 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Single Scan to Sequential Consistency: A New Paradigm for LIDAR Relocalization
Feb 03, 2026LiDAR relocalization aims to estimate the global 6-DoF pose of a sensor in the environment. However, existing regression-based approaches are prone to dynamic or ambiguous scenarios, as they either solely rely on single-frame inference or neglect the spatio-temporal consistency across scans. In this paper, we propose TempLoc, a new LiDAR relocalization framework that enhances the robustness of localization by effectively modeling sequential consistency. Specifically, a Global Coordinate Estimation module is first introduced to predict point-wise global coordinates and associated uncertainties for each LiDAR scan. A Prior Coordinate Generation module is then presented to estimate inter-frame point correspondences by the attention mechanism. Lastly, an Uncertainty-Guided Coordinate Fusion module is deployed to integrate both predictions of point correspondence in an end-to-end fashion, yielding a more temporally consistent and accurate global 6-DoF pose. Experimental results on the NCLT and Oxford Robot-Car benchmarks show that our TempLoc outperforms stateof-the-art methods by a large margin, demonstrating the effectiveness of temporal-aware correspondence modeling in LiDAR relocalization. Our code will be released soon.
MoniRefer: A Real-world Large-scale Multi-modal Dataset based on Roadside Infrastructure for 3D Visual Grounding
Dec 31, 20253D visual grounding aims to localize the object in 3D point cloud scenes that semantically corresponds to given natural language sentences. It is very critical for roadside infrastructure system to interpret natural languages and localize relevant target objects in complex traffic environments. However, most existing datasets and approaches for 3D visual grounding focus on the indoor and outdoor driving scenes, outdoor monitoring scenarios remain unexplored due to scarcity of paired point cloud-text data captured by roadside infrastructure sensors. In this paper, we introduce a novel task of 3D Visual Grounding for Outdoor Monitoring Scenarios, which enables infrastructure-level understanding of traffic scenes beyond the ego-vehicle perspective. To support this task, we construct MoniRefer, the first real-world large-scale multi-modal dataset for roadside-level 3D visual grounding. The dataset consists of about 136,018 objects with 411,128 natural language expressions collected from multiple complex traffic intersections in the real-world environments. To ensure the quality and accuracy of the dataset, we manually verified all linguistic descriptions and 3D labels for objects. Additionally, we also propose a new end-to-end method, named Moni3DVG, which utilizes the rich appearance information provided by images and geometry and optical information from point cloud for multi-modal feature learning and 3D object localization. Extensive experiments and ablation studies on the proposed benchmarks demonstrate the superiority and effectiveness of our method. Our dataset and code will be released.
DropoutGS: Dropping Out Gaussians for Better Sparse-view Rendering
Apr 13, 2025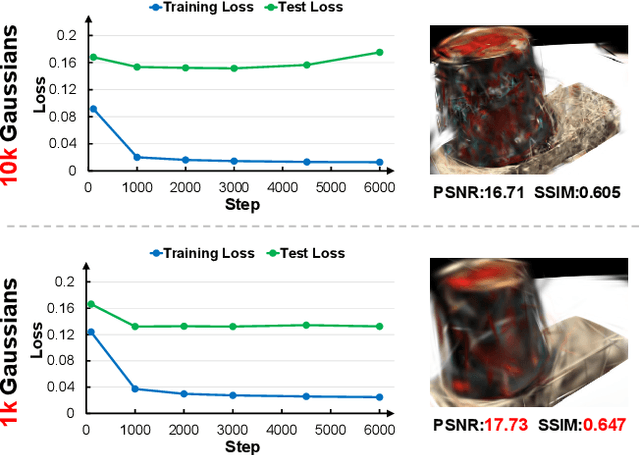
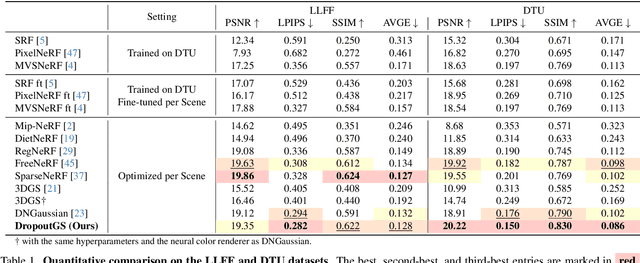

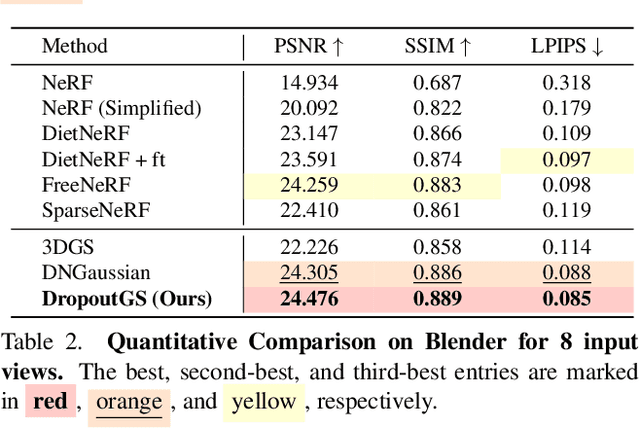
Although 3D Gaussian Splatting (3DGS) has demonstrated promising results in novel view synthesis, its performance degrades dramatically with sparse inputs and generates undesirable artifacts. As the number of training views decreases, the novel view synthesis task degrades to a highly under-determined problem such that existing methods suffer from the notorious overfitting issue. Interestingly, we observe that models with fewer Gaussian primitives exhibit less overfitting under sparse inputs. Inspired by this observation, we propose a Random Dropout Regularization (RDR) to exploit the advantages of low-complexity models to alleviate overfitting. In addition, to remedy the lack of high-frequency details for these models, an Edge-guided Splitting Strategy (ESS) is developed. With these two techniques, our method (termed DropoutGS) provides a simple yet effective plug-in approach to improve the generalization performance of existing 3DGS methods. Extensive experiments show that our DropoutGS produces state-of-the-art performance under sparse views on benchmark datasets including Blender, LLFF, and DTU. The project page is at: https://xuyx55.github.io/DropoutGS/.
Progressive Correspondence Regenerator for Robust 3D Registration
Feb 04, 2025



Obtaining enough high-quality correspondences is crucial for robust registration. Existing correspondence refinement methods mostly follow the paradigm of outlier removal, which either fails to correctly identify the accurate correspondences under extreme outlier ratios, or select too few correct correspondences to support robust registration. To address this challenge, we propose a novel approach named Regor, which is a progressive correspondence regenerator that generates higher-quality matches whist sufficiently robust for numerous outliers. In each iteration, we first apply prior-guided local grouping and generalized mutual matching to generate the local region correspondences. A powerful center-aware three-point consistency is then presented to achieve local correspondence correction, instead of removal. Further, we employ global correspondence refinement to obtain accurate correspondences from a global perspective. Through progressive iterations, this process yields a large number of high-quality correspondences. Extensive experiments on both indoor and outdoor datasets demonstrate that the proposed Regor significantly outperforms existing outlier removal techniques. More critically, our approach obtain 10 times more correct correspondences than outlier removal methods. As a result, our method is able to achieve robust registration even with weak features. The code will be released.
Layout2Scene: 3D Semantic Layout Guided Scene Generation via Geometry and Appearance Diffusion Priors
Jan 05, 20253D scene generation conditioned on text prompts has significantly progressed due to the development of 2D diffusion generation models. However, the textual description of 3D scenes is inherently inaccurate and lacks fine-grained control during training, leading to implausible scene generation. As an intuitive and feasible solution, the 3D layout allows for precise specification of object locations within the scene. To this end, we present a text-to-scene generation method (namely, Layout2Scene) using additional semantic layout as the prompt to inject precise control of 3D object positions. Specifically, we first introduce a scene hybrid representation to decouple objects and backgrounds, which is initialized via a pre-trained text-to-3D model. Then, we propose a two-stage scheme to optimize the geometry and appearance of the initialized scene separately. To fully leverage 2D diffusion priors in geometry and appearance generation, we introduce a semantic-guided geometry diffusion model and a semantic-geometry guided diffusion model which are finetuned on a scene dataset. Extensive experiments demonstrate that our method can generate more plausible and realistic scenes as compared to state-of-the-art approaches. Furthermore, the generated scene allows for flexible yet precise editing, thereby facilitating multiple downstream applications.
SpinNet: Learning a General Surface Descriptor for 3D Point Cloud Registration
Nov 24, 2020



Extracting robust and general 3D local features is key to downstream tasks such as point cloud registration and reconstruction. Existing learning-based local descriptors are either sensitive to rotation transformations, or rely on classical handcrafted features which are neither general nor representative. In this paper, we introduce a new, yet conceptually simple, neural architecture, termed SpinNet, to extract local features which are rotationally invariant whilst sufficiently informative to enable accurate registration. A Spatial Point Transformer is first introduced to map the input local surface into a carefully designed cylindrical space, enabling end-to-end optimization with SO(2) equivariant representation. A Neural Feature Extractor which leverages the powerful point-based and 3D cylindrical convolutional neural layers is then utilized to derive a compact and representative descriptor for matching. Extensive experiments on both indoor and outdoor datasets demonstrate that SpinNet outperforms existing state-of-the-art techniques by a large margin. More critically, it has the best generalization ability across unseen scenarios with different sensor modalities. The code is available at https://github.com/QingyongHu/SpinNet.