 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-fidelity and Lip-synced Talking Face Synthesis via Landmark-based Diffusion Model
Aug 10, 2024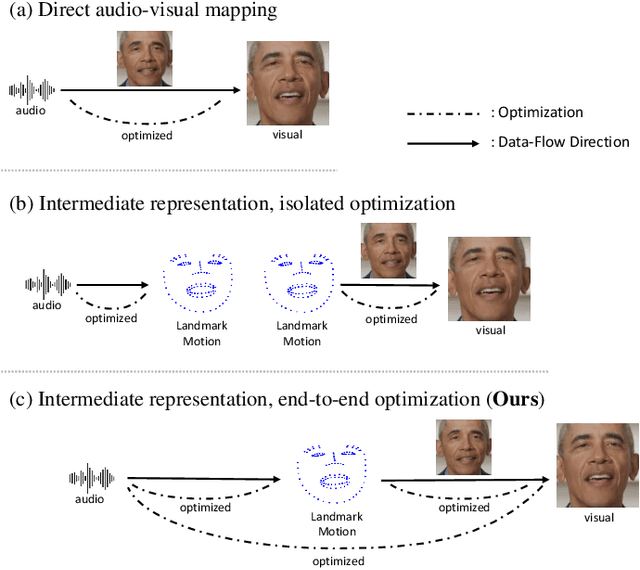
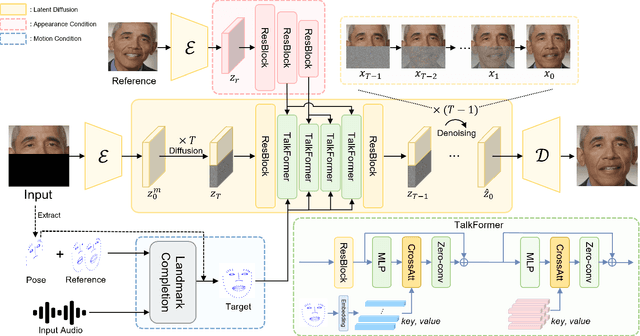


Audio-driven talking face video generation has attracted increasing attention due to its huge industrial potential. Some previous methods focus on learning a direct mapping from audio to visual content. Despite progress, they often struggle with the ambiguity of the mapping process, leading to flawed results. An alternative strategy involves facial structural representations (e.g., facial landmarks) as intermediaries. This multi-stage approach better preserves the appearance details but suffers from error accumulation due to the independent optimization of different stages. Moreover, most previous methods rely on generative adversarial networks, prone to training instability and mode collapse. To address these challenges, our study proposes a novel landmark-based diffusion model for talking face generation, which leverages facial landmarks as intermediate representations while enabling end-to-end optimization. Specifically, we first establish the less ambiguous mapping from audio to landmark motion of lip and jaw. Then, we introduce an innovative conditioning module called TalkFormer to align the synthesized motion with the motion represented by landmarks via differentiable cross-attention, which enables end-to-end optimization for improved lip synchronization. Besides, TalkFormer employs implicit feature warping to align the reference image features with the target motion for preserving more appearance details. Extensive experiments demonstrate that our approach can synthesize high-fidelity and lip-synced talking face videos, preserving more subject appearance details from the reference image.
WildVidFit: Video Virtual Try-On in the Wild via Image-Based Controlled Diffusion Models
Jul 15, 2024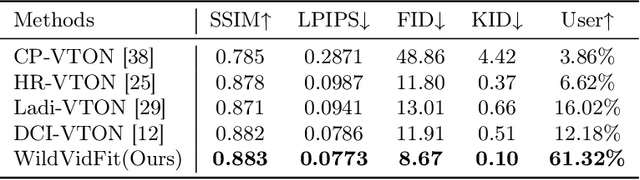
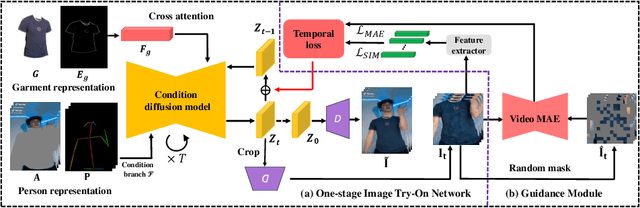
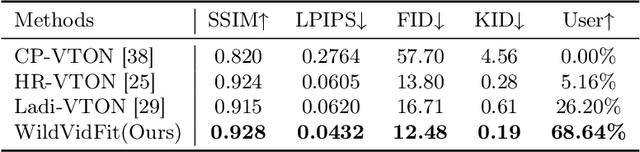
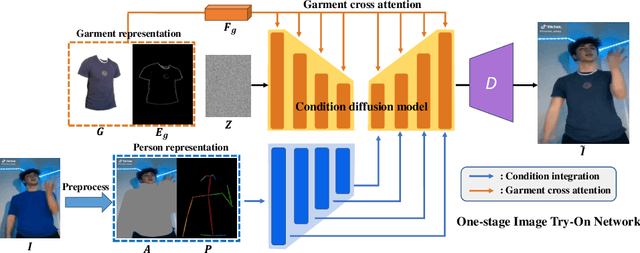
Video virtual try-on aims to generate realistic sequences that maintain garment identity and adapt to a person's pose and body shape in source videos. Traditional image-based methods, relying on warping and blending, struggle with complex human movements and occlusions, limiting their effectiveness in video try-on applications. Moreover, video-based models require extensive, high-quality data and substantial computational resources. To tackle these issues, we reconceptualize video try-on as a process of generating videos conditioned on garment descriptions and human motion. Our solution, WildVidFit, employs image-based controlled diffusion models for a streamlined, one-stage approach. This model, conditioned on specific garments and individuals, is trained on still images rather than videos. It leverages diffusion guidance from pre-trained models including a video masked autoencoder for segment smoothness improvement and a self-supervised model for feature alignment of adjacent frame in the latent space. This integration markedly boosts the model's ability to maintain temporal coherence, enabling more effective video try-on within an image-based framework. Our experiments on the VITON-HD and DressCode datasets, along with tests on the VVT and TikTok datasets, demonstrate WildVidFit's capability to generate fluid and coherent videos. The project page website is at wildvidfit-project.github.io.