 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamDissector: Learning Disentangled Text-to-3D Generation from 2D Diffusion Priors
Jul 23, 2024
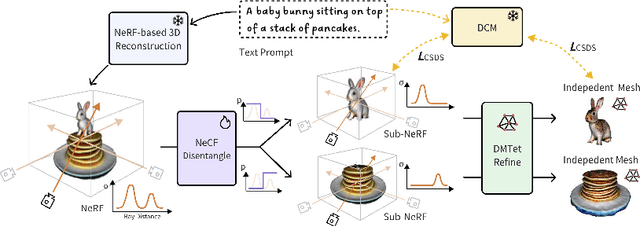
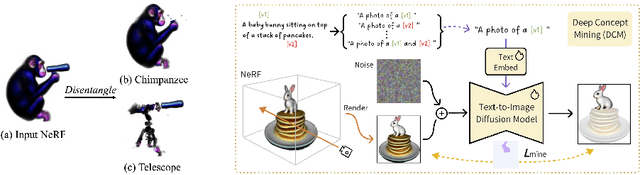

Text-to-3D generation has recently seen significant progress. To enhance its practicality in real-world applications, it is crucial to generate multiple independent objects with interactions, similar to layer-compositing in 2D image editing. However, existing text-to-3D methods struggle with this task, as they are designed to generate either non-independent objects or independent objects lacking spatially plausible interactions. Addressing this, we propose DreamDissector, a text-to-3D method capable of generating multiple independent objects with interactions. DreamDissector accepts a multi-object text-to-3D NeRF as input and produces independent textured meshes. To achieve this, we introduce the Neural Category Field (NeCF) for disentangling the input NeRF. Additionally, we present the Category Score Distillation Sampling (CSDS), facilitated by a Deep Concept Mining (DCM) module, to tackle the concept gap issue in diffusion models. By leveraging NeCF and CSDS, we can effectively derive sub-NeRFs from the original scene. Further refinement enhances geometry and texture. Our experimental results validate the effectiveness of DreamDissector, providing users with novel means to control 3D synthesis at the object level and potentially opening avenues for various creative applications in the future.
FIRST: A Million-Entry Dataset for Text-Driven Fashion Synthesis and Design
Nov 13, 2023



Text-driven fashion synthesis and design is an extremely valuable part of artificial intelligence generative content(AIGC), which has the potential to propel a tremendous revolution in the traditional fashion industry. To advance the research on text-driven fashion synthesis and design, we introduce a new dataset comprising a million high-resolution fashion images with rich structured textual(FIRST) descriptions. In the FIRST, there is a wide range of attire categories and each image-paired textual description is organized at multiple hierarchical levels. Experiments on prevalent generative models trained over FISRT show the necessity of FIRST. We invite the community to further develop more intelligent fashion synthesis and design systems that make fashion design more creative and imaginative based on our dataset. The dataset will be released soon.
REC-MV: REconstructing 3D Dynamic Cloth from Monocular Videos
May 23, 2023



Reconstructing dynamic 3D garment surfaces with open boundaries from monocular videos is an important problem as it provides a practical and low-cost solution for clothes digitization. Recent neural rendering methods achieve high-quality dynamic clothed human reconstruction results from monocular video, but these methods cannot separate the garment surface from the body. Moreover, despite existing garment reconstruction methods based on feature curve representation demonstrating impressive results for garment reconstruction from a single image, they struggle to generate temporally consistent surfaces for the video input. To address the above limitations, in this paper, we formulate this task as an optimization problem of 3D garment feature curves and surface reconstruction from monocular video. We introduce a novel approach, called REC-MV, to jointly optimize the explicit feature curves and the implicit signed distance field (SDF) of the garments. Then the open garment meshes can be extracted via garment template registration in the canonical space. Experiments on multiple casually captured datasets show that our approach outperforms existing methods and can produce high-quality dynamic garment surfaces. The source code is available at https://github.com/GAP-LAB-CUHK-SZ/REC-MV.