 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework to Map VMAF with the Probability of Just Noticeable Difference between Video Encoding Recipes
Paper and Code
May 20, 2022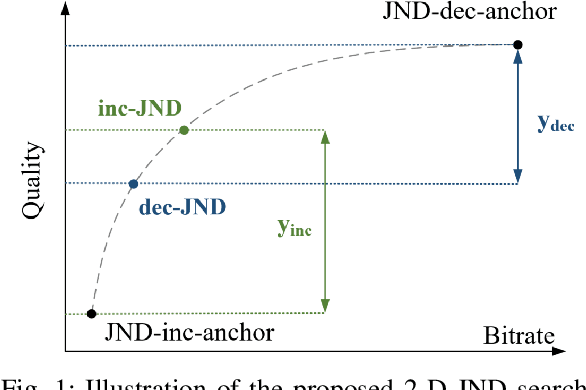
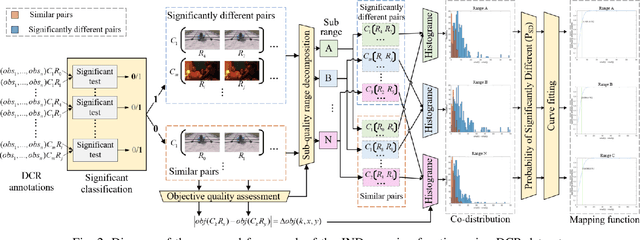
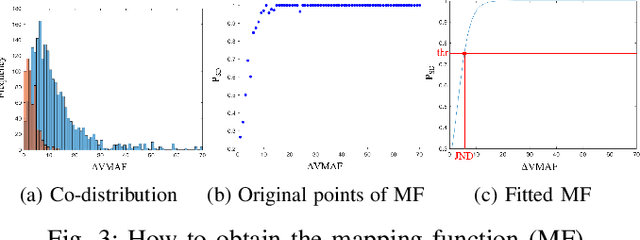
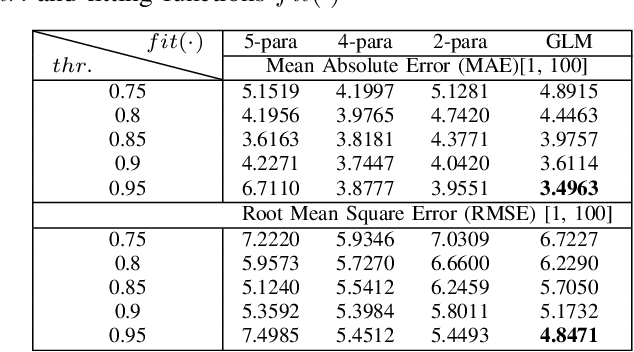
Just Noticeable Difference (JND) model developed based on Human Vision System (HVS) through subjective studies is valuable for many multimedia use cases. In the streaming industries, it is commonly applied to reach a good balance between compression efficiency and perceptual quality when selecting video encoding recipes. Nevertheless, recent state-of-the-art deep learning based JND prediction model relies on large-scale JND ground truth that is expensive and time consuming to collect. Most of the existing JND datasets contain limited number of contents and are limited to a certain codec (e.g., H264). As a result, JND prediction models that were trained on such datasets are normally not agnostic to the codecs. To this end, in order to decouple encoding recipes and JND estimation, we propose a novel framework to map the difference of objective Video Quality Assessment (VQA) scores, i.e., VMAF, between two given videos encoded with different encoding recipes from the same content to the probability of having just noticeable difference between them. The proposed probability mapping model learns from DCR test data, which is significantly cheaper compared to standard JND subjective test. As we utilize objective VQA metric (e.g., VMAF that trained with contents encoded with different codecs) as proxy to estimate JND, our model is agnostic to codecs and computationally efficient. Throughout extensive experiments, it is demonstrated that the proposed model is able to estimate JND values efficiently.