 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Calibration In The Zero-Shot Inference of Large Vision-Language Models
Mar 11, 2023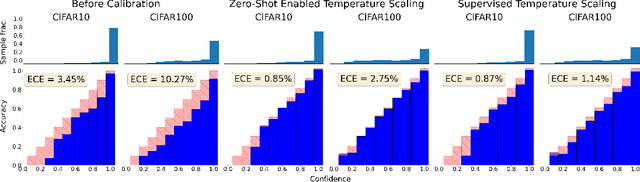
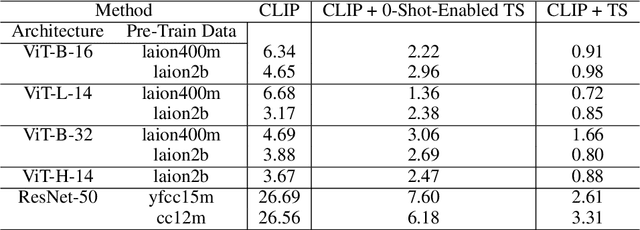
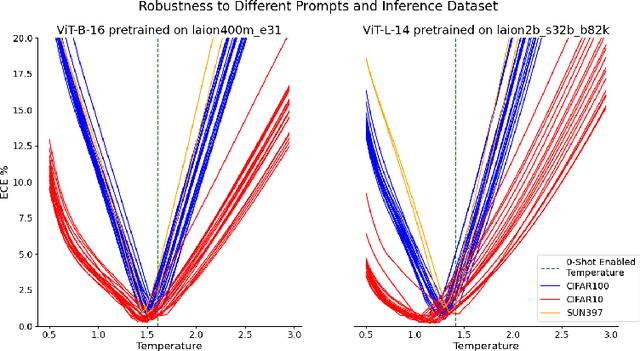
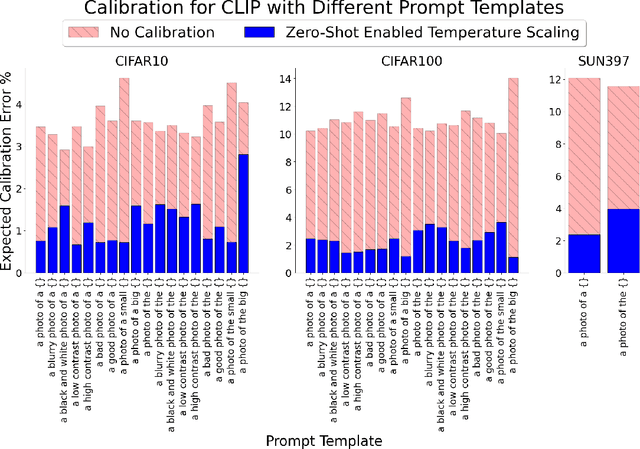
Calibration of deep learning models is crucial to their trustworthiness and safe usage, and as such, has been extensively studied in supervised classification models, with methods crafted to decrease miscalibration. However, there has yet to be a comprehensive study of the calibration of vision-language models that are used for zero-shot inference, like CLIP. We measure calibration across relevant variables like prompt, dataset, and architecture, and find that zero-shot inference with CLIP is miscalibrated. Furthermore, we propose a modified version of temperature scaling that is aligned with the common use cases of CLIP as a zero-shot inference model, and show that a single learned temperature generalizes for each specific CLIP model (defined by a chosen pre-training dataset and architecture) across inference dataset and prompt choice.