 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree on the Fly: Enhancing Flexibility in Test-Time Adaptation with Online EM
Jul 09, 2025Vision-Language Models (VLMs) have become prominent in open-world image recognition for their strong generalization abilities. Yet, their effectiveness in practical applications is compromised by domain shifts and distributional changes, especially when test data distributions diverge from training data. Therefore, the paradigm of test-time adaptation (TTA) has emerged, enabling the use of online off-the-shelf data at test time, supporting independent sample predictions, and eliminating reliance on test annotations. Traditional TTA methods, however, often rely on costly training or optimization processes, or make unrealistic assumptions about accessing or storing historical training and test data. Instead, this study proposes FreeTTA, a training-free and universally available method that makes no assumptions, to enhance the flexibility of TTA. More importantly, FreeTTA is the first to explicitly model the test data distribution, enabling the use of intrinsic relationships among test samples to enhance predictions of individual samples without simultaneous access--a direction not previously explored. FreeTTA achieves these advantages by introducing an online EM algorithm that utilizes zero-shot predictions from VLMs as priors to iteratively compute the posterior probabilities of each online test sample and update parameters. Experiments demonstrate that FreeTTA achieves stable and significant improvements compared to state-of-the-art methods across 15 datasets in both cross-domain and out-of-distribution settings.
Adaptive Part Learning for Fine-Grained Generalized Category Discovery: A Plug-and-Play Enhancement
Jul 09, 2025Generalized Category Discovery (GCD) aims to recognize unlabeled images from known and novel classes by distinguishing novel classes from known ones, while also transferring knowledge from another set of labeled images with known classes. Existing GCD methods rely on self-supervised vision transformers such as DINO for representation learning. However, focusing solely on the global representation of the DINO CLS token introduces an inherent trade-off between discriminability and generalization. In this paper, we introduce an adaptive part discovery and learning method, called APL, which generates consistent object parts and their correspondences across different similar images using a set of shared learnable part queries and DINO part priors, without requiring any additional annotations. More importantly, we propose a novel all-min contrastive loss to learn discriminative yet generalizable part representation, which adaptively highlights discriminative object parts to distinguish similar categories for enhanced discriminability while simultaneously sharing other parts to facilitate knowledge transfer for improved generalization. Our APL can easily be incorporated into different GCD frameworks by replacing their CLS token feature with our part representations, showing significant enhancements on fine-grained datasets.
Curriculum Point Prompting for Weakly-Supervised Referring Image Segmentation
Apr 18, 2024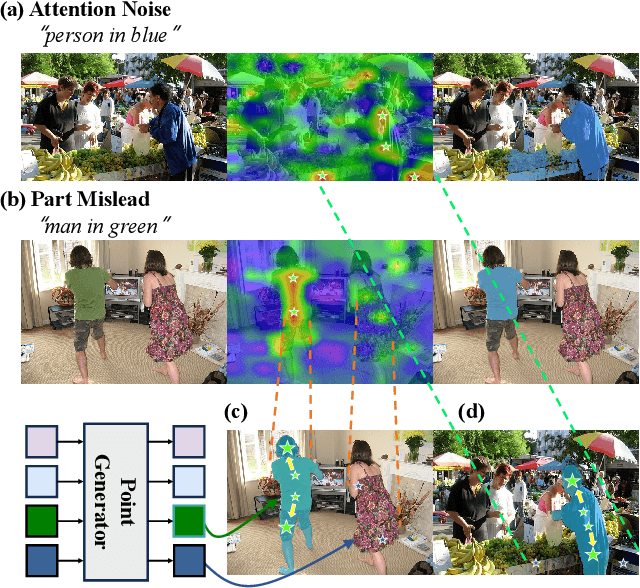
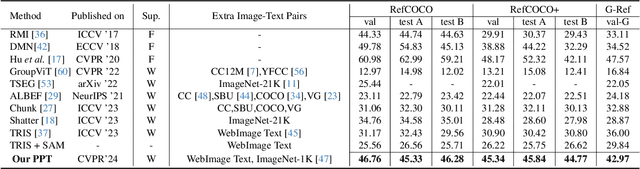
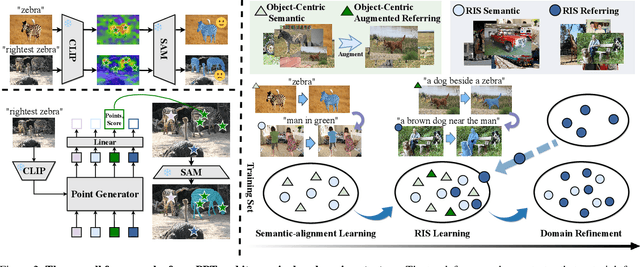
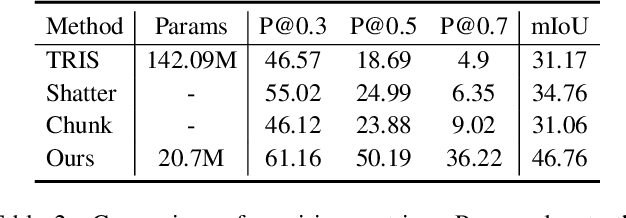
Referring image segmentation (RIS) aims to precisely segment referents in images through corresponding natural language expressions, yet relying on cost-intensive mask annotations. Weakly supervised RIS thus learns from image-text pairs to pixel-level semantics, which is challenging for segmenting fine-grained masks. A natural approach to enhancing segmentation precision is to empower weakly supervised RIS with the image segmentation foundation model SAM. Nevertheless, we observe that simply integrating SAM yields limited benefits and can even lead to performance regression due to the inevitable noise issues and challenges in excessive focus on object parts. In this paper, we present an innovative framework, Point PrompTing (PPT), incorporated with the proposed multi-source curriculum learning strategy to address these challenges. Specifically, the core of PPT is a point generator that not only harnesses CLIP's text-image alignment capability and SAM's powerful mask generation ability but also generates negative point prompts to address the noisy and excessive focus issues inherently and effectively. In addition, we introduce a curriculum learning strategy with object-centric images to help PPT gradually learn from simpler yet precise semantic alignment to more complex RIS. Experiments demonstrate that our PPT significantly and consistently outperforms prior weakly supervised techniques on mIoU by 11.34%, 14.14%, and 6.97% across RefCOCO, RefCOCO+, and G-Ref, respectively.
A Survey on Graph Neural Networks and Graph Transformers in Computer Vision: A Task-Oriented Perspective
Oct 06, 2022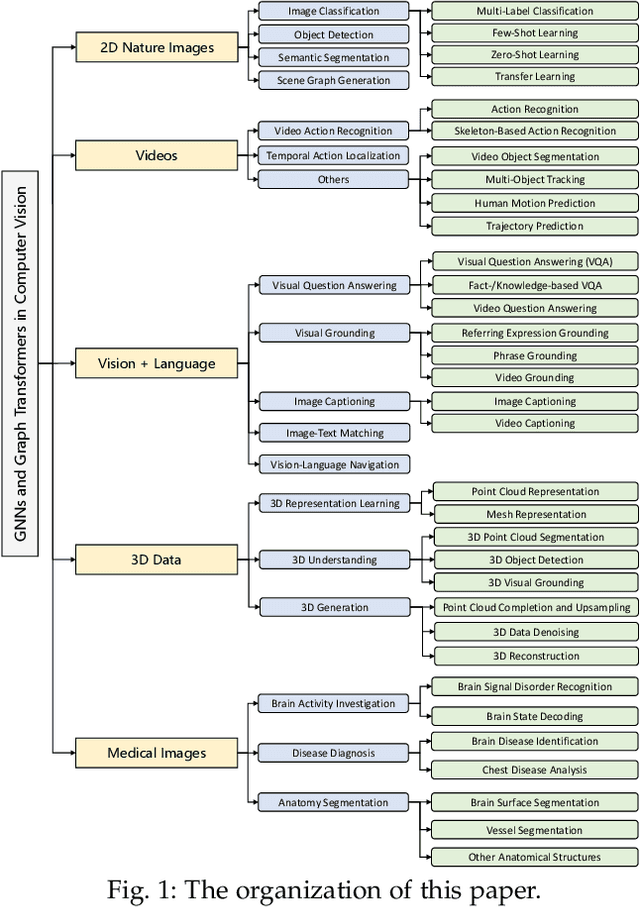
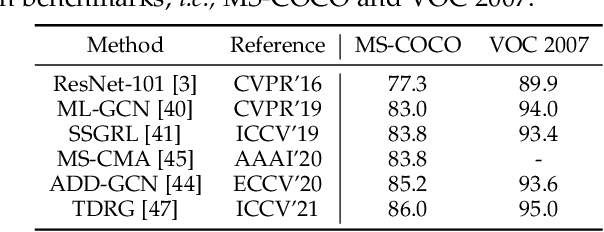

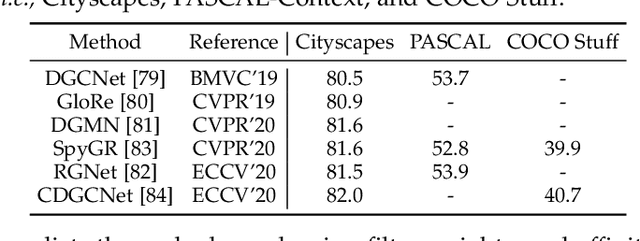
Graph Neural Networks (GNNs) have gained momentum in graph representation learning and boosted the state of the art in a variety of areas, such as data mining (\emph{e.g.,} social network analysis and recommender systems), computer vision (\emph{e.g.,} object detection and point cloud learning), and natural language processing (\emph{e.g.,} relation extraction and sequence learning), to name a few. With the emergence of Transformers in natural language processing and computer vision, graph Transformers embed a graph structure into the Transformer architecture to overcome the limitations of local neighborhood aggregation while avoiding strict structural inductive biases. In this paper, we present a comprehensive review of GNNs and graph Transformers in computer vision from a task-oriented perspective. Specifically, we divide their applications in computer vision into five categories according to the modality of input data, \emph{i.e.,} 2D natural images, videos, 3D data, vision + language, and medical images. In each category, we further divide the applications according to a set of vision tasks. Such a task-oriented taxonomy allows us to examine how each task is tackled by different GNN-based approaches and how well these approaches perform. Based on the necessary preliminaries, we provide the definitions and challenges of the tasks, in-depth coverage of the representative approaches, as well as discussions regarding insights, limitations, and future directions.