 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartNerFace: Part-based Neural Radiance Fields for Animatable Facial Avatar Reconstruction
Apr 15, 2026We present PartNerFace, a part-based neural radiance fields approach, for reconstructing animatable facial avatar from monocular RGB videos. Existing solutions either simply condition the implicit network with the morphable model parameters or learn an imaginary canonical radiance field, making them fail to generalize to unseen facial expressions and capture fine-scale motion details. To address these challenges, we first apply inverse skinning based on a parametric head model to map an observed point to the canonical space, and then model fine-scale motions with a part-based deformation field. Our key insight is that the deformation of different facial parts should be modeled differently. Specifically, our part-based deformation field consists of multiple local MLPs to adaptively partition the canonical space into different parts, where the deformation of a 3D point is computed by aggregating the prediction of all local MLPs by a soft-weighting mechanism. Extensive experiments demonstrate that our method generalizes well to unseen expressions and is capable of modeling fine-scale facial motions, outperforming state-of-the-art methods both quantitatively and qualitatively.
MVImgNet: A Large-scale Dataset of Multi-view Images
Mar 10, 2023



Being data-driven is one of the most iconic properties of deep learning algorithms. The birth of ImageNet drives a remarkable trend of "learning from large-scale data" in computer vision. Pretraining on ImageNet to obtain rich universal representations has been manifested to benefit various 2D visual tasks, and becomes a standard in 2D vision. However, due to the laborious collection of real-world 3D data, there is yet no generic dataset serving as a counterpart of ImageNet in 3D vision, thus how such a dataset can impact the 3D community is unraveled. To remedy this defect, we introduce MVImgNet, a large-scale dataset of multi-view images, which is highly convenient to gain by shooting videos of real-world objects in human daily life. It contains 6.5 million frames from 219,188 videos crossing objects from 238 classes, with rich annotations of object masks, camera parameters, and point clouds. The multi-view attribute endows our dataset with 3D-aware signals, making it a soft bridge between 2D and 3D vision. We conduct pilot studies for probing the potential of MVImgNet on a variety of 3D and 2D visual tasks, including radiance field reconstruction, multi-view stereo, and view-consistent image understanding, where MVImgNet demonstrates promising performance, remaining lots of possibilities for future explorations. Besides, via dense reconstruction on MVImgNet, a 3D object point cloud dataset is derived, called MVPNet, covering 87,200 samples from 150 categories, with the class label on each point cloud. Experiments show that MVPNet can benefit the real-world 3D object classification while posing new challenges to point cloud understanding. MVImgNet and MVPNet will be publicly available, hoping to inspire the broader vision community.
PVSeRF: Joint Pixel-, Voxel- and Surface-Aligned Radiance Field for Single-Image Novel View Synthesis
Feb 10, 2022
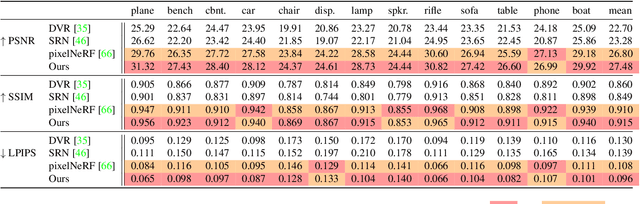
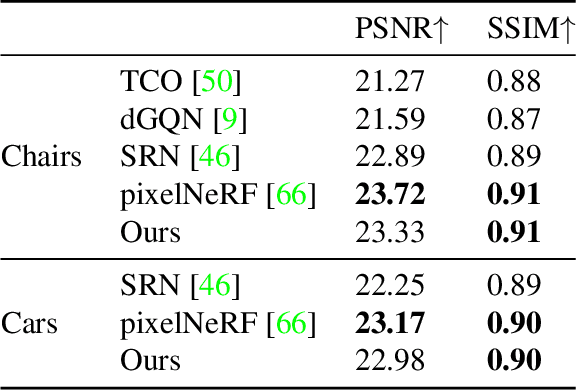
We present PVSeRF, a learning framework that reconstructs neural radiance fields from single-view RGB images, for novel view synthesis. Previous solutions, such as pixelNeRF, rely only on pixel-aligned features and suffer from feature ambiguity issues. As a result, they struggle with the disentanglement of geometry and appearance, leading to implausible geometries and blurry results. To address this challenge, we propose to incorporate explicit geometry reasoning and combine it with pixel-aligned features for radiance field prediction. Specifically, in addition to pixel-aligned features, we further constrain the radiance field learning to be conditioned on i) voxel-aligned features learned from a coarse volumetric grid and ii) fine surface-aligned features extracted from a regressed point cloud. We show that the introduction of such geometry-aware features helps to achieve a better disentanglement between appearance and geometry, i.e. recovering more accurate geometries and synthesizing higher quality images of novel views. Extensive experiments against state-of-the-art methods on ShapeNet benchmarks demonstrate the superiority of our approach for single-image novel view synthesis.
A deep learning based interactive sketching system for fashion images design
Oct 09, 2020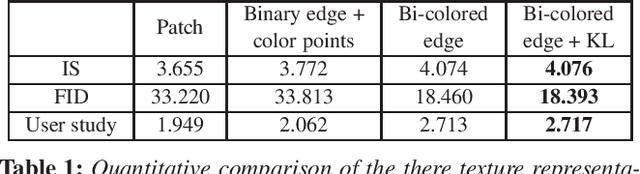
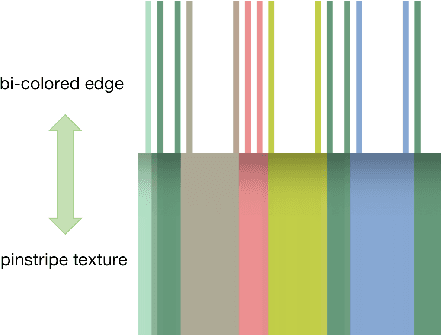
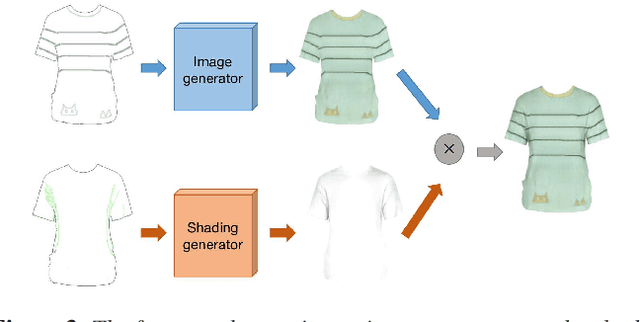

In this work, we propose an interactive system to design diverse high-quality garment images from fashion sketches and the texture information. The major challenge behind this system is to generate high-quality and detailed texture according to the user-provided texture information. Prior works mainly use the texture patch representation and try to map a small texture patch to a whole garment image, hence unable to generate high-quality details. In contrast, inspired by intrinsic image decomposition, we decompose this task into texture synthesis and shading enhancement. In particular, we propose a novel bi-colored edge texture representation to synthesize textured garment images and a shading enhancer to render shading based on the grayscale edges. The bi-colored edge representation provides simple but effective texture cues and color constraints, so that the details can be better reconstructed. Moreover, with the rendered shading, the synthesized garment image becomes more vivid.