 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPM: A Generic Probabilistic Model to Recover Annotator's Behavior and Ground Truth Labeling
Paper and Code
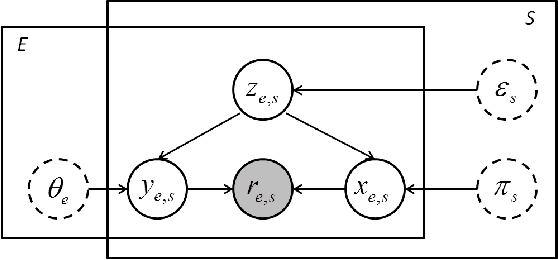
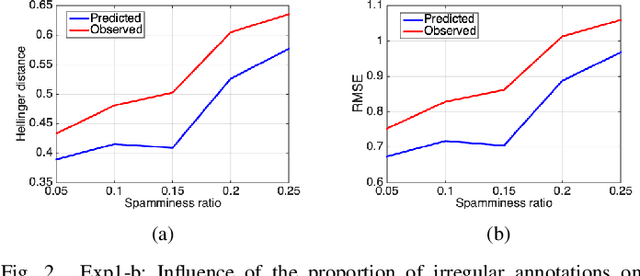
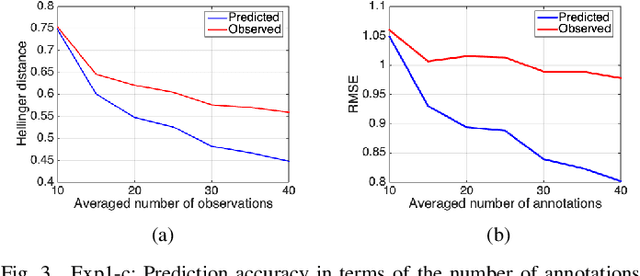

In the big data era, data labeling can be obtained through crowdsourcing. Nevertheless, the obtained labels are generally noisy, unreliable or even adversarial. In this paper, we propose a probabilistic graphical annotation model to infer the underlying ground truth and annotator's behavior. To accommodate both discrete and continuous application scenarios (e.g., classifying scenes vs. rating videos on a Likert scale), the underlying ground truth is considered following a distribution rather than a single value. In this way, the reliable but potentially divergent opinions from "good" annotators can be recovered. The proposed model is able to identify whether an annotator has worked diligently towards the task during the labeling procedure, which could be used for further selection of qualified annotators. Our model has been tested on both simulated data and real-world data, where it always shows superior performance than the other state-of-the-art models in terms of accuracy and robustness.