 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
Learning What Matters: Adaptive Information-Theoretic Objectives for Robot Exploration
May 12, 2026Designing learnable information-theoretic objectives for robot exploration remains challenging. Such objectives aim to guide exploration toward data that reduces uncertainty in model parameters, yet it is often unclear what information the collected data can actually reveal. Although reinforcement learning (RL) can optimize a given objective, constructing objectives that reflect parametric learnability is difficult in high-dimensional robotic systems. Many parameter directions are weakly observable or unidentifiable, and even when identifiable directions are selected, omitted directions can still influence exploration and distort information measures. To address this challenge, we propose Quasi-Optimal Experimental Design (Q{\footnotesize OED}), an adaptive information objective grounded in optimal experimental design. Q{\footnotesize OED} (i) performs eigenspace analysis of the Fisher information matrix to identify an observable subspace and select identifiable parameter directions, and (ii) modifies the exploration objective to emphasize these directions while suppressing nuisance effects from non-critical parameters. Under bounded nuisance influence and limited coupling between critical and nuisance directions, Q{\footnotesize OED} provides a constant-factor approximation to the ideal information objective that explores all parameters. We evaluate Q{\footnotesize OED} on simulated and real-world navigation and manipulation tasks, where identifiable-direction selection and nuisance suppression yield performance improvements of \SI{35.23}{\percent} and \SI{21.98}{\percent}, respectively. When integrated as an exploration objective in model-based policy optimization, Q{\footnotesize OED} further improves policy performance over established RL baselines.
DiffHDR: Re-Exposing LDR Videos with Video Diffusion Models
Apr 07, 2026Most digital videos are stored in 8-bit low dynamic range (LDR) formats, where much of the original high dynamic range (HDR) scene radiance is lost due to saturation and quantization. This loss of highlight and shadow detail precludes mapping accurate luminance to HDR displays and limits meaningful re-exposure in post-production workflows. Although techniques have been proposed to convert LDR images to HDR through dynamic range expansion, they struggle to restore realistic detail in the over- and underexposed regions. To address this, we present DiffHDR, a framework that formulates LDR-to-HDR conversion as a generative radiance inpainting task within the latent space of a video diffusion model. By operating in Log-Gamma color space, DiffHDR leverages spatio-temporal generative priors from a pretrained video diffusion model to synthesize plausible HDR radiance in over- and underexposed regions while recovering the continuous scene radiance of the quantized pixels. Our framework further enables controllable LDR-to-HDR video conversion guided by text prompts or reference images. To address the scarcity of paired HDR video data, we develop a pipeline that synthesizes high-quality HDR video training data from static HDRI maps. Extensive experiments demonstrate that DiffHDR significantly outperforms state-of-the-art approaches in radiance fidelity and temporal stability, producing realistic HDR videos with considerable latitude for re-exposure.
UniRecGen: Unifying Multi-View 3D Reconstruction and Generation
Apr 01, 2026Sparse-view 3D modeling represents a fundamental tension between reconstruction fidelity and generative plausibility. While feed-forward reconstruction excels in efficiency and input alignment, it often lacks the global priors needed for structural completeness. Conversely, diffusion-based generation provides rich geometric details but struggles with multi-view consistency. We present UniRecGen, a unified framework that integrates these two paradigms into a single cooperative system. To overcome inherent conflicts in coordinate spaces, 3D representations, and training objectives, we align both models within a shared canonical space. We employ disentangled cooperative learning, which maintains stable training while enabling seamless collaboration during inference. Specifically, the reconstruction module is adapted to provide canonical geometric anchors, while the diffusion generator leverages latent-augmented conditioning to refine and complete the geometric structure. Experimental results demonstrate that UniRecGen achieves superior fidelity and robustness, outperforming existing methods in creating complete and consistent 3D models from sparse observations.
MTPano: Multi-Task Panoramic Scene Understanding via Label-Free Integration of Dense Prediction Priors
Feb 05, 2026Comprehensive panoramic scene understanding is critical for immersive applications, yet it remains challenging due to the scarcity of high-resolution, multi-task annotations. While perspective foundation models have achieved success through data scaling, directly adapting them to the panoramic domain often fails due to severe geometric distortions and coordinate system discrepancies. Furthermore, the underlying relations between diverse dense prediction tasks in spherical spaces are underexplored. To address these challenges, we propose MTPano, a robust multi-task panoramic foundation model established by a label-free training pipeline. First, to circumvent data scarcity, we leverage powerful perspective dense priors. We project panoramic images into perspective patches to generate accurate, domain-gap-free pseudo-labels using off-the-shelf foundation models, which are then re-projected to serve as patch-wise supervision. Second, to tackle the interference between task types, we categorize tasks into rotation-invariant (e.g., depth, segmentation) and rotation-variant (e.g., surface normals) groups. We introduce the Panoramic Dual BridgeNet, which disentangles these feature streams via geometry-aware modulation layers that inject absolute position and ray direction priors. To handle the distortion from equirectangular projections (ERP), we incorporate ERP token mixers followed by a dual-branch BridgeNet for interactions with gradient truncation, facilitating beneficial cross-task information sharing while blocking conflicting gradients from incompatible task attributes. Additionally, we introduce auxiliary tasks (image gradient, point map, etc.) to fertilize the cross-task learning process. Extensive experiments demonstrate that MTPano achieves state-of-the-art performance on multiple benchmarks and delivers competitive results against task-specific panoramic specialist foundation models.
SPGen: Spherical Projection as Consistent and Flexible Representation for Single Image 3D Shape Generation
Sep 16, 2025
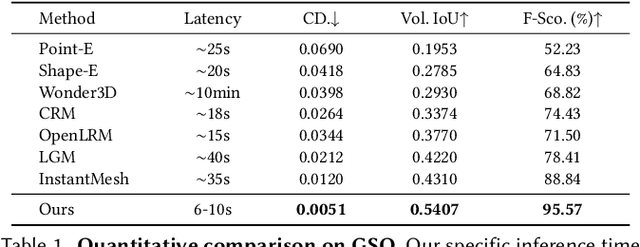
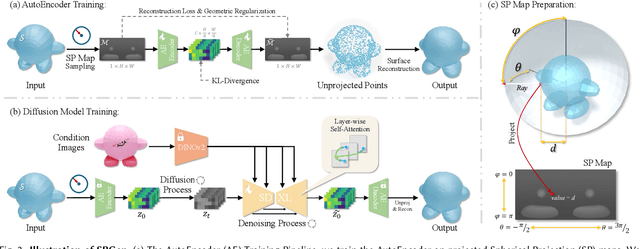
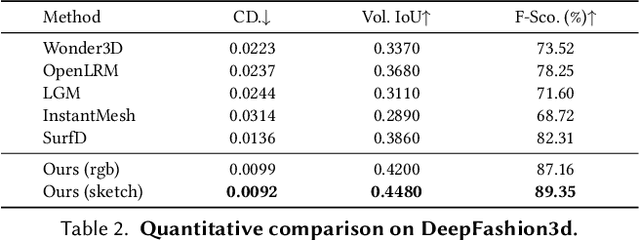
Existing single-view 3D generative models typically adopt multiview diffusion priors to reconstruct object surfaces, yet they remain prone to inter-view inconsistencies and are unable to faithfully represent complex internal structure or nontrivial topologies. In particular, we encode geometry information by projecting it onto a bounding sphere and unwrapping it into a compact and structural multi-layer 2D Spherical Projection (SP) representation. Operating solely in the image domain, SPGen offers three key advantages simultaneously: (1) Consistency. The injective SP mapping encodes surface geometry with a single viewpoint which naturally eliminates view inconsistency and ambiguity; (2) Flexibility. Multi-layer SP maps represent nested internal structures and support direct lifting to watertight or open 3D surfaces; (3) Efficiency. The image-domain formulation allows the direct inheritance of powerful 2D diffusion priors and enables efficient finetuning with limited computational resources. Extensive experiments demonstrate that SPGen significantly outperforms existing baselines in geometric quality and computational efficiency.
SolidGS: Consolidating Gaussian Surfel Splatting for Sparse-View Surface Reconstruction
Dec 19, 2024



Gaussian splatting has achieved impressive improvements for both novel-view synthesis and surface reconstruction from multi-view images. However, current methods still struggle to reconstruct high-quality surfaces from only sparse view input images using Gaussian splatting. In this paper, we propose a novel method called SolidGS to address this problem. We observed that the reconstructed geometry can be severely inconsistent across multi-views, due to the property of Gaussian function in geometry rendering. This motivates us to consolidate all Gaussians by adopting a more solid kernel function, which effectively improves the surface reconstruction quality. With the additional help of geometrical regularization and monocular normal estimation, our method achieves superior performance on the sparse view surface reconstruction than all the Gaussian splatting methods and neural field methods on the widely used DTU, Tanks-and-Temples, and LLFF datasets.
DICE: End-to-end Deformation Capture of Hand-Face Interactions from a Single Image
Jun 26, 2024



Reconstructing 3D hand-face interactions with deformations from a single image is a challenging yet crucial task with broad applications in AR, VR, and gaming. The challenges stem from self-occlusions during single-view hand-face interactions, diverse spatial relationships between hands and face, complex deformations, and the ambiguity of the single-view setting. The first and only method for hand-face interaction recovery, Decaf, introduces a global fitting optimization guided by contact and deformation estimation networks trained on studio-collected data with 3D annotations. However, Decaf suffers from a time-consuming optimization process and limited generalization capability due to its reliance on 3D annotations of hand-face interaction data. To address these issues, we present DICE, the first end-to-end method for Deformation-aware hand-face Interaction reCovEry from a single image. DICE estimates the poses of hands and faces, contacts, and deformations simultaneously using a Transformer-based architecture. It features disentangling the regression of local deformation fields and global mesh vertex locations into two network branches, enhancing deformation and contact estimation for precise and robust hand-face mesh recovery. To improve generalizability, we propose a weakly-supervised training approach that augments the training set using in-the-wild images without 3D ground-truth annotations, employing the depths of 2D keypoints estimated by off-the-shelf models and adversarial priors of poses for supervision. Our experiments demonstrate that DICE achieves state-of-the-art performance on a standard benchmark and in-the-wild data in terms of accuracy and physical plausibility. Additionally, our method operates at an interactive rate (20 fps) on an Nvidia 4090 GPU, whereas Decaf requires more than 15 seconds for a single image. Our code will be publicly available upon publication.
Disentangled Clothed Avatar Generation from Text Descriptions
Dec 08, 2023
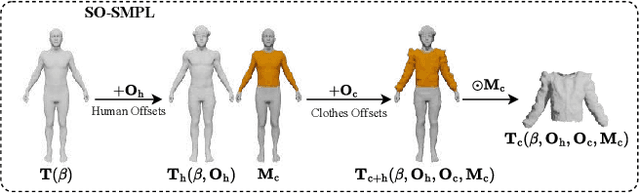
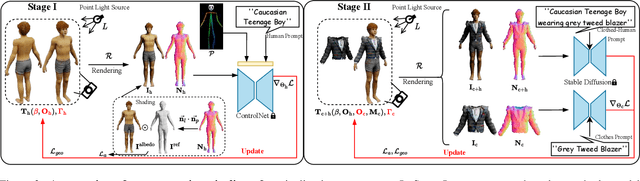

In this paper, we introduced a novel text-to-avatar generation method that separately generates the human body and the clothes and allows high-quality animation on the generated avatar. While recent advancements in text-to-avatar generation have yielded diverse human avatars from text prompts, these methods typically combine all elements-clothes, hair, and body-into a single 3D representation. Such an entangled approach poses challenges for downstream tasks like editing or animation. To overcome these limitations, we propose a novel disentangled 3D avatar representation named Sequentially Offset-SMPL (SO-SMPL), building upon the SMPL model. SO-SMPL represents the human body and clothes with two separate meshes, but associates them with offsets to ensure the physical alignment between the body and the clothes. Then, we design an Score Distillation Sampling(SDS)-based distillation framework to generate the proposed SO-SMPL representation from text prompts. In comparison with existing text-to-avatar methods, our approach not only achieves higher exture and geometry quality and better semantic alignment with text prompts, but also significantly improves the visual quality of character animation, virtual try-on, and avatar editing. Our project page is at https://shanemankiw.github.io/SO-SMPL/.
Surf-D: High-Quality Surface Generation for Arbitrary Topologies using Diffusion Models
Nov 28, 2023In this paper, we present Surf-D, a novel method for generating high-quality 3D shapes as Surfaces with arbitrary topologies using Diffusion models. Specifically, we adopt Unsigned Distance Field (UDF) as the surface representation, as it excels in handling arbitrary topologies, enabling the generation of complex shapes. While the prior methods explored shape generation with different representations, they suffer from limited topologies and geometry details. Moreover, it's non-trivial to directly extend prior diffusion models to UDF because they lack spatial continuity due to the discrete volume structure. However, UDF requires accurate gradients for mesh extraction and learning. To tackle the issues, we first leverage a point-based auto-encoder to learn a compact latent space, which supports gradient querying for any input point through differentiation to effectively capture intricate geometry at a high resolution. Since the learning difficulty for various shapes can differ, a curriculum learning strategy is employed to efficiently embed various surfaces, enhancing the whole embedding process. With pretrained shape latent space, we employ a latent diffusion model to acquire the distribution of various shapes. Our approach demonstrates superior performance in shape generation across multiple modalities and conducts extensive experiments in unconditional generation, category conditional generation, 3D reconstruction from images, and text-to-shape tasks.