 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Conditioned Probabilistic Learning of Video Rescaling
Aug 18, 2021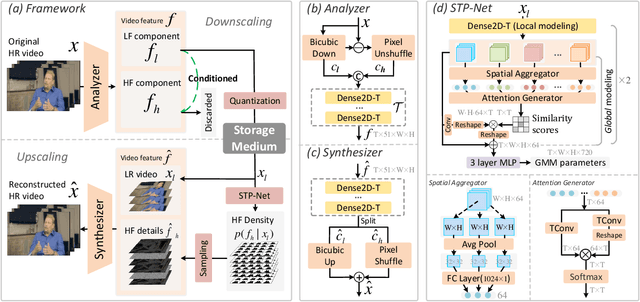
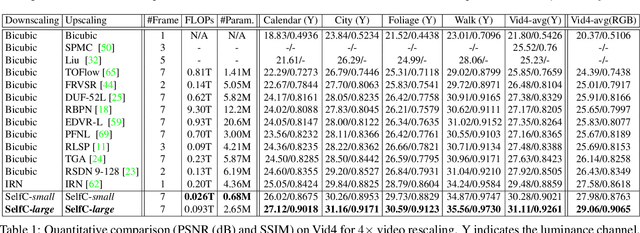
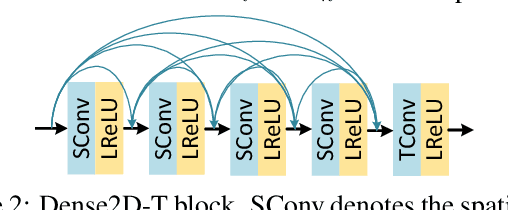

Bicubic downscaling is a prevalent technique used to reduce the video storage burden or to accelerate the downstream processing speed. However, the inverse upscaling step is non-trivial, and the downscaled video may also deteriorate the performance of downstream tasks. In this paper, we propose a self-conditioned probabilistic framework for video rescaling to learn the paired downscaling and upscaling procedures simultaneously. During the training, we decrease the entropy of the information lost in the downscaling by maximizing its probability conditioned on the strong spatial-temporal prior information within the downscaled video. After optimization, the downscaled video by our framework preserves more meaningful information, which is beneficial for both the upscaling step and the downstream tasks, e.g., video action recognition task. We further extend the framework to a lossy video compression system, in which a gradient estimator for non-differential industrial lossy codecs is proposed for the end-to-end training of the whole system. Extensive experimental results demonstrate the superiority of our approach on video rescaling, video compression, and efficient action recognition tasks.
A New Ensemble Adversarial Attack Powered by Long-term Gradient Memories
Nov 18, 2019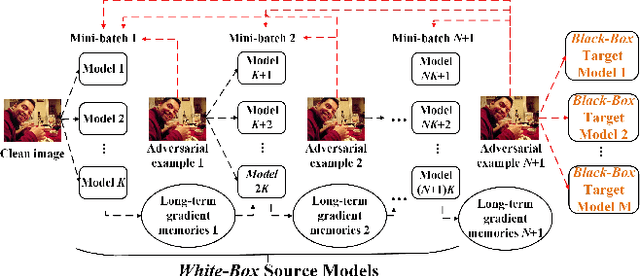
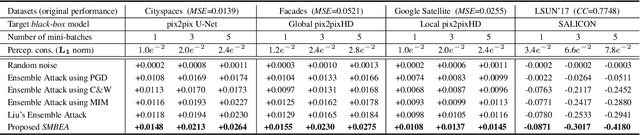

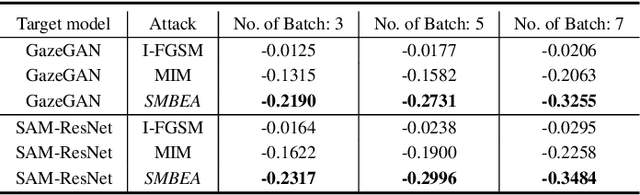
Deep neural networks are vulnerable to adversarial attacks.
GazeGAN: A Generative Adversarial Saliency Model based on Invariance Analysis of Human Gaze During Scene Free Viewing
May 25, 2019



Data size is the bottleneck for developing deep saliency models, because collecting eye-movement data is very time consuming and expensive. Most of current studies on human attention and saliency modeling have used high quality stereotype stimuli. In real world, however, captured images undergo various types of transformations. Can we use these transformations to augment existing saliency datasets? Here, we first create a novel saliency dataset including fixations of 10 observers over 1900 images degraded by 19 types of transformations. Second, by analyzing eye movements, we find that observers look at different locations over transformed versus original images. Third, we utilize the new data over transformed images, called data augmentation transformation (DAT), to train deep saliency models. We find that label preserving DATs with negligible impact on human gaze boost saliency prediction, whereas some other DATs that severely impact human gaze degrade the performance. These label preserving valid augmentation transformations provide a solution to enlarge existing saliency datasets. Finally, we introduce a novel saliency model based on generative adversarial network (dubbed GazeGAN). A modified UNet is proposed as the generator of the GazeGAN, which combines classic skip connections with a novel center-surround connection (CSC), in order to leverage multi level features. We also propose a histogram loss based on Alternative Chi Square Distance (ACS HistLoss) to refine the saliency map in terms of luminance distribution. Extensive experiments and comparisons over 3 datasets indicate that GazeGAN achieves the best performance in terms of popular saliency evaluation metrics, and is more robust to various perturbations. Our code and data are available at: https://github.com/CZHQuality/Sal-CFS-GAN.
Adversarial Attacks against Deep Saliency Models
Apr 02, 2019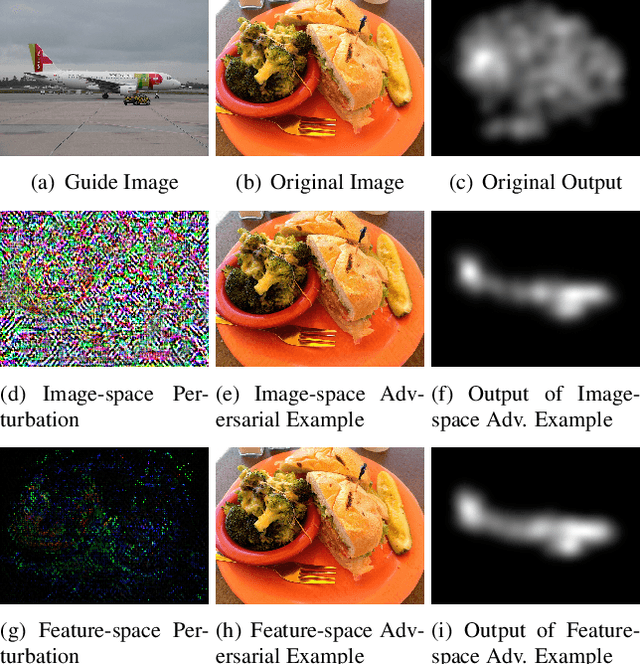


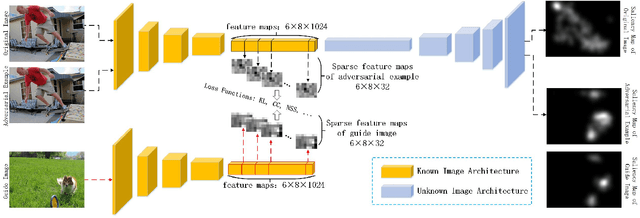
Currently, a plethora of saliency models based on deep neural networks have led great breakthroughs in many complex high-level vision tasks (e.g. scene description, object detection). The robustness of these models, however, has not yet been studied. In this paper, we propose a sparse feature-space adversarial attack method against deep saliency models for the first time. The proposed attack only requires a part of the model information, and is able to generate a sparser and more insidious adversarial perturbation, compared to traditional image-space attacks. These adversarial perturbations are so subtle that a human observer cannot notice their presences, but the model outputs will be revolutionized. This phenomenon raises security threats to deep saliency models in practical applications. We also explore some intriguing properties of the feature-space attack, e.g. 1) the hidden layers with bigger receptive fields generate sparser perturbations, 2) the deeper hidden layers achieve higher attack success rates, and 3) different loss functions and different attacked layers will result in diverse perturbations. Experiments indicate that the proposed method is able to successfully attack different model architectures across various image scenes.
Invariance Analysis of Saliency Models versus Human Gaze During Scene Free Viewing
Oct 10, 2018



Most of current studies on human gaze and saliency modeling have used high-quality stimuli. In real world, however, captured images undergo various types of distortions during the whole acquisition, transmission, and displaying chain. Some distortion types include motion blur, lighting variations and rotation. Despite few efforts, influences of ubiquitous distortions on visual attention and saliency models have not been systematically investigated. In this paper, we first create a large-scale database including eye movements of 10 observers over 1900 images degraded by 19 types of distortions. Second, by analyzing eye movements and saliency models, we find that: a) observers look at different locations over distorted versus original images, and b) performances of saliency models are drastically hindered over distorted images, with the maximum performance drop belonging to Rotation and Shearing distortions. Finally, we investigate the effectiveness of different distortions when serving as data augmentation transformations. Experimental results verify that some useful data augmentation transformations which preserve human gaze of reference images can improve deep saliency models against distortions, while some invalid transformations which severely change human gaze will degrade the performance.