 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut-of-distribution and in-distribution posterior calibration using Kernel Density Polytopes
Paper and Code


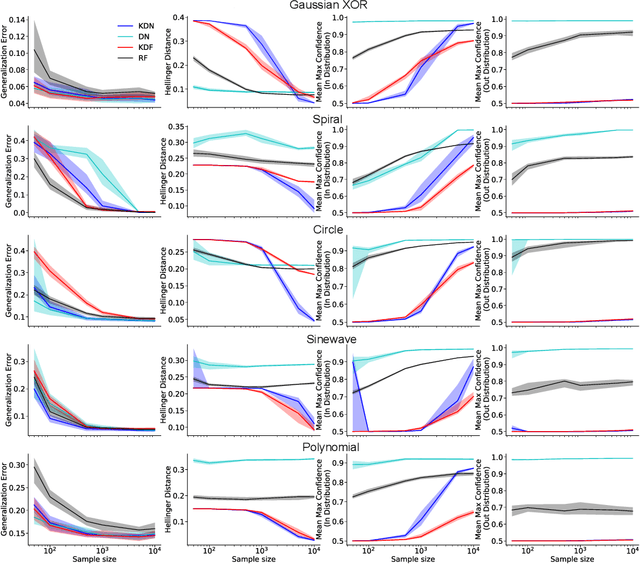
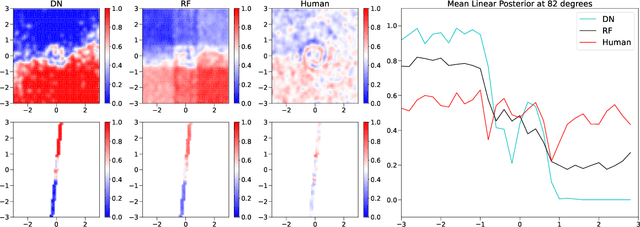
Any reasonable machine learning (ML) model should not only interpolate efficiently in between the training samples provided (in-distribution region), but also approach the extrapolative or out-of-distribution (OOD) region without being overconfident. Our experiment on human subjects justifies the aforementioned properties for human intelligence as well. Many state-of-the-art algorithms have tried to fix the overconfidence problem of ML models in the OOD region. However, in doing so, they have often impaired the in-distribution performance of the model. Our key insight is that ML models partition the feature space into polytopes and learn constant (random forests) or affine (ReLU networks) functions over those polytopes. This leads to the OOD overconfidence problem for the polytopes which lie in the training data boundary and extend to infinity. To resolve this issue, we propose kernel density methods that fit Gaussian kernel over the polytopes, which are learned using ML models. Specifically, we introduce two variants of kernel density polytopes: Kernel Density Forest (KDF) and Kernel Density Network (KDN) based on random forests and deep networks, respectively. Studies on various simulation settings show that both KDF and KDN achieve uniform confidence over the classes in the OOD region while maintaining good in-distribution accuracy compared to that of their respective parent models.