 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKinema4D: Kinematic 4D World Modeling for Spatiotemporal Embodied Simulation
Mar 17, 2026Simulating robot-world interactions is a cornerstone of Embodied AI. Recently, a few works have shown promise in leveraging video generations to transcend the rigid visual/physical constraints of traditional simulators. However, they primarily operate in 2D space or are guided by static environmental cues, ignoring the fundamental reality that robot-world interactions are inherently 4D spatiotemporal events that require precise interactive modeling. To restore this 4D essence while ensuring the precise robot control, we introduce Kinema4D, a new action-conditioned 4D generative robotic simulator that disentangles the robot-world interaction into: i) Precise 4D representation of robot controls: we drive a URDF-based 3D robot via kinematics, producing a precise 4D robot control trajectory. ii) Generative 4D modeling of environmental reactions: we project the 4D robot trajectory into a pointmap as a spatiotemporal visual signal, controlling the generative model to synthesize complex environments' reactive dynamics into synchronized RGB/pointmap sequences. To facilitate training, we curated a large-scale dataset called Robo4D-200k, comprising 201,426 robot interaction episodes with high-quality 4D annotations. Extensive experiments demonstrate that our method effectively simulates physically-plausible, geometry-consistent, and embodiment-agnostic interactions that faithfully mirror diverse real-world dynamics. For the first time, it shows potential zero-shot transfer capability, providing a high-fidelity foundation for advancing next-generation embodied simulation.
LoFA: Learning to Predict Personalized Priors for Fast Adaptation of Visual Generative Models
Dec 09, 2025Personalizing visual generative models to meet specific user needs has gained increasing attention, yet current methods like Low-Rank Adaptation (LoRA) remain impractical due to their demand for task-specific data and lengthy optimization. While a few hypernetwork-based approaches attempt to predict adaptation weights directly, they struggle to map fine-grained user prompts to complex LoRA distributions, limiting their practical applicability. To bridge this gap, we propose LoFA, a general framework that efficiently predicts personalized priors for fast model adaptation. We first identify a key property of LoRA: structured distribution patterns emerge in the relative changes between LoRA and base model parameters. Building on this, we design a two-stage hypernetwork: first predicting relative distribution patterns that capture key adaptation regions, then using these to guide final LoRA weight prediction. Extensive experiments demonstrate that our method consistently predicts high-quality personalized priors within seconds, across multiple tasks and user prompts, even outperforming conventional LoRA that requires hours of processing. Project page: https://jaeger416.github.io/lofa/.
TASTE-Rob: Advancing Video Generation of Task-Oriented Hand-Object Interaction for Generalizable Robotic Manipulation
Mar 14, 2025

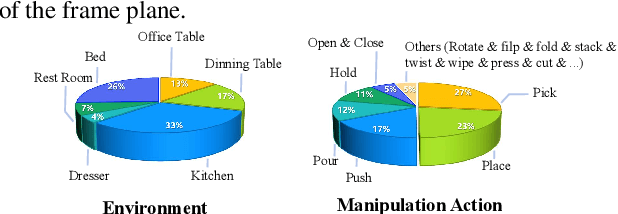
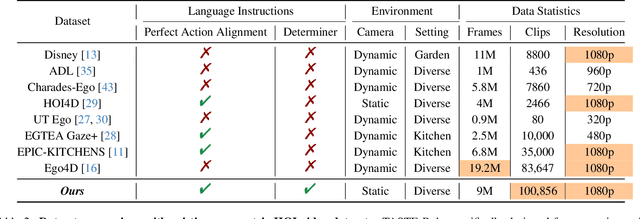
We address key limitations in existing datasets and models for task-oriented hand-object interaction video generation, a critical approach of generating video demonstrations for robotic imitation learning. Current datasets, such as Ego4D, often suffer from inconsistent view perspectives and misaligned interactions, leading to reduced video quality and limiting their applicability for precise imitation learning tasks. Towards this end, we introduce TASTE-Rob -- a pioneering large-scale dataset of 100,856 ego-centric hand-object interaction videos. Each video is meticulously aligned with language instructions and recorded from a consistent camera viewpoint to ensure interaction clarity. By fine-tuning a Video Diffusion Model (VDM) on TASTE-Rob, we achieve realistic object interactions, though we observed occasional inconsistencies in hand grasping postures. To enhance realism, we introduce a three-stage pose-refinement pipeline that improves hand posture accuracy in generated videos. Our curated dataset, coupled with the specialized pose-refinement framework, provides notable performance gains in generating high-quality, task-oriented hand-object interaction videos, resulting in achieving superior generalizable robotic manipulation. The TASTE-Rob dataset will be made publicly available upon publication to foster further advancements in the field.
SAMPro3D: Locating SAM Prompts in 3D for Zero-Shot Scene Segmentation
Nov 29, 2023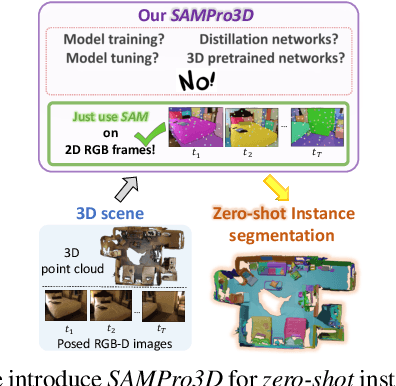
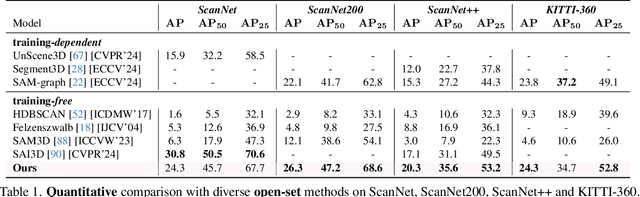
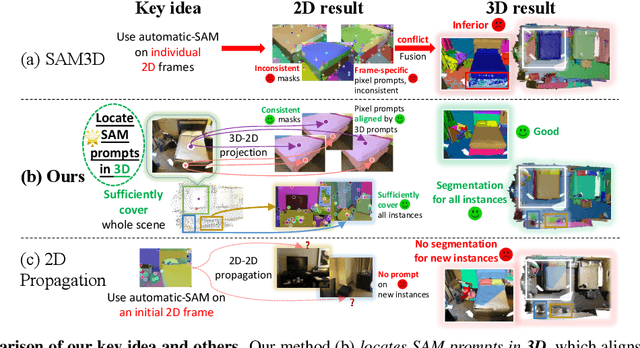

We introduce SAMPro3D for zero-shot 3D indoor scene segmentation. Given the 3D point cloud and multiple posed 2D frames of 3D scenes, our approach segments 3D scenes by applying the pretrained Segment Anything Model (SAM) to 2D frames. Our key idea involves locating 3D points in scenes as natural 3D prompts to align their projected pixel prompts across frames, ensuring frame-consistency in both pixel prompts and their SAM-predicted masks. Moreover, we suggest filtering out low-quality 3D prompts based on feedback from all 2D frames, for enhancing segmentation quality. We also propose to consolidate different 3D prompts if they are segmenting the same object, bringing a more comprehensive segmentation. Notably, our method does not require any additional training on domain-specific data, enabling us to preserve the zero-shot power of SAM. Extensive qualitative and quantitative results show that our method consistently achieves higher quality and more diverse segmentation than previous zero-shot or fully supervised approaches, and in many cases even surpasses human-level annotations. The project page can be accessed at https://mutianxu.github.io/sampro3d/.
RichDreamer: A Generalizable Normal-Depth Diffusion Model for Detail Richness in Text-to-3D
Nov 28, 2023


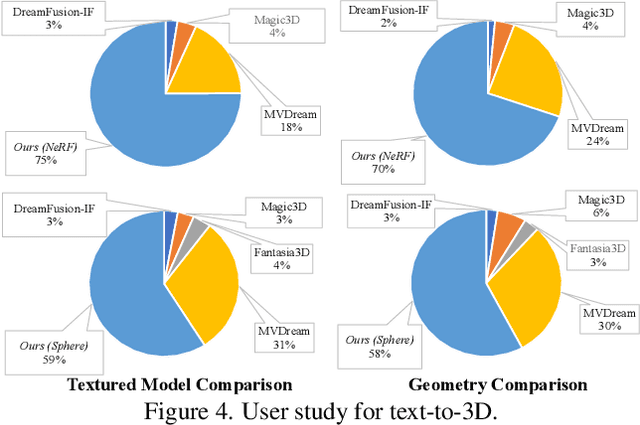
Lifting 2D diffusion for 3D generation is a challenging problem due to the lack of geometric prior and the complex entanglement of materials and lighting in natural images. Existing methods have shown promise by first creating the geometry through score-distillation sampling (SDS) applied to rendered surface normals, followed by appearance modeling. However, relying on a 2D RGB diffusion model to optimize surface normals is suboptimal due to the distribution discrepancy between natural images and normals maps, leading to instability in optimization. In this paper, recognizing that the normal and depth information effectively describe scene geometry and be automatically estimated from images, we propose to learn a generalizable Normal-Depth diffusion model for 3D generation. We achieve this by training on the large-scale LAION dataset together with the generalizable image-to-depth and normal prior models. In an attempt to alleviate the mixed illumination effects in the generated materials, we introduce an albedo diffusion model to impose data-driven constraints on the albedo component. Our experiments show that when integrated into existing text-to-3D pipelines, our models significantly enhance the detail richness, achieving state-of-the-art results. Our project page is https://lingtengqiu.github.io/RichDreamer/.
Free-ATM: Exploring Unsupervised Learning on Diffusion-Generated Images with Free Attention Masks
Aug 13, 2023Despite the rapid advancement of unsupervised learning in visual representation, it requires training on large-scale datasets that demand costly data collection, and pose additional challenges due to concerns regarding data privacy. Recently, synthetic images generated by text-to-image diffusion models, have shown great potential for benefiting image recognition. Although promising, there has been inadequate exploration dedicated to unsupervised learning on diffusion-generated images. To address this, we start by uncovering that diffusion models' cross-attention layers inherently provide annotation-free attention masks aligned with corresponding text inputs on generated images. We then investigate the problems of three prevalent unsupervised learning techniques ( i.e., contrastive learning, masked modeling, and vision-language pretraining) and introduce customized solutions by fully exploiting the aforementioned free attention masks. Our approach is validated through extensive experiments that show consistent improvements in baseline models across various downstream tasks, including image classification, detection, segmentation, and image-text retrieval. By utilizing our method, it is possible to close the performance gap between unsupervised pretraining on synthetic data and real-world scenarios.
REC-MV: REconstructing 3D Dynamic Cloth from Monocular Videos
May 23, 2023



Reconstructing dynamic 3D garment surfaces with open boundaries from monocular videos is an important problem as it provides a practical and low-cost solution for clothes digitization. Recent neural rendering methods achieve high-quality dynamic clothed human reconstruction results from monocular video, but these methods cannot separate the garment surface from the body. Moreover, despite existing garment reconstruction methods based on feature curve representation demonstrating impressive results for garment reconstruction from a single image, they struggle to generate temporally consistent surfaces for the video input. To address the above limitations, in this paper, we formulate this task as an optimization problem of 3D garment feature curves and surface reconstruction from monocular video. We introduce a novel approach, called REC-MV, to jointly optimize the explicit feature curves and the implicit signed distance field (SDF) of the garments. Then the open garment meshes can be extracted via garment template registration in the canonical space. Experiments on multiple casually captured datasets show that our approach outperforms existing methods and can produce high-quality dynamic garment surfaces. The source code is available at https://github.com/GAP-LAB-CUHK-SZ/REC-MV.
MVImgNet: A Large-scale Dataset of Multi-view Images
Mar 10, 2023



Being data-driven is one of the most iconic properties of deep learning algorithms. The birth of ImageNet drives a remarkable trend of "learning from large-scale data" in computer vision. Pretraining on ImageNet to obtain rich universal representations has been manifested to benefit various 2D visual tasks, and becomes a standard in 2D vision. However, due to the laborious collection of real-world 3D data, there is yet no generic dataset serving as a counterpart of ImageNet in 3D vision, thus how such a dataset can impact the 3D community is unraveled. To remedy this defect, we introduce MVImgNet, a large-scale dataset of multi-view images, which is highly convenient to gain by shooting videos of real-world objects in human daily life. It contains 6.5 million frames from 219,188 videos crossing objects from 238 classes, with rich annotations of object masks, camera parameters, and point clouds. The multi-view attribute endows our dataset with 3D-aware signals, making it a soft bridge between 2D and 3D vision. We conduct pilot studies for probing the potential of MVImgNet on a variety of 3D and 2D visual tasks, including radiance field reconstruction, multi-view stereo, and view-consistent image understanding, where MVImgNet demonstrates promising performance, remaining lots of possibilities for future explorations. Besides, via dense reconstruction on MVImgNet, a 3D object point cloud dataset is derived, called MVPNet, covering 87,200 samples from 150 categories, with the class label on each point cloud. Experiments show that MVPNet can benefit the real-world 3D object classification while posing new challenges to point cloud understanding. MVImgNet and MVPNet will be publicly available, hoping to inspire the broader vision community.
MM-3DScene: 3D Scene Understanding by Customizing Masked Modeling with Informative-Preserved Reconstruction and Self-Distilled Consistency
Dec 20, 2022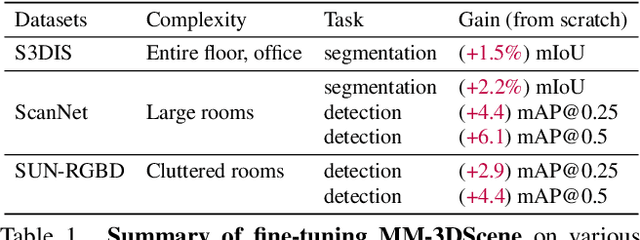
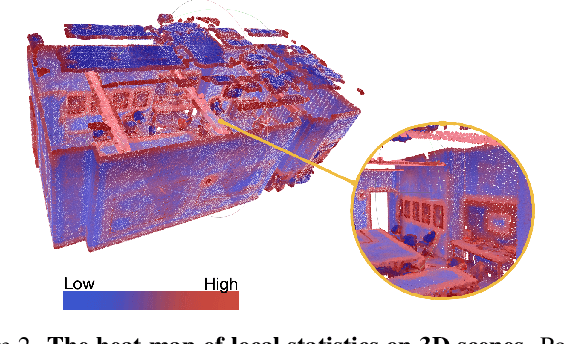

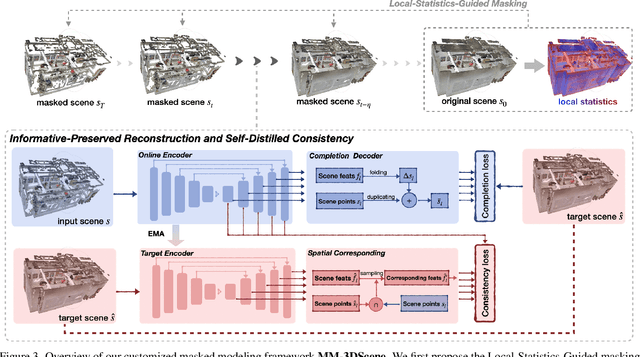
Masked Modeling (MM) has demonstrated widespread success in various vision challenges, by reconstructing masked visual patches. Yet, applying MM for large-scale 3D scenes remains an open problem due to the data sparsity and scene complexity. The conventional random masking paradigm used in 2D images often causes a high risk of ambiguity when recovering the masked region of 3D scenes. To this end, we propose a novel informative-preserved reconstruction, which explores local statistics to discover and preserve the representative structured points, effectively enhancing the pretext masking task for 3D scene understanding. Integrated with a progressive reconstruction manner, our method can concentrate on modeling regional geometry and enjoy less ambiguity for masked reconstruction. Besides, such scenes with progressive masking ratios can also serve to self-distill their intrinsic spatial consistency, requiring to learn the consistent representations from unmasked areas. By elegantly combining informative-preserved reconstruction on masked areas and consistency self-distillation from unmasked areas, a unified framework called MM-3DScene is yielded. We conduct comprehensive experiments on a host of downstream tasks. The consistent improvement (e.g., +6.1 mAP@0.5 on object detection and +2.2% mIoU on semantic segmentation) demonstrates the superiority of our approach.
A Survey on Graph Neural Networks and Graph Transformers in Computer Vision: A Task-Oriented Perspective
Oct 06, 2022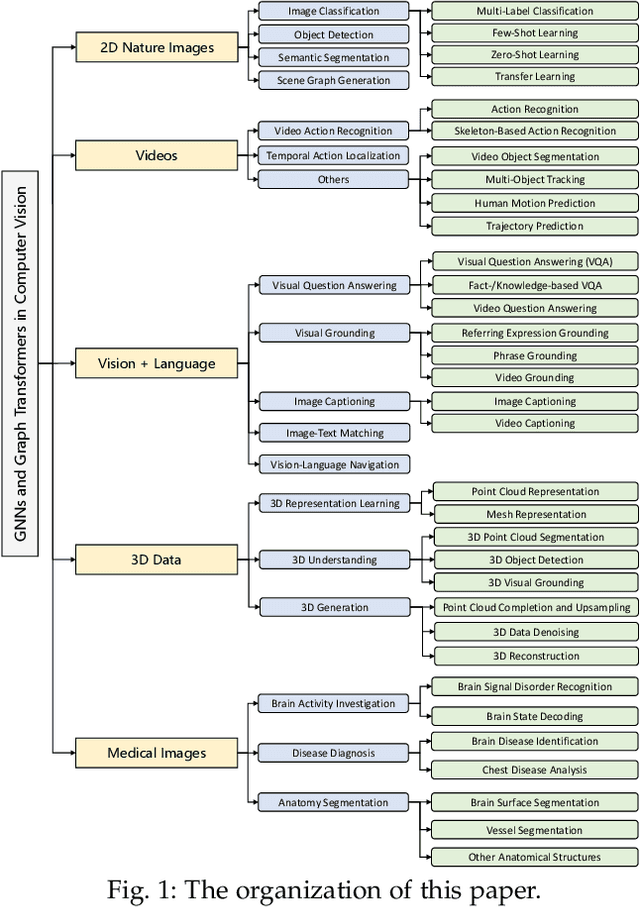
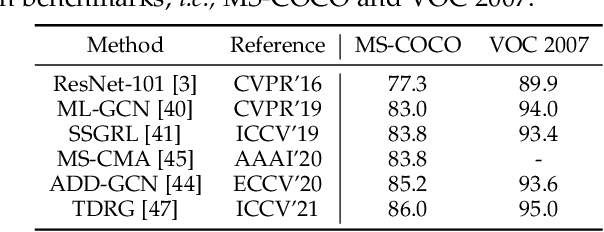

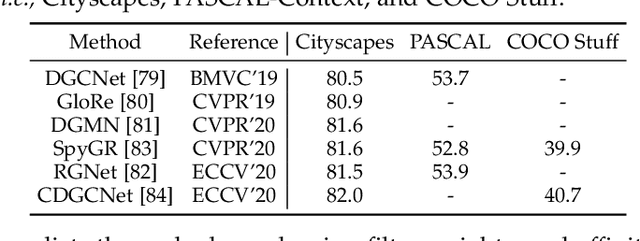
Graph Neural Networks (GNNs) have gained momentum in graph representation learning and boosted the state of the art in a variety of areas, such as data mining (\emph{e.g.,} social network analysis and recommender systems), computer vision (\emph{e.g.,} object detection and point cloud learning), and natural language processing (\emph{e.g.,} relation extraction and sequence learning), to name a few. With the emergence of Transformers in natural language processing and computer vision, graph Transformers embed a graph structure into the Transformer architecture to overcome the limitations of local neighborhood aggregation while avoiding strict structural inductive biases. In this paper, we present a comprehensive review of GNNs and graph Transformers in computer vision from a task-oriented perspective. Specifically, we divide their applications in computer vision into five categories according to the modality of input data, \emph{i.e.,} 2D natural images, videos, 3D data, vision + language, and medical images. In each category, we further divide the applications according to a set of vision tasks. Such a task-oriented taxonomy allows us to examine how each task is tackled by different GNN-based approaches and how well these approaches perform. Based on the necessary preliminaries, we provide the definitions and challenges of the tasks, in-depth coverage of the representative approaches, as well as discussions regarding insights, limitations, and future directions.