 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Defense by Restricting the Hidden Space of Deep Neural Networks
Paper and Code
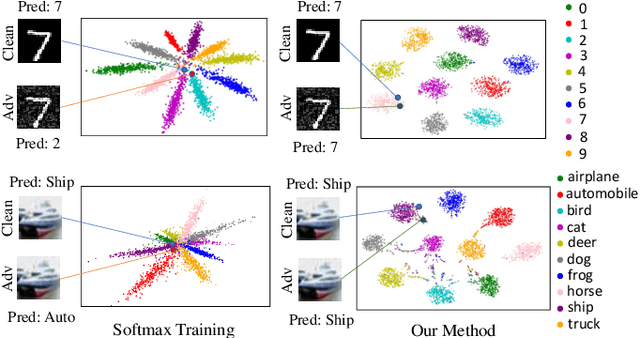
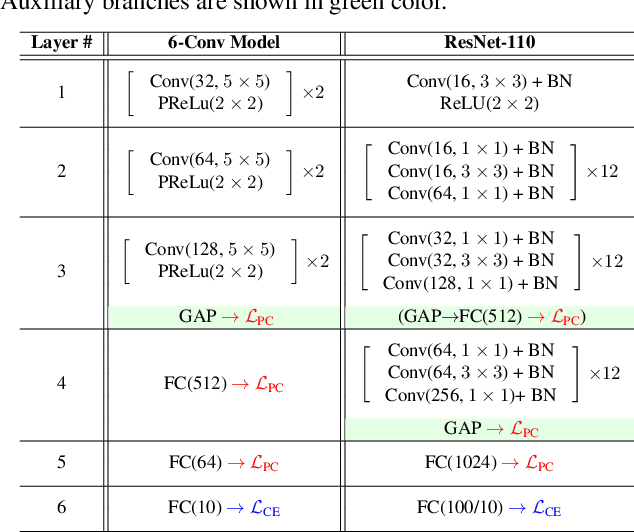
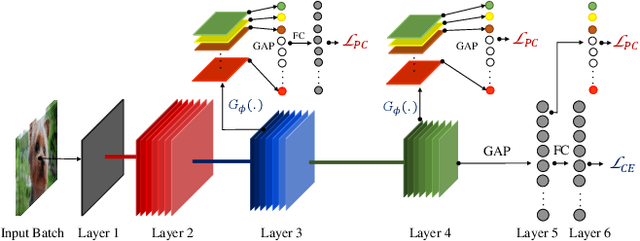
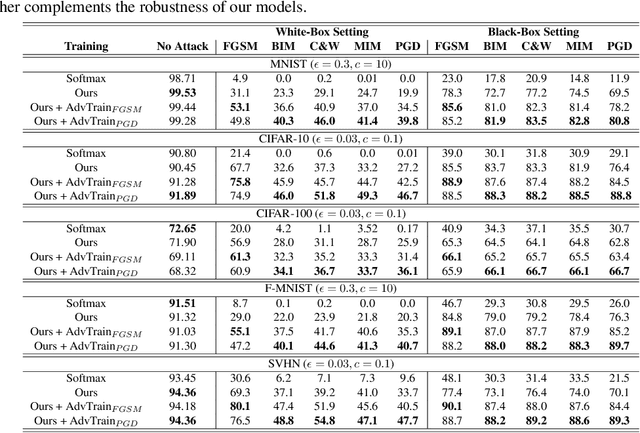
Deep neural networks are vulnerable to adversarial attacks, which can fool them by adding minuscule perturbations to the input images. The robustness of existing defenses suffers greatly under white-box attack settings, where an adversary has full knowledge about the network and can iterate several times to find strong perturbations. We observe that the main reason for the existence of such perturbations is the close proximity of different class samples in the learned feature space. This allows model decisions to be totally changed by adding an imperceptible perturbation in the inputs. To counter this, we propose to class-wise disentangle the intermediate feature representations of deep networks. Specifically, we force the features for each class to lie inside a convex polytope that is maximally separated from the polytopes of other classes. In this manner, the network is forced to learn distinct and distant decision regions for each class. We observe that this simple constraint on the features greatly enhances the robustness of learned models, even against the strongest white-box attacks, without degrading the classification performance on clean images. We report extensive evaluations in both black-box and white-box attack scenarios and show significant gains in comparison to state-of-the art defenses.