 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum Point Prompting for Weakly-Supervised Referring Image Segmentation
Paper and Code
Apr 18, 2024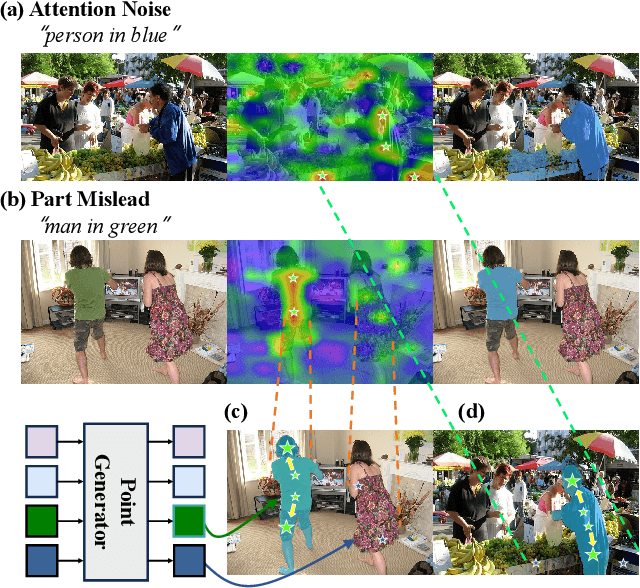
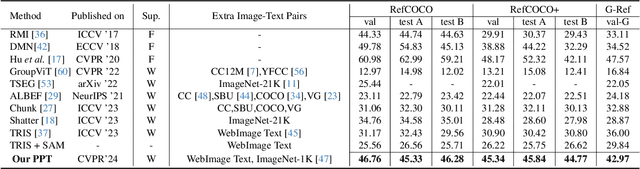
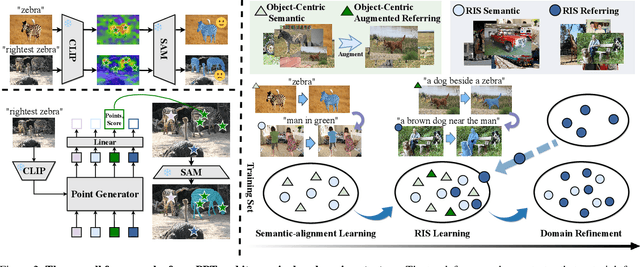
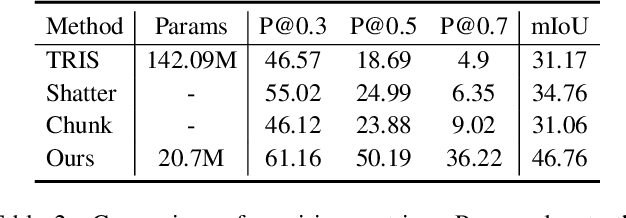
Referring image segmentation (RIS) aims to precisely segment referents in images through corresponding natural language expressions, yet relying on cost-intensive mask annotations. Weakly supervised RIS thus learns from image-text pairs to pixel-level semantics, which is challenging for segmenting fine-grained masks. A natural approach to enhancing segmentation precision is to empower weakly supervised RIS with the image segmentation foundation model SAM. Nevertheless, we observe that simply integrating SAM yields limited benefits and can even lead to performance regression due to the inevitable noise issues and challenges in excessive focus on object parts. In this paper, we present an innovative framework, Point PrompTing (PPT), incorporated with the proposed multi-source curriculum learning strategy to address these challenges. Specifically, the core of PPT is a point generator that not only harnesses CLIP's text-image alignment capability and SAM's powerful mask generation ability but also generates negative point prompts to address the noisy and excessive focus issues inherently and effectively. In addition, we introduce a curriculum learning strategy with object-centric images to help PPT gradually learn from simpler yet precise semantic alignment to more complex RIS. Experiments demonstrate that our PPT significantly and consistently outperforms prior weakly supervised techniques on mIoU by 11.34%, 14.14%, and 6.97% across RefCOCO, RefCOCO+, and G-Ref, respectively.