 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoniRefer: A Real-world Large-scale Multi-modal Dataset based on Roadside Infrastructure for 3D Visual Grounding
Dec 31, 20253D visual grounding aims to localize the object in 3D point cloud scenes that semantically corresponds to given natural language sentences. It is very critical for roadside infrastructure system to interpret natural languages and localize relevant target objects in complex traffic environments. However, most existing datasets and approaches for 3D visual grounding focus on the indoor and outdoor driving scenes, outdoor monitoring scenarios remain unexplored due to scarcity of paired point cloud-text data captured by roadside infrastructure sensors. In this paper, we introduce a novel task of 3D Visual Grounding for Outdoor Monitoring Scenarios, which enables infrastructure-level understanding of traffic scenes beyond the ego-vehicle perspective. To support this task, we construct MoniRefer, the first real-world large-scale multi-modal dataset for roadside-level 3D visual grounding. The dataset consists of about 136,018 objects with 411,128 natural language expressions collected from multiple complex traffic intersections in the real-world environments. To ensure the quality and accuracy of the dataset, we manually verified all linguistic descriptions and 3D labels for objects. Additionally, we also propose a new end-to-end method, named Moni3DVG, which utilizes the rich appearance information provided by images and geometry and optical information from point cloud for multi-modal feature learning and 3D object localization. Extensive experiments and ablation studies on the proposed benchmarks demonstrate the superiority and effectiveness of our method. Our dataset and code will be released.
Meta R-CNN : Towards General Solver for Instance-level Low-shot Learning
Sep 28, 2019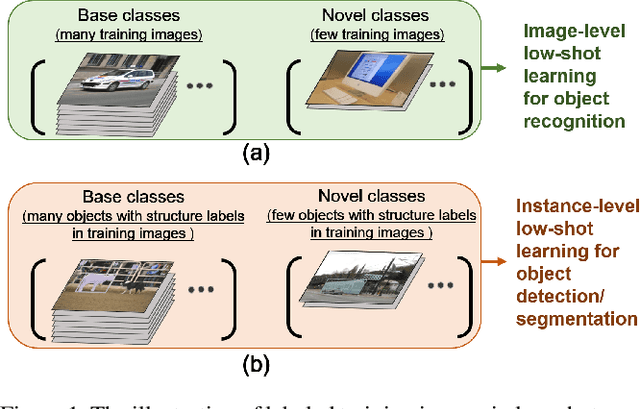
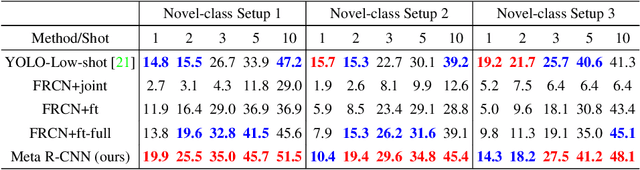
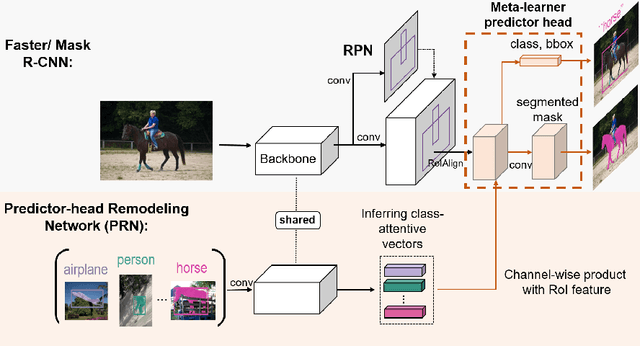
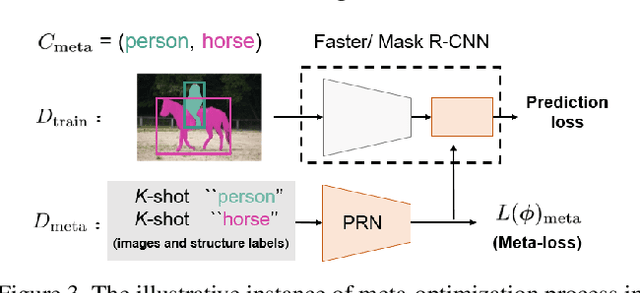
Resembling the rapid learning capability of human, low-shot learning empowers vision systems to understand new concepts by training with few samples. Leading approaches derived from meta-learning on images with a single visual object. Obfuscated by a complex background and multiple objects in one image, they are hard to promote the research of low-shot object detection/segmentation. In this work, we present a flexible and general methodology to achieve these tasks. Our work extends Faster /Mask R-CNN by proposing meta-learning over RoI (Region-of-Interest) features instead of a full image feature. This simple spirit disentangles multi-object information merged with the background, without bells and whistles, enabling Faster /Mask R-CNN turn into a meta-learner to achieve the tasks. Specifically, we introduce a Predictor-head Remodeling Network (PRN) that shares its main backbone with Faster /Mask R-CNN. PRN receives images containing low-shot objects with their bounding boxes or masks to infer their class attentive vectors. The vectors take channel-wise soft-attention on RoI features, remodeling those R-CNN predictor heads to detect or segment the objects that are consistent with the classes these vectors represent. In our experiments, Meta R-CNN yields the state of the art in low-shot object detection and improves low-shot object segmentation by Mask R-CNN.