 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Trade offs When Conditioning Synthetic Data
Jul 03, 2025Learning robust object detectors from only a handful of images is a critical challenge in industrial vision systems, where collecting high quality training data can take months. Synthetic data has emerged as a key solution for data efficient visual inspection and pick and place robotics. Current pipelines rely on 3D engines such as Blender or Unreal, which offer fine control but still require weeks to render a small dataset, and the resulting images often suffer from a large gap between simulation and reality. Diffusion models promise a step change because they can generate high quality images in minutes, yet precise control, especially in low data regimes, remains difficult. Although many adapters now extend diffusion beyond plain text prompts, the effect of different conditioning schemes on synthetic data quality is poorly understood. We study eighty diverse visual concepts drawn from four standard object detection benchmarks and compare two conditioning strategies: prompt based and layout based. When the set of conditioning cues is narrow, prompt conditioning yields higher quality synthetic data; as diversity grows, layout conditioning becomes superior. When layout cues match the full training distribution, synthetic data raises mean average precision by an average of thirty four percent and by as much as one hundred seventy seven percent compared with using real data alone.
Out-of-Distribution Detection & Applications With Ablated Learned Temperature Energy
Jan 22, 2024As deep neural networks become adopted in high-stakes domains, it is crucial to be able to identify when inference inputs are Out-of-Distribution (OOD) so that users can be alerted of likely drops in performance and calibration despite high confidence. Among many others, existing methods use the following two scores to do so without training on any apriori OOD examples: a learned temperature and an energy score. In this paper we introduce Ablated Learned Temperature Energy (or "AbeT" for short), a method which combines these prior methods in novel ways with effective modifications. Due to these contributions, AbeT lowers the False Positive Rate at $95\%$ True Positive Rate (FPR@95) by $35.39\%$ in classification (averaged across all ID and OOD datasets measured) compared to state of the art without training networks in multiple stages or requiring hyperparameters or test-time backward passes. We additionally provide empirical insights as to how our model learns to distinguish between In-Distribution (ID) and OOD samples while only being explicitly trained on ID samples via exposure to misclassified ID examples at training time. Lastly, we show the efficacy of our method in identifying predicted bounding boxes and pixels corresponding to OOD objects in object detection and semantic segmentation, respectively - with an AUROC increase of $5.15\%$ in object detection and both a decrease in FPR@95 of $41.48\%$ and an increase in AUPRC of $34.20\%$ on average in semantic segmentation compared to previous state of the art.
Enabling Calibration In The Zero-Shot Inference of Large Vision-Language Models
Mar 11, 2023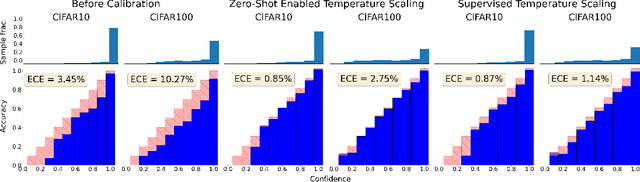
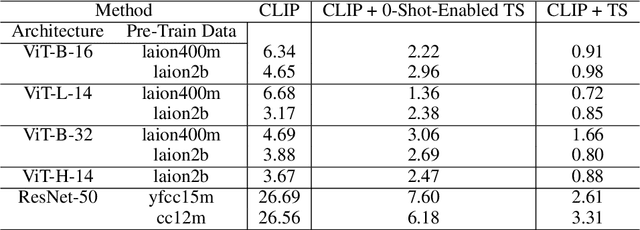
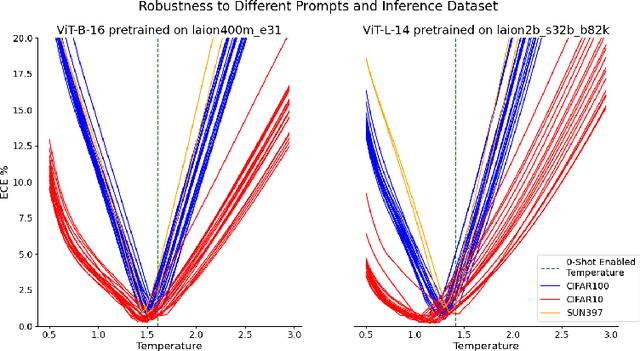
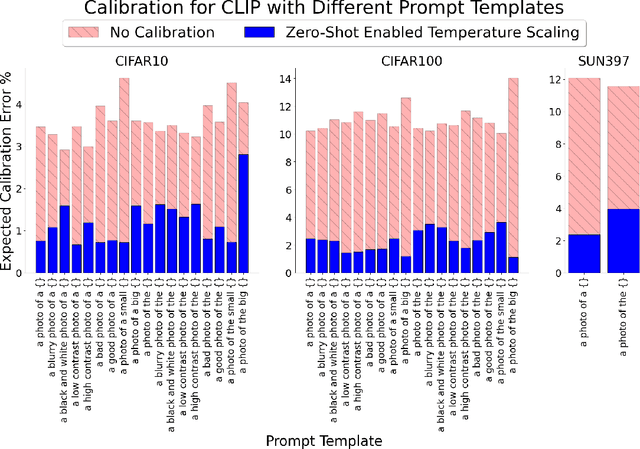
Calibration of deep learning models is crucial to their trustworthiness and safe usage, and as such, has been extensively studied in supervised classification models, with methods crafted to decrease miscalibration. However, there has yet to be a comprehensive study of the calibration of vision-language models that are used for zero-shot inference, like CLIP. We measure calibration across relevant variables like prompt, dataset, and architecture, and find that zero-shot inference with CLIP is miscalibrated. Furthermore, we propose a modified version of temperature scaling that is aligned with the common use cases of CLIP as a zero-shot inference model, and show that a single learned temperature generalizes for each specific CLIP model (defined by a chosen pre-training dataset and architecture) across inference dataset and prompt choice.