve performance on future tasks, their performance degrades upon learning new tasks. Many recent approaches have attempted to mitigate this issue, called catastrophic forgetting, to maintain performance given new tasks. But striving to avoid forgetting sets the goal unnecessarily low: the goal of progressive learning, whether biological or artificial, is to improve performance on all tasks (including past and future) with any new data. We propose a general approach to progressive learning that ensembles representations, rather than learners. We show that ensembling representations---including representations learned by decision forests or neural networks---enables both forward and backward transfer on a variety of simulated and real data tasks, including vision, language, and adversarial tasks. This work suggests that further improvements in progressive learning may follow from a deeper understanding of how biological learning achieves such high degrees of efficiency.