 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIVOT-R: Primitive-Driven Waypoint-Aware World Model for Robotic Manipulation
Oct 14, 2024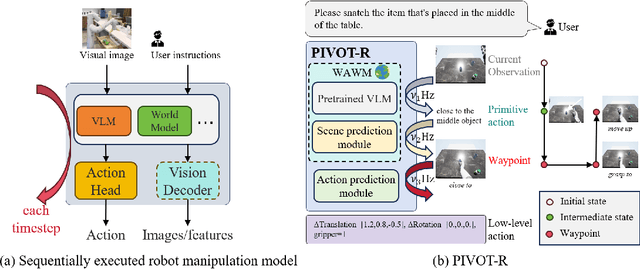
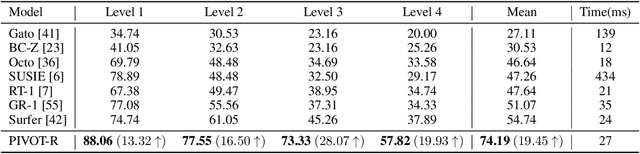
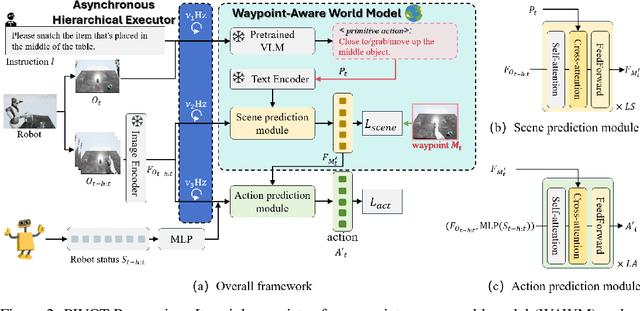
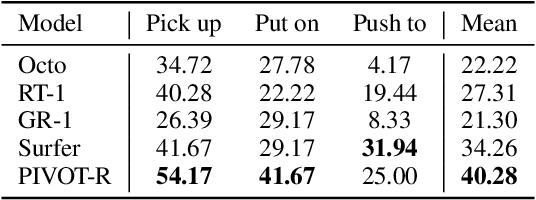
Language-guided robotic manipulation is a challenging task that requires an embodied agent to follow abstract user instructions to accomplish various complex manipulation tasks. Previous work trivially fitting the data without revealing the relation between instruction and low-level executable actions, these models are prone to memorizing the surficial pattern of the data instead of acquiring the transferable knowledge, and thus are fragile to dynamic environment changes. To address this issue, we propose a PrIrmitive-driVen waypOinT-aware world model for Robotic manipulation (PIVOT-R) that focuses solely on the prediction of task-relevant waypoints. Specifically, PIVOT-R consists of a Waypoint-aware World Model (WAWM) and a lightweight action prediction module. The former performs primitive action parsing and primitive-driven waypoint prediction, while the latter focuses on decoding low-level actions. Additionally, we also design an asynchronous hierarchical executor (AHE), which can use different execution frequencies for different modules of the model, thereby helping the model reduce computational redundancy and improve model execution efficiency. Our PIVOT-R outperforms state-of-the-art (SoTA) open-source models on the SeaWave benchmark, achieving an average relative improvement of 19.45% across four levels of instruction tasks. Moreover, compared to the synchronously executed PIVOT-R, the execution efficiency of PIVOT-R with AHE is increased by 28-fold, with only a 2.9% drop in performance. These results provide compelling evidence that our PIVOT-R can significantly improve both the performance and efficiency of robotic manipulation.
Correctable Landmark Discovery via Large Models for Vision-Language Navigation
May 29, 2024

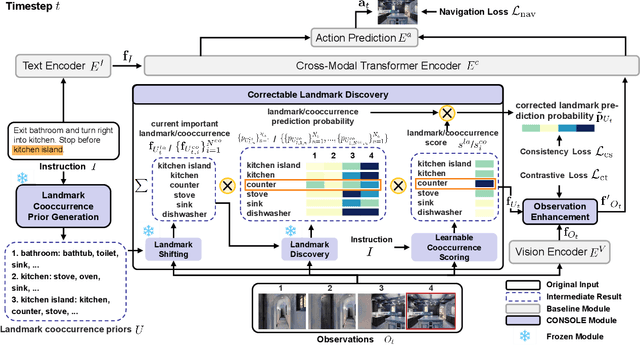

Vision-Language Navigation (VLN) requires the agent to follow language instructions to reach a target position. A key factor for successful navigation is to align the landmarks implied in the instruction with diverse visual observations. However, previous VLN agents fail to perform accurate modality alignment especially in unexplored scenes, since they learn from limited navigation data and lack sufficient open-world alignment knowledge. In this work, we propose a new VLN paradigm, called COrrectable LaNdmark DiScOvery via Large ModEls (CONSOLE). In CONSOLE, we cast VLN as an open-world sequential landmark discovery problem, by introducing a novel correctable landmark discovery scheme based on two large models ChatGPT and CLIP. Specifically, we use ChatGPT to provide rich open-world landmark cooccurrence commonsense, and conduct CLIP-driven landmark discovery based on these commonsense priors. To mitigate the noise in the priors due to the lack of visual constraints, we introduce a learnable cooccurrence scoring module, which corrects the importance of each cooccurrence according to actual observations for accurate landmark discovery. We further design an observation enhancement strategy for an elegant combination of our framework with different VLN agents, where we utilize the corrected landmark features to obtain enhanced observation features for action decision. Extensive experimental results on multiple popular VLN benchmarks (R2R, REVERIE, R4R, RxR) show the significant superiority of CONSOLE over strong baselines. Especially, our CONSOLE establishes the new state-of-the-art results on R2R and R4R in unseen scenarios. Code is available at https://github.com/expectorlin/CONSOLE.
NavCoT: Boosting LLM-Based Vision-and-Language Navigation via Learning Disentangled Reasoning
Mar 12, 2024



Vision-and-Language Navigation (VLN), as a crucial research problem of Embodied AI, requires an embodied agent to navigate through complex 3D environments following natural language instructions. Recent research has highlighted the promising capacity of large language models (LLMs) in VLN by improving navigational reasoning accuracy and interpretability. However, their predominant use in an offline manner usually suffers from substantial domain gap between the VLN task and the LLM training corpus. This paper introduces a novel strategy called Navigational Chain-of-Thought (NavCoT), where we fulfill parameter-efficient in-domain training to enable self-guided navigational decision, leading to a significant mitigation of the domain gap in a cost-effective manner. Specifically, at each timestep, the LLM is prompted to forecast the navigational chain-of-thought by: 1) acting as a world model to imagine the next observation according to the instruction, 2) selecting the candidate observation that best aligns with the imagination, and 3) determining the action based on the reasoning from the prior steps. Through constructing formalized labels for training, the LLM can learn to generate desired and reasonable chain-of-thought outputs for improving the action decision. Experimental results across various training settings and popular VLN benchmarks (e.g., Room-to-Room (R2R), Room-across-Room (RxR), Room-for-Room (R4R)) show the significant superiority of NavCoT over the direct action prediction variants. Through simple parameter-efficient finetuning, our NavCoT outperforms a recent GPT4-based approach with ~7% relative improvement on the R2R dataset. We believe that NavCoT will help unlock more task-adaptive and scalable LLM-based embodied agents, which are helpful for developing real-world robotics applications. Code is available at https://github.com/expectorlin/NavCoT.
MO-VLN: A Multi-Task Benchmark for Open-set Zero-Shot Vision-and-Language Navigation
Jun 17, 2023


Given a natural language, a general robot has to comprehend the instruction and find the target object or location based on visual observations even in unexplored environments. Most agents rely on massive diverse training data to achieve better generalization, which requires expensive labor. These agents often focus on common objects and fewer tasks, thus are not intelligent enough to handle different types of instructions. To facilitate research in open-set vision-and-language navigation, we propose a benchmark named MO-VLN, aiming at testing the effectiveness and generalization of the agent in the multi-task setting. First, we develop a 3D simulator rendered by realistic scenarios using Unreal Engine 5, containing more realistic lights and details. The simulator contains three scenes, i.e., cafe, restaurant, and nursing house, of high value in the industry. Besides, our simulator involves multiple uncommon objects, such as takeaway cup and medical adhesive tape, which are more complicated compared with existing environments. Inspired by the recent success of large language models (e.g., ChatGPT, Vicuna), we construct diverse high-quality data of instruction type without human annotation. Our benchmark MO-VLN provides four tasks: 1) goal-conditioned navigation given a specific object category (e.g., "fork"); 2) goal-conditioned navigation given simple instructions (e.g., "Search for and move towards a tennis ball"); 3) step-by-step instruction following; 4) finding abstract object based on high-level instruction (e.g., "I am thirsty").