 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsidering user agreement in learning to predict the aesthetic quality
Oct 13, 2021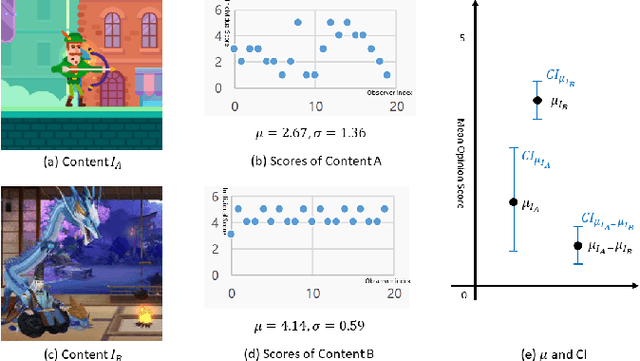

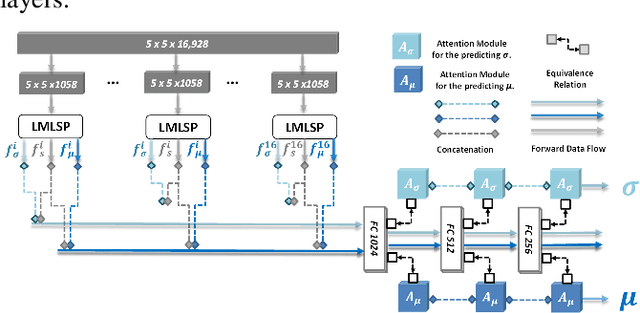
How to robustly rank the aesthetic quality of given images has been a long-standing ill-posed topic. Such challenge stems mainly from the diverse subjective opinions of different observers about the varied types of content. There is a growing interest in estimating the user agreement by considering the standard deviation of the scores, instead of only predicting the mean aesthetic opinion score. Nevertheless, when comparing a pair of contents, few studies consider how confident are we regarding the difference in the aesthetic scores. In this paper, we thus propose (1) a re-adapted multi-task attention network to predict both the mean opinion score and the standard deviation in an end-to-end manner; (2) a brand-new confidence interval ranking loss that encourages the model to focus on image-pairs that are less certain about the difference of their aesthetic scores. With such loss, the model is encouraged to learn the uncertainty of the content that is relevant to the diversity of observers' opinions, i.e., user disagreement. Extensive experiments have demonstrated that the proposed multi-task aesthetic model achieves state-of-the-art performance on two different types of aesthetic datasets, i.e., AVA and TMGA.
Multi-Modal Aesthetic Assessment for MObile Gaming Image
Jan 27, 2021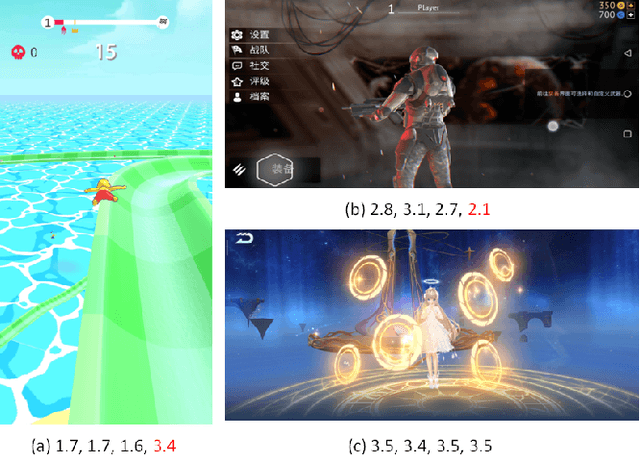
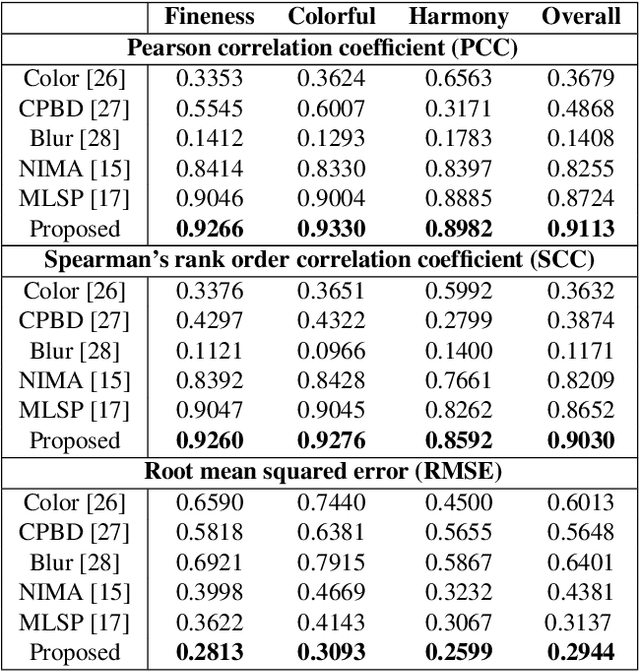
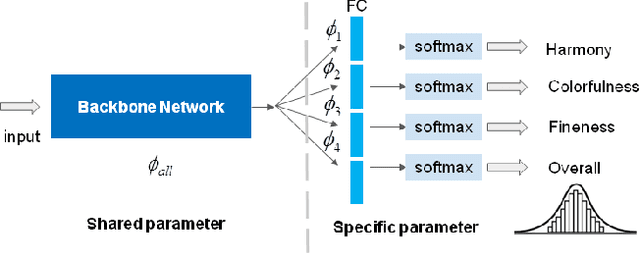
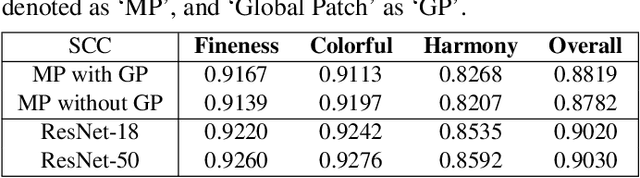
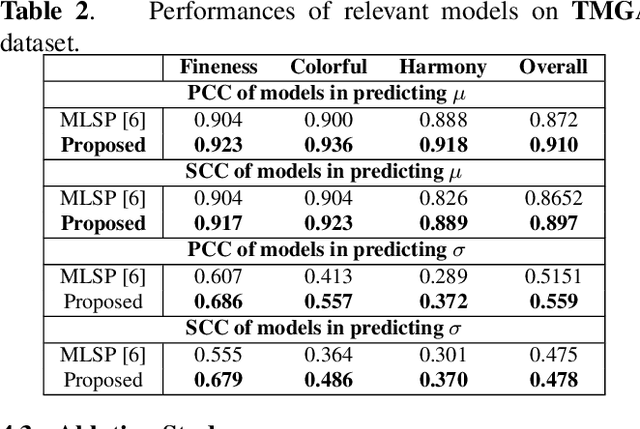
With the proliferation of various gaming technology, services, game styles, and platforms, multi-dimensional aesthetic assessment of the gaming contents is becoming more and more important for the gaming industry. Depending on the diverse needs of diversified game players, game designers, graphical developers, etc. in particular conditions, multi-modal aesthetic assessment is required to consider different aesthetic dimensions/perspectives. Since there are different underlying relationships between different aesthetic dimensions, e.g., between the `Colorfulness' and `Color Harmony', it could be advantageous to leverage effective information attached in multiple relevant dimensions. To this end, we solve this problem via multi-task learning. Our inclination is to seek and learn the correlations between different aesthetic relevant dimensions to further boost the generalization performance in predicting all the aesthetic dimensions. Therefore, the `bottleneck' of obtaining good predictions with limited labeled data for one individual dimension could be unplugged by harnessing complementary sources of other dimensions, i.e., augment the training data indirectly by sharing training information across dimensions. According to experimental results, the proposed model outperforms state-of-the-art aesthetic metrics significantly in predicting four gaming aesthetic dimensions.