 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Task-Invariant Properties via Dreamer: Enabling Efficient Policy Transfer for Quadruped Robots
Apr 03, 2026Achieving quadruped robot locomotion across diverse and dynamic terrains presents significant challenges, primarily due to the discrepancies between simulation environments and real-world conditions. Traditional sim-to-real transfer methods often rely on manual feature design or costly real-world fine-tuning. To address these limitations, this paper proposes the DreamTIP framework, which incorporates Task-Invariant Properties learning within the Dreamer world model architecture to enhance sim-to-real transfer capabilities. Guided by large language models, DreamTIP identifies and leverages Task-Invariant Properties, such as contact stability and terrain clearance, which exhibit robustness to dynamic variations and strong transferability across tasks. These properties are integrated into the world model as auxiliary prediction targets, enabling the policy to learn representations that are insensitive to underlying dynamic changes. Furthermore, an efficient adaptation strategy is designed, employing a mixed replay buffer and regularization constraints to rapidly calibrate to real-world dynamics while effectively mitigating representation collapse and catastrophic forgetting. Extensive experiments on complex terrains, including Stair, Climb, Tilt, and Crawl, demonstrate that DreamTIP significantly outperforms state-of-the-art baselines in both simulated and real-world environments. Our method achieves an average performance improvement of 28.1% across eight distinct simulated transfer tasks. In the real-world Climb task, the baseline method achieved only a 10\ success rate, whereas our method attained a 100% success rate. These results indicate that incorporating Task-Invariant Properties into Dreamer learning offers a novel solution for achieving robust and transferable robot locomotion.
RoBridge: A Hierarchical Architecture Bridging Cognition and Execution for General Robotic Manipulation
May 03, 2025

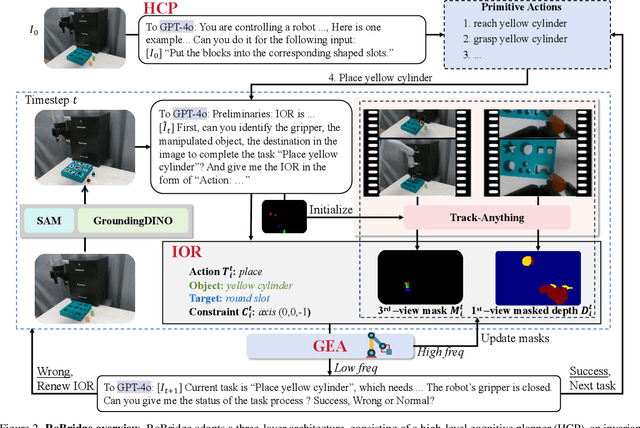

Operating robots in open-ended scenarios with diverse tasks is a crucial research and application direction in robotics. While recent progress in natural language processing and large multimodal models has enhanced robots' ability to understand complex instructions, robot manipulation still faces the procedural skill dilemma and the declarative skill dilemma in open environments. Existing methods often compromise cognitive and executive capabilities. To address these challenges, in this paper, we propose RoBridge, a hierarchical intelligent architecture for general robotic manipulation. It consists of a high-level cognitive planner (HCP) based on a large-scale pre-trained vision-language model (VLM), an invariant operable representation (IOR) serving as a symbolic bridge, and a generalist embodied agent (GEA). RoBridge maintains the declarative skill of VLM and unleashes the procedural skill of reinforcement learning, effectively bridging the gap between cognition and execution. RoBridge demonstrates significant performance improvements over existing baselines, achieving a 75% success rate on new tasks and an 83% average success rate in sim-to-real generalization using only five real-world data samples per task. This work represents a significant step towards integrating cognitive reasoning with physical execution in robotic systems, offering a new paradigm for general robotic manipulation.
Efficient Language-instructed Skill Acquisition via Reward-Policy Co-Evolution
Dec 18, 2024



The ability to autonomously explore and resolve tasks with minimal human guidance is crucial for the self-development of embodied intelligence. Although reinforcement learning methods can largely ease human effort, it's challenging to design reward functions for real-world tasks, especially for high-dimensional robotic control, due to complex relationships among joints and tasks. Recent advancements large language models (LLMs) enable automatic reward function design. However, approaches evaluate reward functions by re-training policies from scratch placing an undue burden on the reward function, expecting it to be effective throughout the whole policy improvement process. We argue for a more practical strategy in robotic autonomy, focusing on refining existing policies with policy-dependent reward functions rather than a universal one. To this end, we propose a novel reward-policy co-evolution framework where the reward function and the learned policy benefit from each other's progressive on-the-fly improvements, resulting in more efficient and higher-performing skill acquisition. Specifically, the reward evolution process translates the robot's previous best reward function, descriptions of tasks and environment into text inputs. These inputs are used to query LLMs to generate a dynamic amount of reward function candidates, ensuring continuous improvement at each round of evolution. For policy evolution, our method generates new policy populations by hybridizing historically optimal and random policies. Through an improved Bayesian optimization, our approach efficiently and robustly identifies the most capable and plastic reward-policy combination, which then proceeds to the next round of co-evolution. Despite using less data, our approach demonstrates an average normalized improvement of 95.3% across various high-dimensional robotic skill learning tasks.
VidMan: Exploiting Implicit Dynamics from Video Diffusion Model for Effective Robot Manipulation
Nov 14, 2024Recent advancements utilizing large-scale video data for learning video generation models demonstrate significant potential in understanding complex physical dynamics. It suggests the feasibility of leveraging diverse robot trajectory data to develop a unified, dynamics-aware model to enhance robot manipulation. However, given the relatively small amount of available robot data, directly fitting data without considering the relationship between visual observations and actions could lead to suboptimal data utilization. To this end, we propose VidMan (Video Diffusion for Robot Manipulation), a novel framework that employs a two-stage training mechanism inspired by dual-process theory from neuroscience to enhance stability and improve data utilization efficiency. Specifically, in the first stage, VidMan is pre-trained on the Open X-Embodiment dataset (OXE) for predicting future visual trajectories in a video denoising diffusion manner, enabling the model to develop a long horizontal awareness of the environment's dynamics. In the second stage, a flexible yet effective layer-wise self-attention adapter is introduced to transform VidMan into an efficient inverse dynamics model that predicts action modulated by the implicit dynamics knowledge via parameter sharing. Our VidMan framework outperforms state-of-the-art baseline model GR-1 on the CALVIN benchmark, achieving a 11.7% relative improvement, and demonstrates over 9% precision gains on the OXE small-scale dataset. These results provide compelling evidence that world models can significantly enhance the precision of robot action prediction. Codes and models will be public.
PIVOT-R: Primitive-Driven Waypoint-Aware World Model for Robotic Manipulation
Oct 14, 2024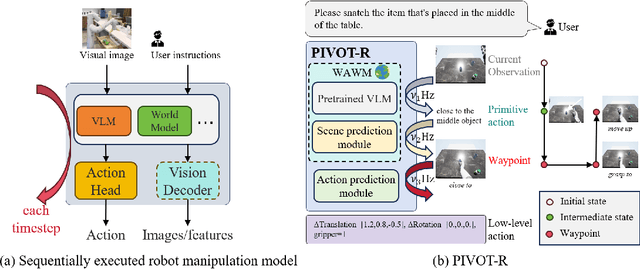
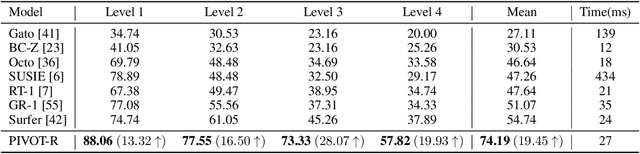
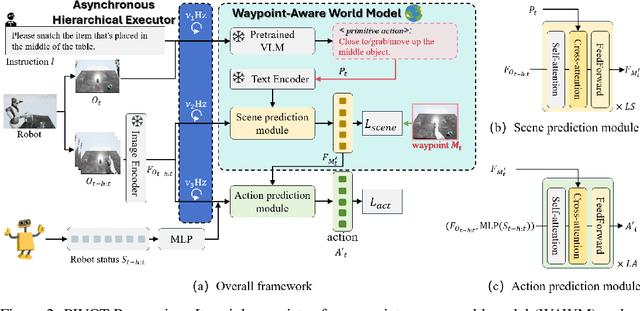
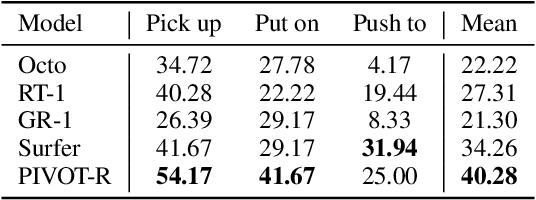
Language-guided robotic manipulation is a challenging task that requires an embodied agent to follow abstract user instructions to accomplish various complex manipulation tasks. Previous work trivially fitting the data without revealing the relation between instruction and low-level executable actions, these models are prone to memorizing the surficial pattern of the data instead of acquiring the transferable knowledge, and thus are fragile to dynamic environment changes. To address this issue, we propose a PrIrmitive-driVen waypOinT-aware world model for Robotic manipulation (PIVOT-R) that focuses solely on the prediction of task-relevant waypoints. Specifically, PIVOT-R consists of a Waypoint-aware World Model (WAWM) and a lightweight action prediction module. The former performs primitive action parsing and primitive-driven waypoint prediction, while the latter focuses on decoding low-level actions. Additionally, we also design an asynchronous hierarchical executor (AHE), which can use different execution frequencies for different modules of the model, thereby helping the model reduce computational redundancy and improve model execution efficiency. Our PIVOT-R outperforms state-of-the-art (SoTA) open-source models on the SeaWave benchmark, achieving an average relative improvement of 19.45% across four levels of instruction tasks. Moreover, compared to the synchronously executed PIVOT-R, the execution efficiency of PIVOT-R with AHE is increased by 28-fold, with only a 2.9% drop in performance. These results provide compelling evidence that our PIVOT-R can significantly improve both the performance and efficiency of robotic manipulation.
High-fidelity and Lip-synced Talking Face Synthesis via Landmark-based Diffusion Model
Aug 10, 2024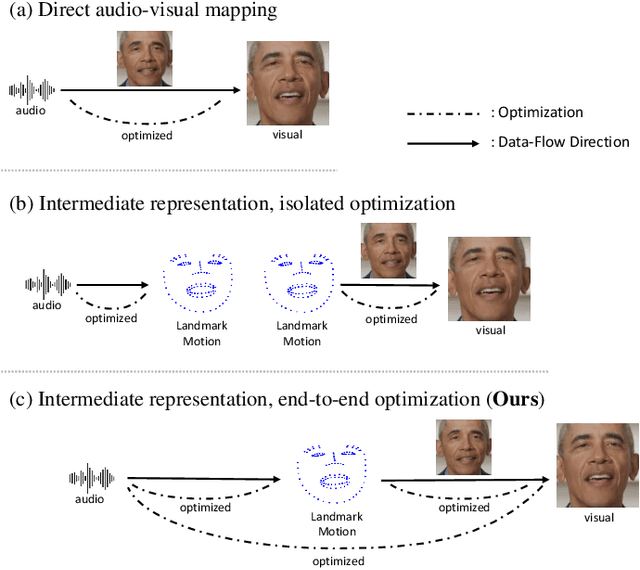
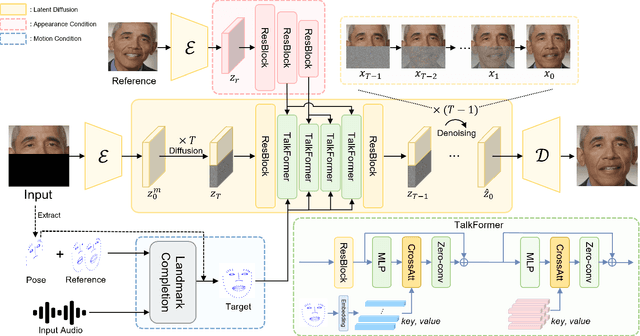


Audio-driven talking face video generation has attracted increasing attention due to its huge industrial potential. Some previous methods focus on learning a direct mapping from audio to visual content. Despite progress, they often struggle with the ambiguity of the mapping process, leading to flawed results. An alternative strategy involves facial structural representations (e.g., facial landmarks) as intermediaries. This multi-stage approach better preserves the appearance details but suffers from error accumulation due to the independent optimization of different stages. Moreover, most previous methods rely on generative adversarial networks, prone to training instability and mode collapse. To address these challenges, our study proposes a novel landmark-based diffusion model for talking face generation, which leverages facial landmarks as intermediate representations while enabling end-to-end optimization. Specifically, we first establish the less ambiguous mapping from audio to landmark motion of lip and jaw. Then, we introduce an innovative conditioning module called TalkFormer to align the synthesized motion with the motion represented by landmarks via differentiable cross-attention, which enables end-to-end optimization for improved lip synchronization. Besides, TalkFormer employs implicit feature warping to align the reference image features with the target motion for preserving more appearance details. Extensive experiments demonstrate that our approach can synthesize high-fidelity and lip-synced talking face videos, preserving more subject appearance details from the reference image.
DenseLight: Efficient Control for Large-scale Traffic Signals with Dense Feedback
Jun 13, 2023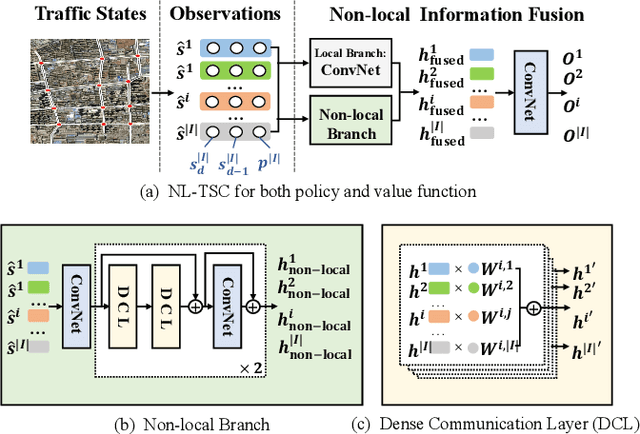
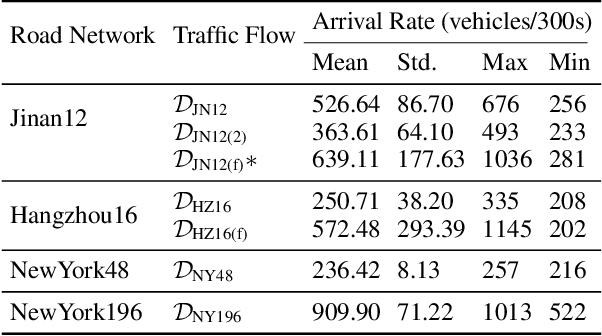
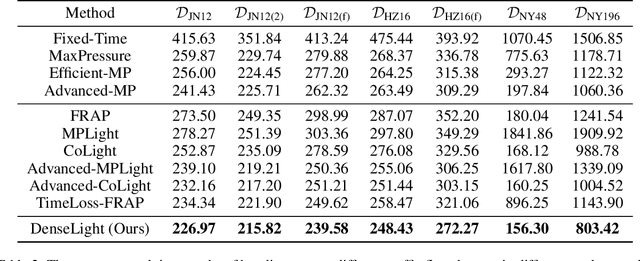
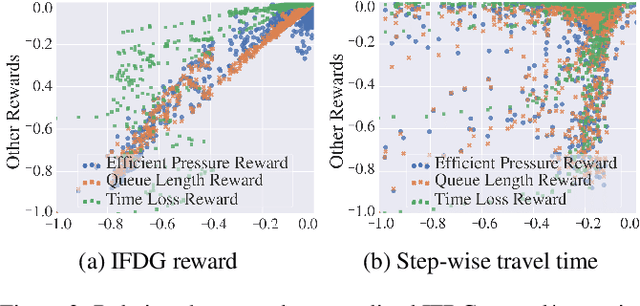
Traffic Signal Control (TSC) aims to reduce the average travel time of vehicles in a road network, which in turn enhances fuel utilization efficiency, air quality, and road safety, benefiting society as a whole. Due to the complexity of long-horizon control and coordination, most prior TSC methods leverage deep reinforcement learning (RL) to search for a control policy and have witnessed great success. However, TSC still faces two significant challenges. 1) The travel time of a vehicle is delayed feedback on the effectiveness of TSC policy at each traffic intersection since it is obtained after the vehicle has left the road network. Although several heuristic reward functions have been proposed as substitutes for travel time, they are usually biased and not leading the policy to improve in the correct direction. 2) The traffic condition of each intersection is influenced by the non-local intersections since vehicles traverse multiple intersections over time. Therefore, the TSC agent is required to leverage both the local observation and the non-local traffic conditions to predict the long-horizontal traffic conditions of each intersection comprehensively. To address these challenges, we propose DenseLight, a novel RL-based TSC method that employs an unbiased reward function to provide dense feedback on policy effectiveness and a non-local enhanced TSC agent to better predict future traffic conditions for more precise traffic control. Extensive experiments and ablation studies demonstrate that DenseLight can consistently outperform advanced baselines on various road networks with diverse traffic flows. The code is available at https://github.com/junfanlin/DenseLight.
Visual Tuning
May 10, 2023Fine-tuning visual models has been widely shown promising performance on many downstream visual tasks. With the surprising development of pre-trained visual foundation models, visual tuning jumped out of the standard modus operandi that fine-tunes the whole pre-trained model or just the fully connected layer. Instead, recent advances can achieve superior performance than full-tuning the whole pre-trained parameters by updating far fewer parameters, enabling edge devices and downstream applications to reuse the increasingly large foundation models deployed on the cloud. With the aim of helping researchers get the full picture and future directions of visual tuning, this survey characterizes a large and thoughtful selection of recent works, providing a systematic and comprehensive overview of existing work and models. Specifically, it provides a detailed background of visual tuning and categorizes recent visual tuning techniques into five groups: prompt tuning, adapter tuning, parameter tuning, and remapping tuning. Meanwhile, it offers some exciting research directions for prospective pre-training and various interactions in visual tuning.
OhMG: Zero-shot Open-vocabulary Human Motion Generation
Oct 28, 2022



Generating motion in line with text has attracted increasing attention nowadays. However, open-vocabulary human motion generation still remains touchless and undergoes the lack of diverse labeled data. The good news is that, recent studies of large multi-model foundation models (e.g., CLIP) have demonstrated superior performance on few/zero-shot image-text alignment, largely reducing the need for manually labeled data. In this paper, we take advantage of CLIP for open-vocabulary 3D human motion generation in a zero-shot manner. Specifically, our model is composed of two stages, i.e., text2pose and pose2motion. For text2pose, to address the difficulty of optimization with direct supervision from CLIP, we propose to carve the versatile CLIP model into a slimmer but more specific model for aligning 3D poses and texts, via a novel pipeline distillation strategy. Optimizing with the distilled 3D pose-text model, we manage to concretize the text-pose knowledge of CLIP into a text2pose generator effectively and efficiently. As for pose2motion, drawing inspiration from the advanced language model, we pretrain a transformer-based motion model, which makes up for the lack of motion dynamics of CLIP. After that, by formulating the generated poses from the text2pose stage as prompts, the motion generator can generate motions referring to the poses in a controllable and flexible manner. Our method is validated against advanced baselines and obtains sharp improvements. The code will be released here.
Continuous Transition: Improving Sample Efficiency for Continuous Control Problems via MixUp
Nov 30, 2020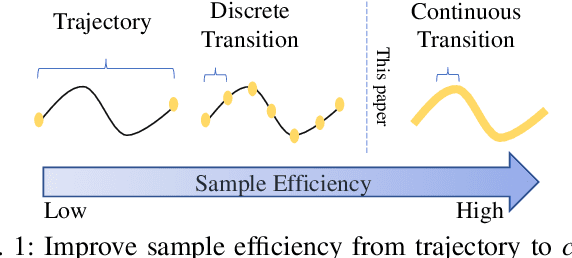
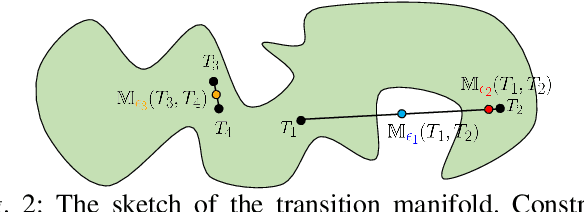
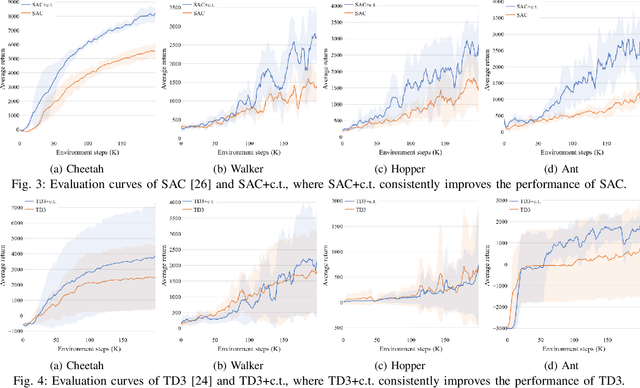
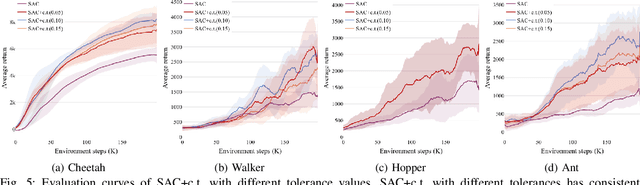
Although deep reinforcement learning~(RL) has been successfully applied to a variety of robotic control tasks, it's still challenging to apply it to real-world tasks, due to the poor sample efficiency. Attempting to overcome this shortcoming, several works focus on reusing the collected trajectory data during the training by decomposing them into a set of policy-irrelevant discrete transitions. However, their improvements are somewhat marginal since i) the amount of the transitions is usually small, and ii) the value assignment only happens in the joint states. To address these issues, this paper introduces a concise yet powerful method to construct \textit{Continuous Transition}, which exploits the trajectory information by exploiting the potential transitions along the trajectory. Specifically, we propose to synthesize new transitions for training by linearly interpolating the conjunctive transitions. To keep the constructed transitions authentic, we also develop a discriminator to guide the construction process automatically. Extensive experiments demonstrate that our proposed method achieves a significant improvement in sample efficiency on various complex continuous robotic control problems in MuJoCo and outperforms the advanced model-based / model-free RL methods.