 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototypical Graph Contrastive Learning
Jun 17, 2021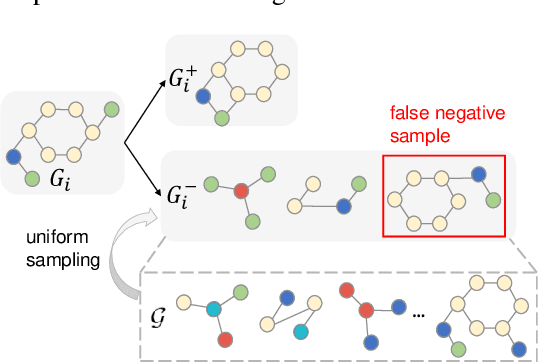
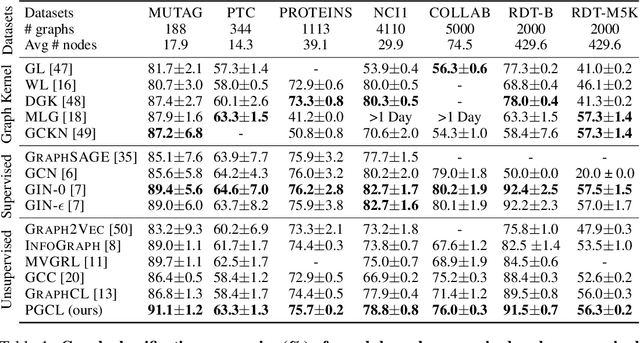
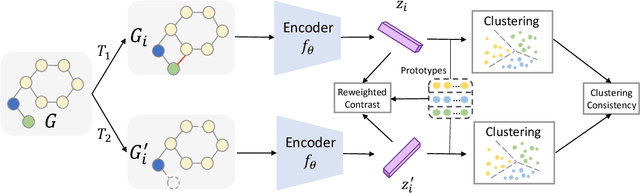
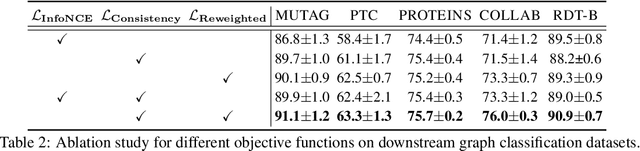
Graph-level representations are critical in various real-world applications, such as predicting the properties of molecules. But in practice, precise graph annotations are generally very expensive and time-consuming. To address this issue, graph contrastive learning constructs instance discrimination task which pulls together positive pairs (augmentation pairs of the same graph) and pushes away negative pairs (augmentation pairs of different graphs) for unsupervised representation learning. However, since for a query, its negatives are uniformly sampled from all graphs, existing methods suffer from the critical sampling bias issue, i.e., the negatives likely having the same semantic structure with the query, leading to performance degradation. To mitigate this sampling bias issue, in this paper, we propose a Prototypical Graph Contrastive Learning (PGCL) approach. Specifically, PGCL models the underlying semantic structure of the graph data via clustering semantically similar graphs into the same group, and simultaneously encourages the clustering consistency for different augmentations of the same graph. Then given a query, it performs negative sampling via drawing the graphs from those clusters that differ from the cluster of query, which ensures the semantic difference between query and its negative samples. Moreover, for a query, PGCL further reweights its negative samples based on the distance between their prototypes (cluster centroids) and the query prototype such that those negatives having moderate prototype distance enjoy relatively large weights. This reweighting strategy is proved to be more effective than uniform sampling. Experimental results on various graph benchmarks testify the advantages of our PGCL over state-of-the-art methods.
Graph-Evolving Meta-Learning for Low-Resource Medical Dialogue Generation
Dec 22, 2020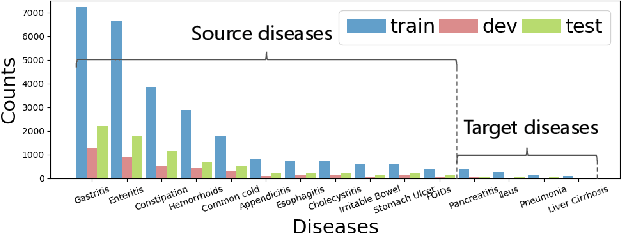
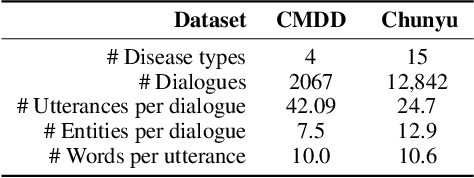
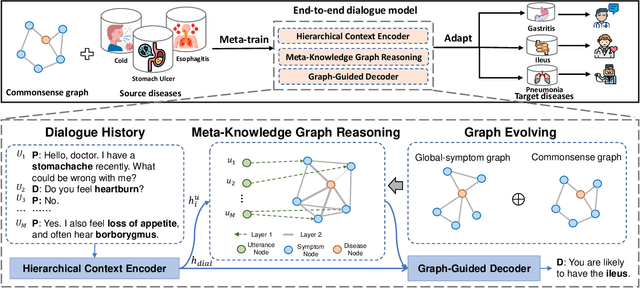
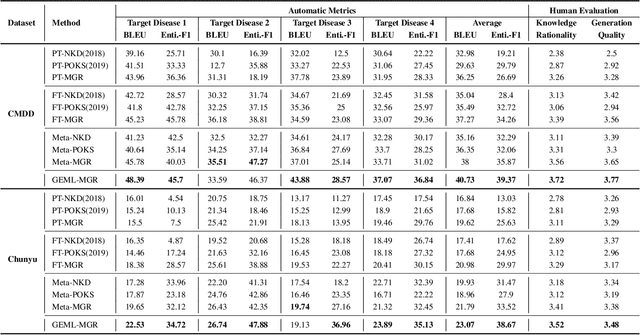
Human doctors with well-structured medical knowledge can diagnose a disease merely via a few conversations with patients about symptoms. In contrast, existing knowledge-grounded dialogue systems often require a large number of dialogue instances to learn as they fail to capture the correlations between different diseases and neglect the diagnostic experience shared among them. To address this issue, we propose a more natural and practical paradigm, i.e., low-resource medical dialogue generation, which can transfer the diagnostic experience from source diseases to target ones with a handful of data for adaptation. It is capitalized on a commonsense knowledge graph to characterize the prior disease-symptom relations. Besides, we develop a Graph-Evolving Meta-Learning (GEML) framework that learns to evolve the commonsense graph for reasoning disease-symptom correlations in a new disease, which effectively alleviates the needs of a large number of dialogues. More importantly, by dynamically evolving disease-symptom graphs, GEML also well addresses the real-world challenges that the disease-symptom correlations of each disease may vary or evolve along with more diagnostic cases. Extensive experiment results on the CMDD dataset and our newly-collected Chunyu dataset testify the superiority of our approach over state-of-the-art approaches. Besides, our GEML can generate an enriched dialogue-sensitive knowledge graph in an online manner, which could benefit other tasks grounded on knowledge graph.
Iterative Graph Self-Distillation
Oct 23, 2020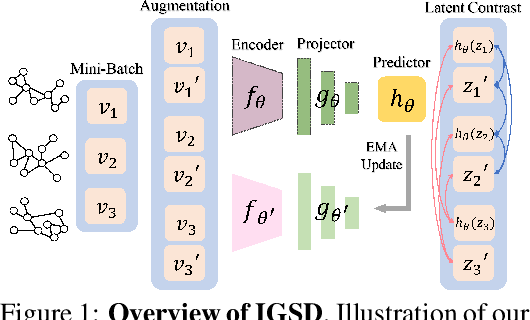

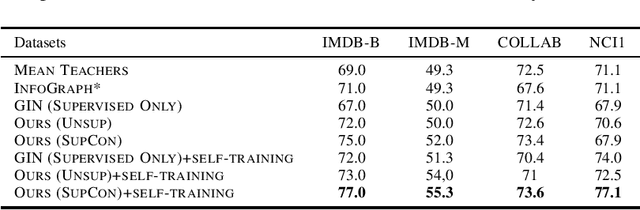
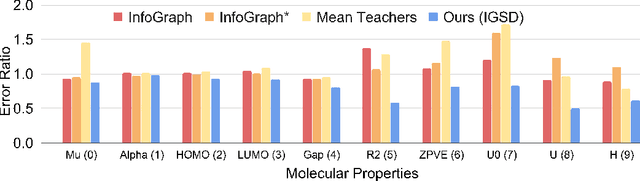
How to discriminatively vectorize graphs is a fundamental challenge that attracts increasing attentions in recent years. Inspired by the recent success of unsupervised contrastive learning, we aim to learn graph-level representation in an unsupervised manner. Specifically, we propose a novel unsupervised graph learning paradigm called Iterative Graph Self-Distillation (IGSD) which iteratively performs the teacher-student distillation with graph augmentations. Different from conventional knowledge distillation, IGSD constructs the teacher with an exponential moving average of the student model and distills the knowledge of itself. The intuition behind IGSD is to predict the teacher network representation of the graph pairs under different augmented views. As a natural extension, we also apply IGSD to semi-supervised scenarios by jointly regularizing the network with both supervised and unsupervised contrastive loss. Finally, we show that finetuning the IGSD-trained models with self-training can further improve the graph representation power. Empirically, we achieve significant and consistent performance gain on various graph datasets in both unsupervised and semi-supervised settings, which well validates the superiority of IGSD.