 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework to Map VMAF with the Probability of Just Noticeable Difference between Video Encoding Recipes
May 20, 2022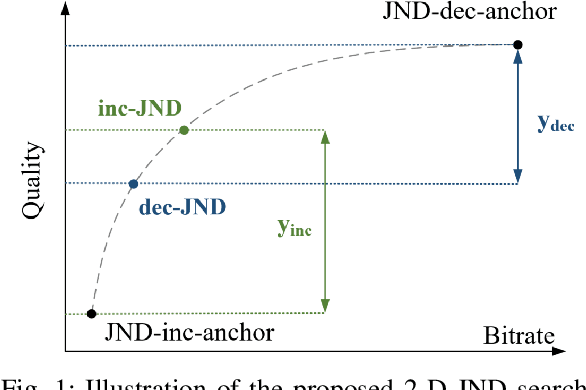
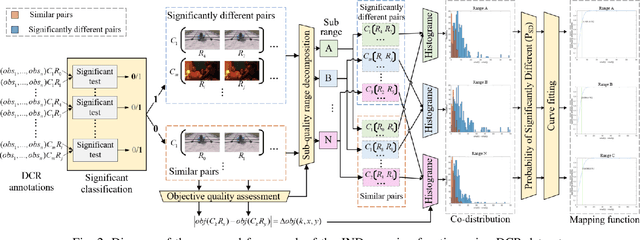
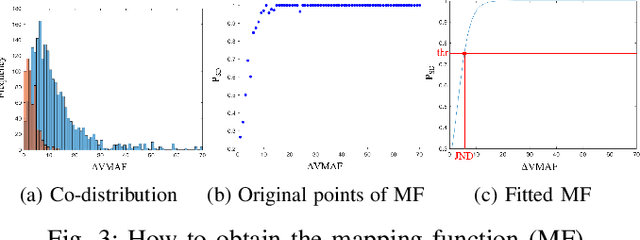
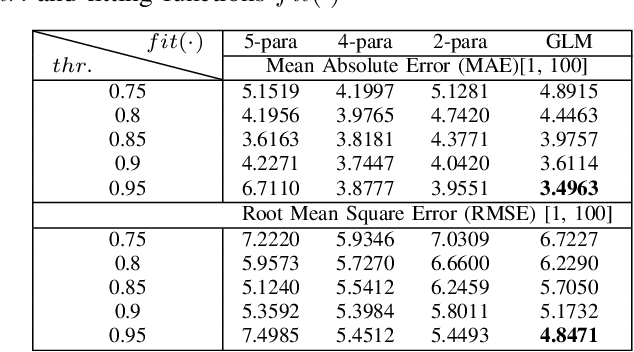
Just Noticeable Difference (JND) model developed based on Human Vision System (HVS) through subjective studies is valuable for many multimedia use cases. In the streaming industries, it is commonly applied to reach a good balance between compression efficiency and perceptual quality when selecting video encoding recipes. Nevertheless, recent state-of-the-art deep learning based JND prediction model relies on large-scale JND ground truth that is expensive and time consuming to collect. Most of the existing JND datasets contain limited number of contents and are limited to a certain codec (e.g., H264). As a result, JND prediction models that were trained on such datasets are normally not agnostic to the codecs. To this end, in order to decouple encoding recipes and JND estimation, we propose a novel framework to map the difference of objective Video Quality Assessment (VQA) scores, i.e., VMAF, between two given videos encoded with different encoding recipes from the same content to the probability of having just noticeable difference between them. The proposed probability mapping model learns from DCR test data, which is significantly cheaper compared to standard JND subjective test. As we utilize objective VQA metric (e.g., VMAF that trained with contents encoded with different codecs) as proxy to estimate JND, our model is agnostic to codecs and computationally efficient. Throughout extensive experiments, it is demonstrated that the proposed model is able to estimate JND values efficiently.
Considering user agreement in learning to predict the aesthetic quality
Oct 13, 2021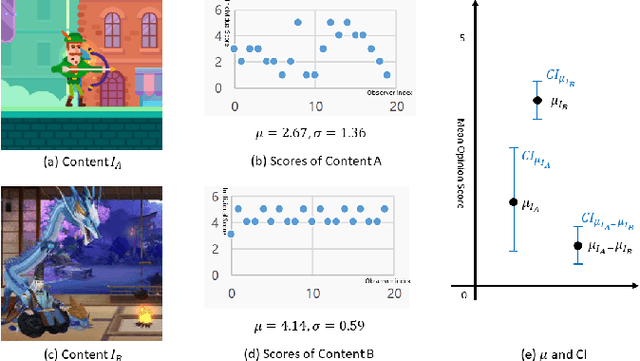

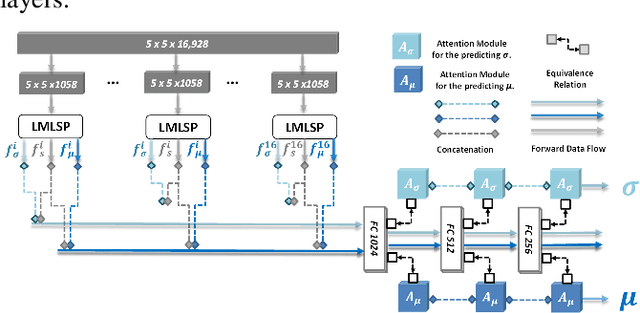
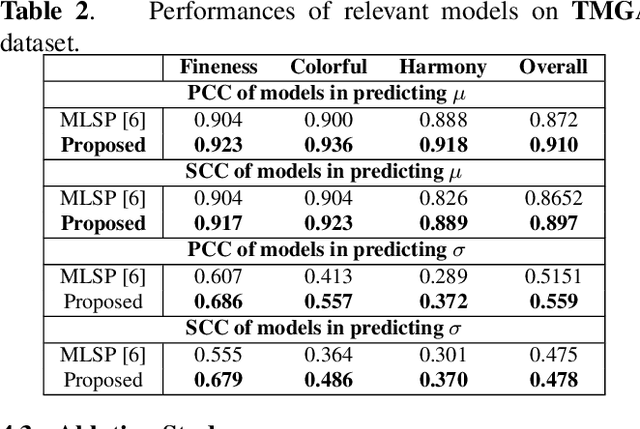
How to robustly rank the aesthetic quality of given images has been a long-standing ill-posed topic. Such challenge stems mainly from the diverse subjective opinions of different observers about the varied types of content. There is a growing interest in estimating the user agreement by considering the standard deviation of the scores, instead of only predicting the mean aesthetic opinion score. Nevertheless, when comparing a pair of contents, few studies consider how confident are we regarding the difference in the aesthetic scores. In this paper, we thus propose (1) a re-adapted multi-task attention network to predict both the mean opinion score and the standard deviation in an end-to-end manner; (2) a brand-new confidence interval ranking loss that encourages the model to focus on image-pairs that are less certain about the difference of their aesthetic scores. With such loss, the model is encouraged to learn the uncertainty of the content that is relevant to the diversity of observers' opinions, i.e., user disagreement. Extensive experiments have demonstrated that the proposed multi-task aesthetic model achieves state-of-the-art performance on two different types of aesthetic datasets, i.e., AVA and TMGA.
Improve the Interpretability of Attention: A Fast, Accurate, and Interpretable High-Resolution Attention Model
Jun 07, 2021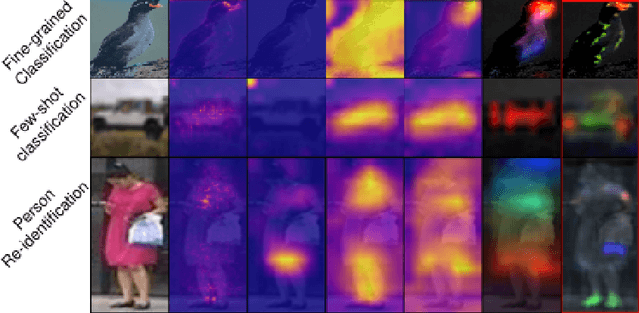

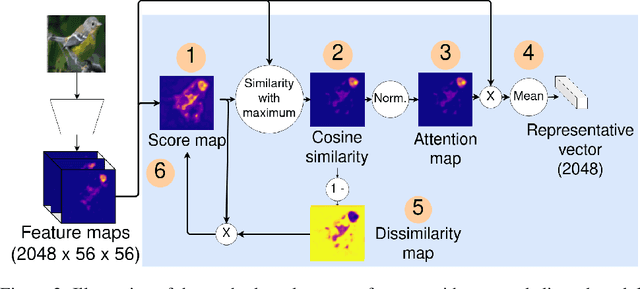
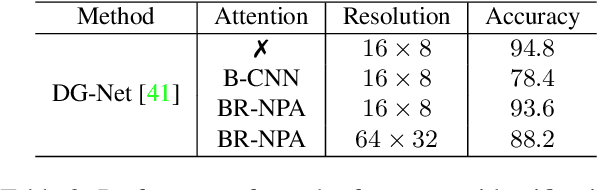
The prevalence of employing attention mechanisms has brought along concerns on the interpretability of attention distributions. Although it provides insights about how a model is operating, utilizing attention as the explanation of model predictions is still highly dubious. The community is still seeking more interpretable strategies for better identifying local active regions that contribute the most to the final decision. To improve the interpretability of existing attention models, we propose a novel Bilinear Representative Non-Parametric Attention (BR-NPA) strategy that captures the task-relevant human-interpretable information. The target model is first distilled to have higher-resolution intermediate feature maps. From which, representative features are then grouped based on local pairwise feature similarity, to produce finer-grained, more precise attention maps highlighting task-relevant parts of the input. The obtained attention maps are ranked according to the `active level' of the compound feature, which provides information regarding the important level of the highlighted regions. The proposed model can be easily adapted in a wide variety of modern deep models, where classification is involved. It is also more accurate, faster, and with a smaller memory footprint than usual neural attention modules. Extensive experiments showcase more comprehensive visual explanations compared to the state-of-the-art visualization model across multiple tasks including few-shot classification, person re-identification, fine-grained image classification. The proposed visualization model sheds imperative light on how neural networks `pay their attention' differently in different tasks.
Seeing by haptic glance: reinforcement learning-based 3D object Recognition
Feb 15, 2021
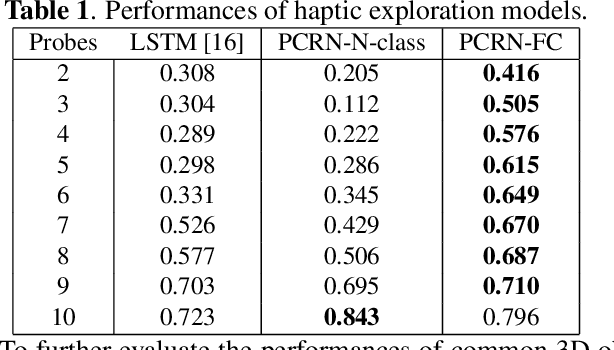
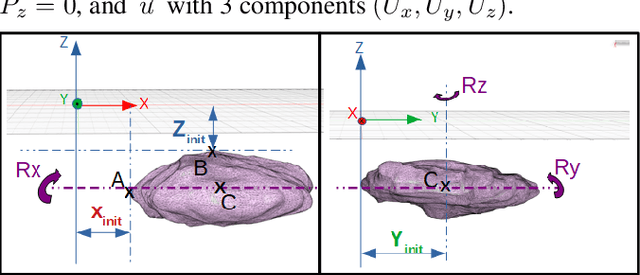
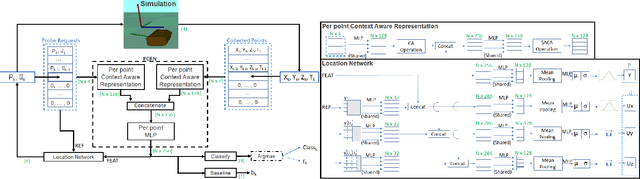
Human is able to conduct 3D recognition by a limited number of haptic contacts between the target object and his/her fingers without seeing the object. This capability is defined as `haptic glance' in cognitive neuroscience. Most of the existing 3D recognition models were developed based on dense 3D data. Nonetheless, in many real-life use cases, where robots are used to collect 3D data by haptic exploration, only a limited number of 3D points could be collected. In this study, we thus focus on solving the intractable problem of how to obtain cognitively representative 3D key-points of a target object with limited interactions between the robot and the object. A novel reinforcement learning based framework is proposed, where the haptic exploration procedure (the agent iteratively predicts the next position for the robot to explore) is optimized simultaneously with the objective 3D recognition with actively collected 3D points. As the model is rewarded only when the 3D object is accurately recognized, it is driven to find the sparse yet efficient haptic-perceptual 3D representation of the object. Experimental results show that our proposed model outperforms the state of the art models.
Multi-Modal Aesthetic Assessment for MObile Gaming Image
Jan 27, 2021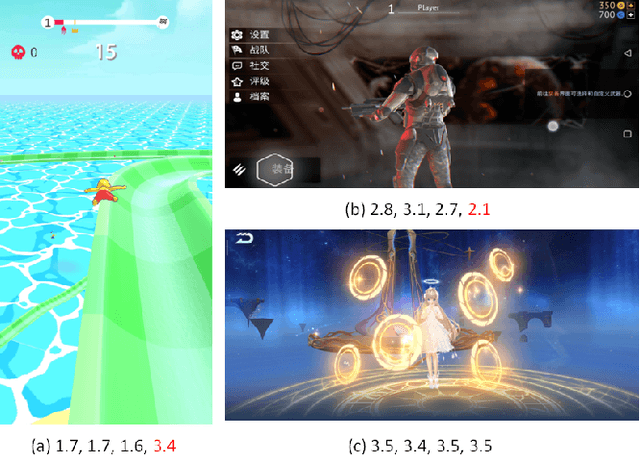
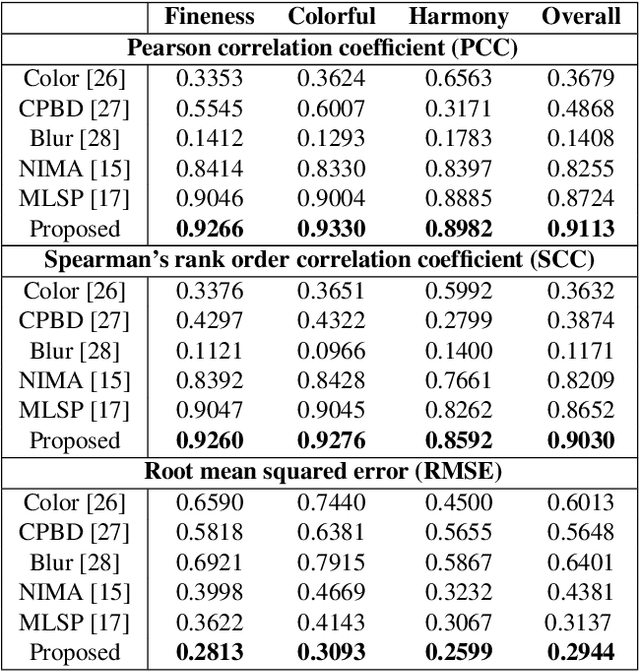
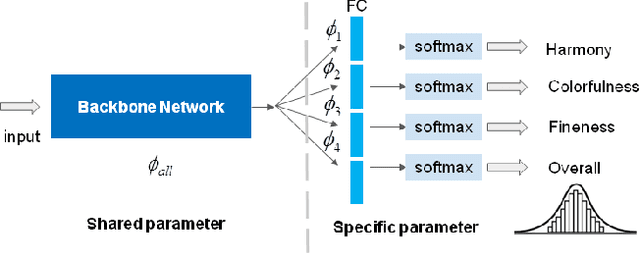
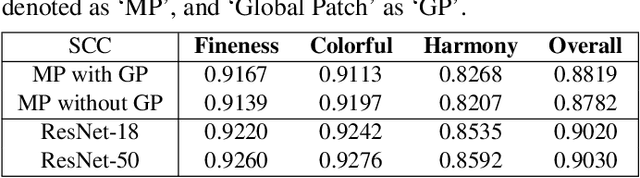
With the proliferation of various gaming technology, services, game styles, and platforms, multi-dimensional aesthetic assessment of the gaming contents is becoming more and more important for the gaming industry. Depending on the diverse needs of diversified game players, game designers, graphical developers, etc. in particular conditions, multi-modal aesthetic assessment is required to consider different aesthetic dimensions/perspectives. Since there are different underlying relationships between different aesthetic dimensions, e.g., between the `Colorfulness' and `Color Harmony', it could be advantageous to leverage effective information attached in multiple relevant dimensions. To this end, we solve this problem via multi-task learning. Our inclination is to seek and learn the correlations between different aesthetic relevant dimensions to further boost the generalization performance in predicting all the aesthetic dimensions. Therefore, the `bottleneck' of obtaining good predictions with limited labeled data for one individual dimension could be unplugged by harnessing complementary sources of other dimensions, i.e., augment the training data indirectly by sharing training information across dimensions. According to experimental results, the proposed model outperforms state-of-the-art aesthetic metrics significantly in predicting four gaming aesthetic dimensions.
Few-Shot Object Detection in Real Life: Case Study on Auto-Harvest
Nov 05, 2020


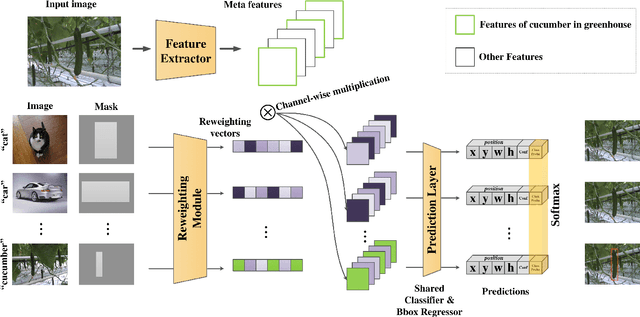
Confinement during COVID-19 has caused serious effects on agriculture all over the world. As one of the efficient solutions, mechanical harvest/auto-harvest that is based on object detection and robotic harvester becomes an urgent need. Within the auto-harvest system, robust few-shot object detection model is one of the bottlenecks, since the system is required to deal with new vegetable/fruit categories and the collection of large-scale annotated datasets for all the novel categories is expensive. There are many few-shot object detection models that were developed by the community. Yet whether they could be employed directly for real life agricultural applications is still questionable, as there is a context-gap between the commonly used training datasets and the images collected in real life agricultural scenarios. To this end, in this study, we present a novel cucumber dataset and propose two data augmentation strategies that help to bridge the context-gap. Experimental results show that 1) the state-of-the-art few-shot object detection model performs poorly on the novel `cucumber' category; and 2) the proposed augmentation strategies outperform the commonly used ones.
Strategy for Boosting Pair Comparison and Improving Quality Assessment Accuracy
Oct 01, 2020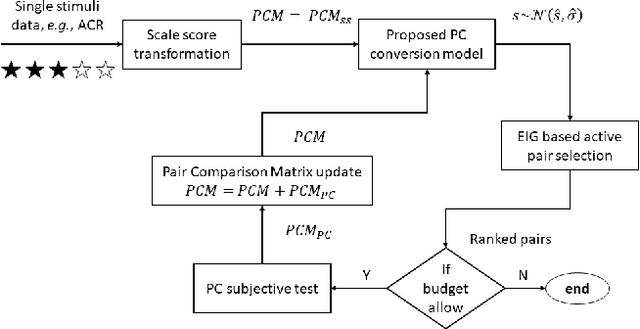
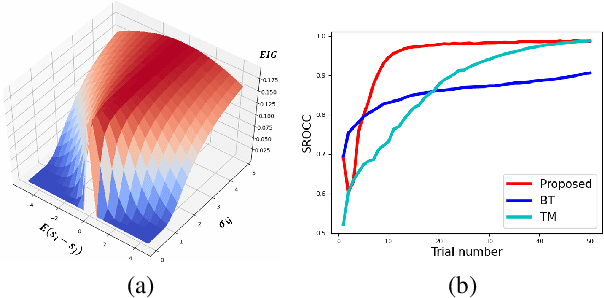
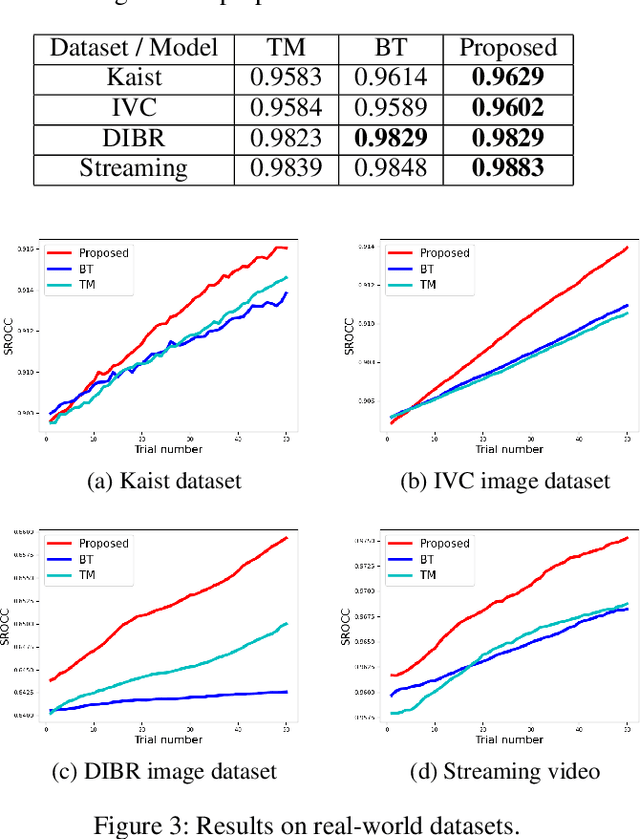
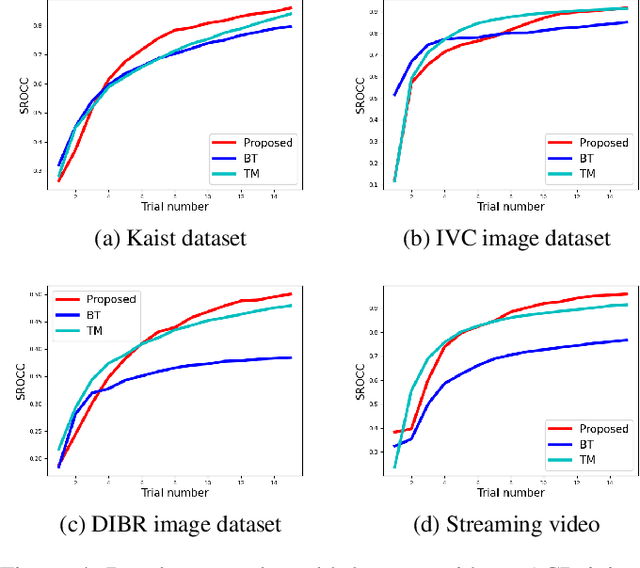
The development of rigorous quality assessment model relies on the collection of reliable subjective data, where the perceived quality of visual multimedia is rated by the human observers. Different subjective assessment protocols can be used according to the objectives, which determine the discriminability and accuracy of the subjective data. Single stimulus methodology, e.g., the Absolute Category Rating (ACR) has been widely adopted due to its simplicity and efficiency. However, Pair Comparison (PC) is of significant advantage over ACR in terms of discriminability. In addition, PC avoids the influence of observers' bias regarding their understanding of the quality scale. Nevertheless, full pair comparison is much more time-consuming. In this study, we therefore 1) employ a generic model to bridge the pair comparison data and ACR data, where the variance term could be recovered and the obtained information is more complete; 2) propose a fusion strategy to boost pair comparisons by utilizing the ACR results as initialization information; 3) develop a novel active batch sampling strategy based on Minimum Spanning Tree (MST) for PC. In such a way, the proposed methodology could achieve the same accuracy of pair comparison but with the compelxity as low as ACR. Extensive experimental results demonstrate the efficiency and accuracy of the proposed approach, which outperforms the state of the art approaches.
GPM: A Generic Probabilistic Model to Recover Annotator's Behavior and Ground Truth Labeling
Mar 01, 2020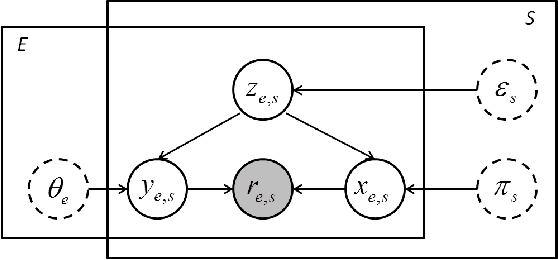
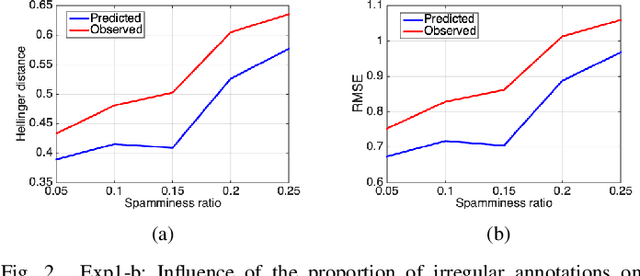
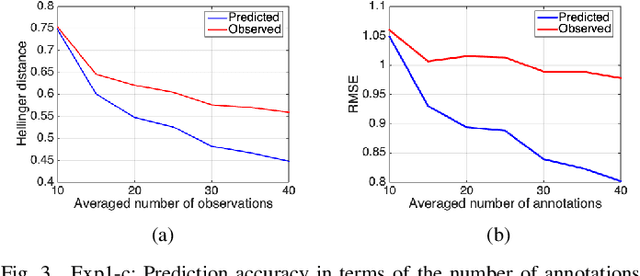

In the big data era, data labeling can be obtained through crowdsourcing. Nevertheless, the obtained labels are generally noisy, unreliable or even adversarial. In this paper, we propose a probabilistic graphical annotation model to infer the underlying ground truth and annotator's behavior. To accommodate both discrete and continuous application scenarios (e.g., classifying scenes vs. rating videos on a Likert scale), the underlying ground truth is considered following a distribution rather than a single value. In this way, the reliable but potentially divergent opinions from "good" annotators can be recovered. The proposed model is able to identify whether an annotator has worked diligently towards the task during the labeling procedure, which could be used for further selection of qualified annotators. Our model has been tested on both simulated data and real-world data, where it always shows superior performance than the other state-of-the-art models in terms of accuracy and robustness.
A New Ensemble Adversarial Attack Powered by Long-term Gradient Memories
Nov 18, 2019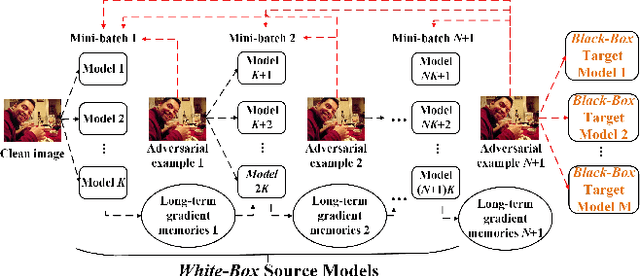
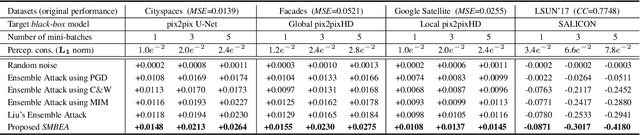

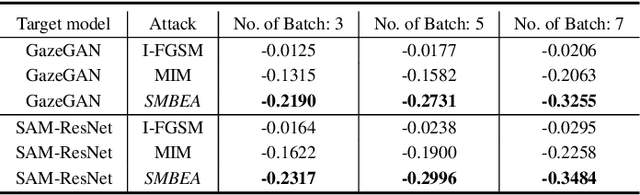
Deep neural networks are vulnerable to adversarial attacks.
Adversarial Attacks against Deep Saliency Models
Apr 02, 2019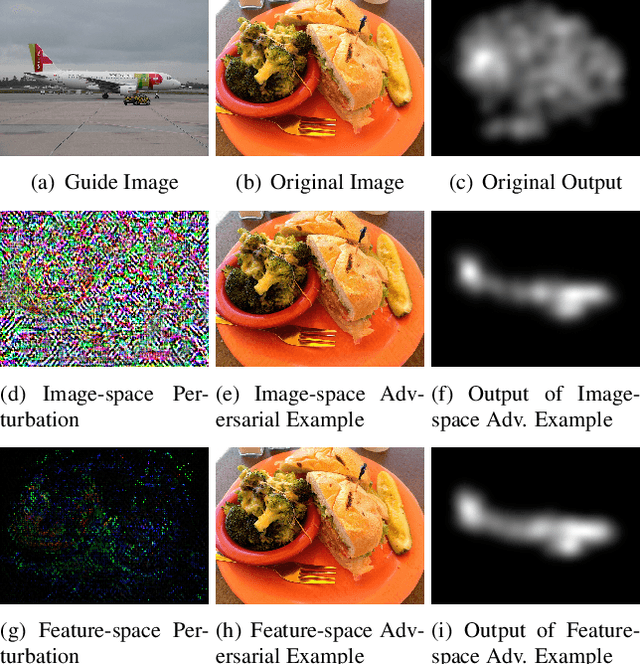


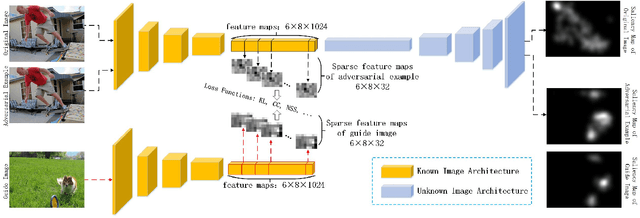
Currently, a plethora of saliency models based on deep neural networks have led great breakthroughs in many complex high-level vision tasks (e.g. scene description, object detection). The robustness of these models, however, has not yet been studied. In this paper, we propose a sparse feature-space adversarial attack method against deep saliency models for the first time. The proposed attack only requires a part of the model information, and is able to generate a sparser and more insidious adversarial perturbation, compared to traditional image-space attacks. These adversarial perturbations are so subtle that a human observer cannot notice their presences, but the model outputs will be revolutionized. This phenomenon raises security threats to deep saliency models in practical applications. We also explore some intriguing properties of the feature-space attack, e.g. 1) the hidden layers with bigger receptive fields generate sparser perturbations, 2) the deeper hidden layers achieve higher attack success rates, and 3) different loss functions and different attacked layers will result in diverse perturbations. Experiments indicate that the proposed method is able to successfully attack different model architectures across various image scenes.