 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMimic: Speaking Style Disentanglement for Speech-Driven 3D Facial Animation
Dec 18, 2023Speech-driven 3D facial animation aims to synthesize vivid facial animations that accurately synchronize with speech and match the unique speaking style. However, existing works primarily focus on achieving precise lip synchronization while neglecting to model the subject-specific speaking style, often resulting in unrealistic facial animations. To the best of our knowledge, this work makes the first attempt to explore the coupled information between the speaking style and the semantic content in facial motions. Specifically, we introduce an innovative speaking style disentanglement method, which enables arbitrary-subject speaking style encoding and leads to a more realistic synthesis of speech-driven facial animations. Subsequently, we propose a novel framework called \textbf{Mimic} to learn disentangled representations of the speaking style and content from facial motions by building two latent spaces for style and content, respectively. Moreover, to facilitate disentangled representation learning, we introduce four well-designed constraints: an auxiliary style classifier, an auxiliary inverse classifier, a content contrastive loss, and a pair of latent cycle losses, which can effectively contribute to the construction of the identity-related style space and semantic-related content space. Extensive qualitative and quantitative experiments conducted on three publicly available datasets demonstrate that our approach outperforms state-of-the-art methods and is capable of capturing diverse speaking styles for speech-driven 3D facial animation. The source code and supplementary video are publicly available at: https://zeqing-wang.github.io/Mimic/
Wav-BERT: Cooperative Acoustic and Linguistic Representation Learning for Low-Resource Speech Recognition
Oct 09, 2021
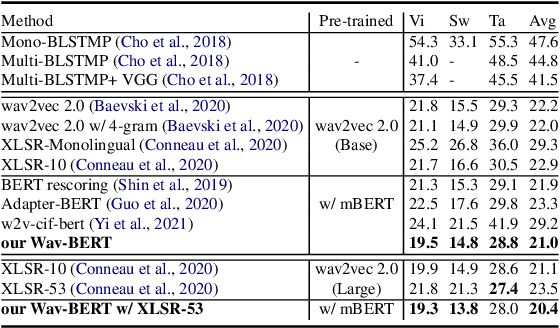
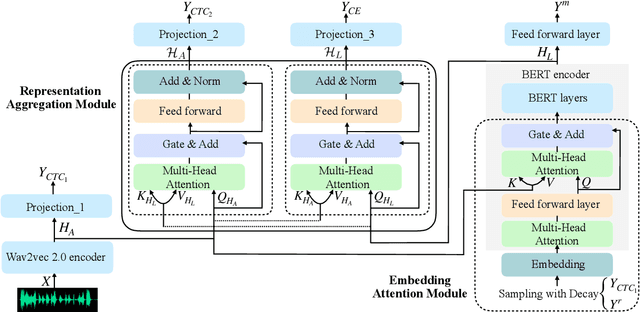
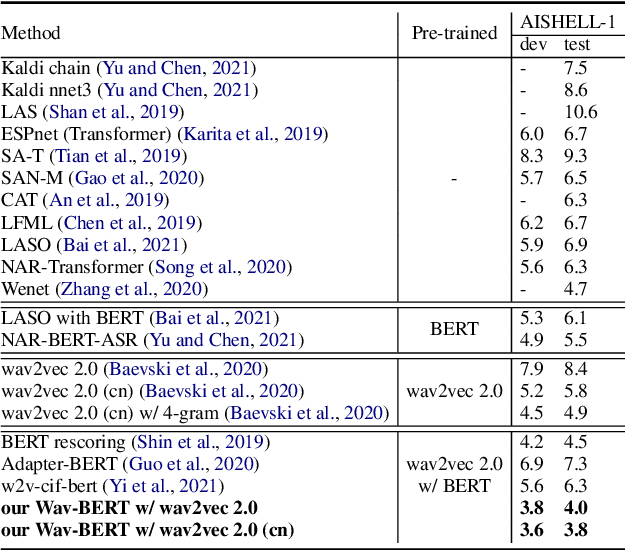
Unifying acoustic and linguistic representation learning has become increasingly crucial to transfer the knowledge learned on the abundance of high-resource language data for low-resource speech recognition. Existing approaches simply cascade pre-trained acoustic and language models to learn the transfer from speech to text. However, how to solve the representation discrepancy of speech and text is unexplored, which hinders the utilization of acoustic and linguistic information. Moreover, previous works simply replace the embedding layer of the pre-trained language model with the acoustic features, which may cause the catastrophic forgetting problem. In this work, we introduce Wav-BERT, a cooperative acoustic and linguistic representation learning method to fuse and utilize the contextual information of speech and text. Specifically, we unify a pre-trained acoustic model (wav2vec 2.0) and a language model (BERT) into an end-to-end trainable framework. A Representation Aggregation Module is designed to aggregate acoustic and linguistic representation, and an Embedding Attention Module is introduced to incorporate acoustic information into BERT, which can effectively facilitate the cooperation of two pre-trained models and thus boost the representation learning. Extensive experiments show that our Wav-BERT significantly outperforms the existing approaches and achieves state-of-the-art performance on low-resource speech recognition.
Graphonomy: Universal Image Parsing via Graph Reasoning and Transfer
Jan 26, 2021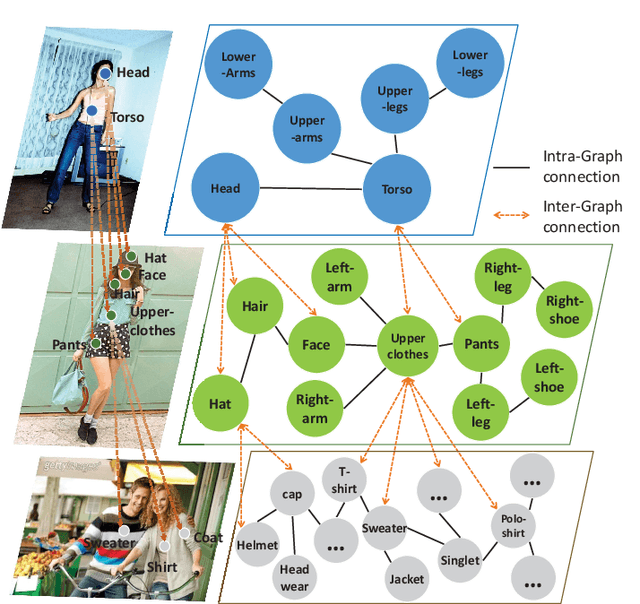


Prior highly-tuned image parsing models are usually studied in a certain domain with a specific set of semantic labels and can hardly be adapted into other scenarios (e.g., sharing discrepant label granularity) without extensive re-training. Learning a single universal parsing model by unifying label annotations from different domains or at various levels of granularity is a crucial but rarely addressed topic. This poses many fundamental learning challenges, e.g., discovering underlying semantic structures among different label granularity or mining label correlation across relevant tasks. To address these challenges, we propose a graph reasoning and transfer learning framework, named "Graphonomy", which incorporates human knowledge and label taxonomy into the intermediate graph representation learning beyond local convolutions. In particular, Graphonomy learns the global and structured semantic coherency in multiple domains via semantic-aware graph reasoning and transfer, enforcing the mutual benefits of the parsing across domains (e.g., different datasets or co-related tasks). The Graphonomy includes two iterated modules: Intra-Graph Reasoning and Inter-Graph Transfer modules. The former extracts the semantic graph in each domain to improve the feature representation learning by propagating information with the graph; the latter exploits the dependencies among the graphs from different domains for bidirectional knowledge transfer. We apply Graphonomy to two relevant but different image understanding research topics: human parsing and panoptic segmentation, and show Graphonomy can handle both of them well via a standard pipeline against current state-of-the-art approaches. Moreover, some extra benefit of our framework is demonstrated, e.g., generating the human parsing at various levels of granularity by unifying annotations across different datasets.
Adversarial Meta Sampling for Multilingual Low-Resource Speech Recognition
Dec 23, 2020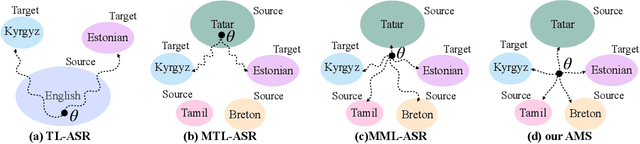
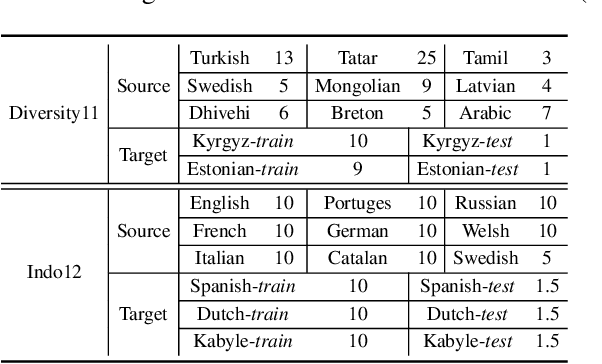
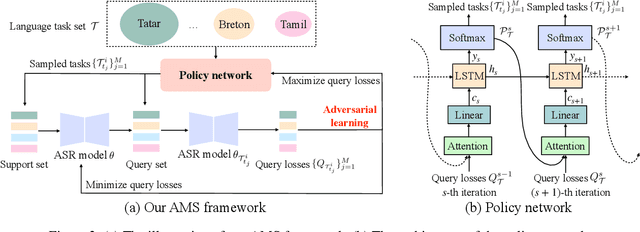
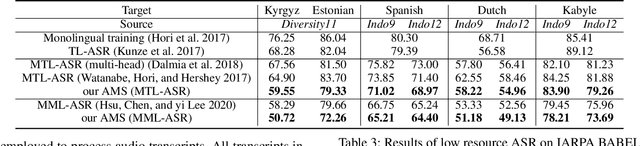
Low-resource automatic speech recognition (ASR) is challenging, as the low-resource target language data cannot well train an ASR model. To solve this issue, meta-learning formulates ASR for each source language into many small ASR tasks and meta-learns a model initialization on all tasks from different source languages to access fast adaptation on unseen target languages. However, for different source languages, the quantity and difficulty vary greatly because of their different data scales and diverse phonological systems, which leads to task-quantity and task-difficulty imbalance issues and thus a failure of multilingual meta-learning ASR (MML-ASR). In this work, we solve this problem by developing a novel adversarial meta sampling (AMS) approach to improve MML-ASR. When sampling tasks in MML-ASR, AMS adaptively determines the task sampling probability for each source language. Specifically, for each source language, if the query loss is large, it means that its tasks are not well sampled to train ASR model in terms of its quantity and difficulty and thus should be sampled more frequently for extra learning. Inspired by this fact, we feed the historical task query loss of all source language domain into a network to learn a task sampling policy for adversarially increasing the current query loss of MML-ASR. Thus, the learnt task sampling policy can master the learning situation of each language and thus predicts good task sampling probability for each language for more effective learning. Finally, experiment results on two multilingual datasets show significant performance improvement when applying our AMS on MML-ASR, and also demonstrate the applicability of AMS to other low-resource speech tasks and transfer learning ASR approaches. Our codes are available at: https://github.com/iamxiaoyubei/AMS.
Photometric Multi-View Mesh Refinement for High-Resolution Satellite Images
May 12, 2020
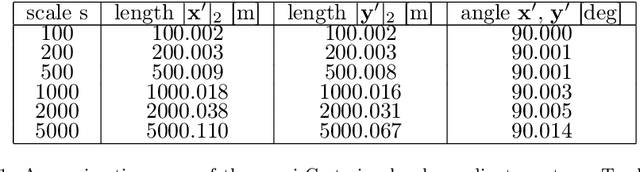

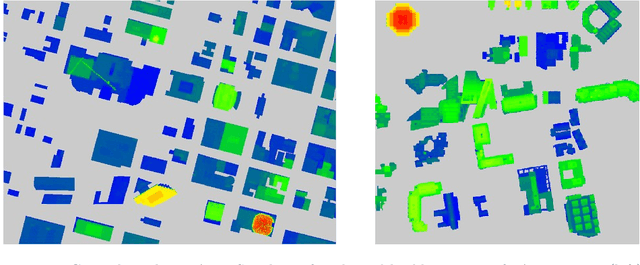
Modern high-resolution satellite sensors collect optical imagery with ground sampling distances (GSDs) of 30-50cm, which has sparked a renewed interest in photogrammetric 3D surface reconstruction from satellite data. State-of-the-art reconstruction methods typically generate 2.5D elevation data. Here, we present an approach to recover full 3D surface meshes from multi-view satellite imagery. The proposed method takes as input a coarse initial mesh and refines it by iteratively updating all vertex positions to maximize the photo-consistency between images. Photo-consistency is measured in image space, by transferring texture from one image to another via the surface. We derive the equations to propagate changes in texture similarity through the rational function model (RFM), often also referred to as rational polynomial coefficient (RPC) model. Furthermore, we devise a hierarchical scheme to optimize the surface with gradient descent. In experiments with two different datasets, we show that the refinement improves the initial digital elevation models (DEMs) generated with conventional dense image matching. Moreover, we demonstrate that our method is able to reconstruct true 3D geometry, such as facade structures, if off-nadir views are available.
Bidirectional Graph Reasoning Network for Panoptic Segmentation
Apr 14, 2020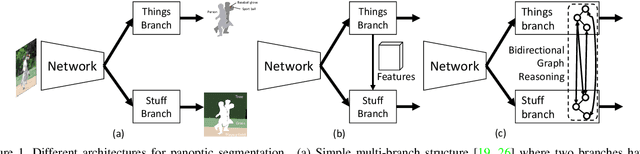
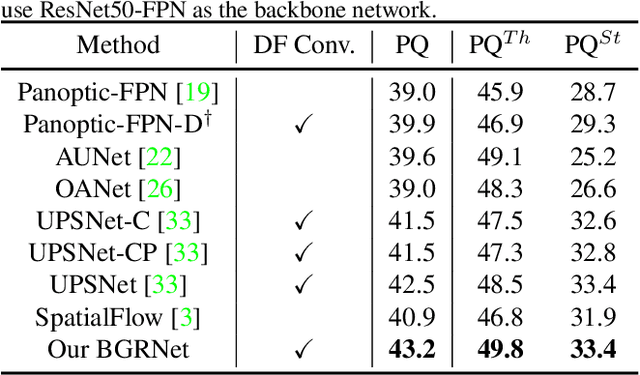
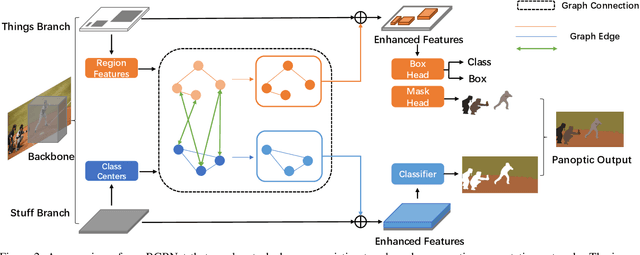

Recent researches on panoptic segmentation resort to a single end-to-end network to combine the tasks of instance segmentation and semantic segmentation. However, prior models only unified the two related tasks at the architectural level via a multi-branch scheme or revealed the underlying correlation between them by unidirectional feature fusion, which disregards the explicit semantic and co-occurrence relations among objects and background. Inspired by the fact that context information is critical to recognize and localize the objects, and inclusive object details are significant to parse the background scene, we thus investigate on explicitly modeling the correlations between object and background to achieve a holistic understanding of an image in the panoptic segmentation task. We introduce a Bidirectional Graph Reasoning Network (BGRNet), which incorporates graph structure into the conventional panoptic segmentation network to mine the intra-modular and intermodular relations within and between foreground things and background stuff classes. In particular, BGRNet first constructs image-specific graphs in both instance and semantic segmentation branches that enable flexible reasoning at the proposal level and class level, respectively. To establish the correlations between separate branches and fully leverage the complementary relations between things and stuff, we propose a Bidirectional Graph Connection Module to diffuse information across branches in a learnable fashion. Experimental results demonstrate the superiority of our BGRNet that achieves the new state-of-the-art performance on challenging COCO and ADE20K panoptic segmentation benchmarks.
Layout-Graph Reasoning for Fashion Landmark Detection
Oct 04, 2019
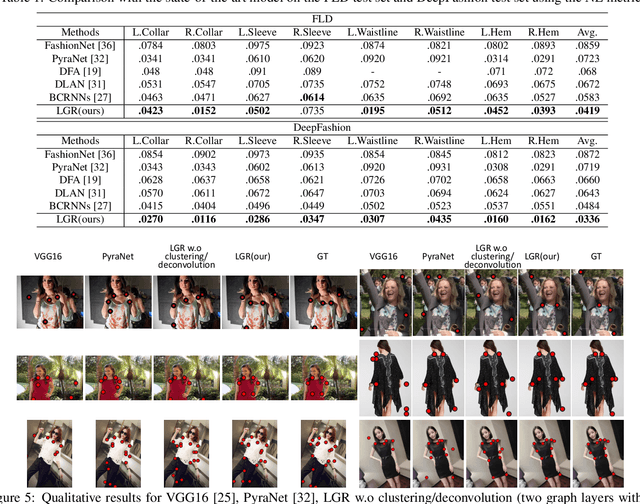

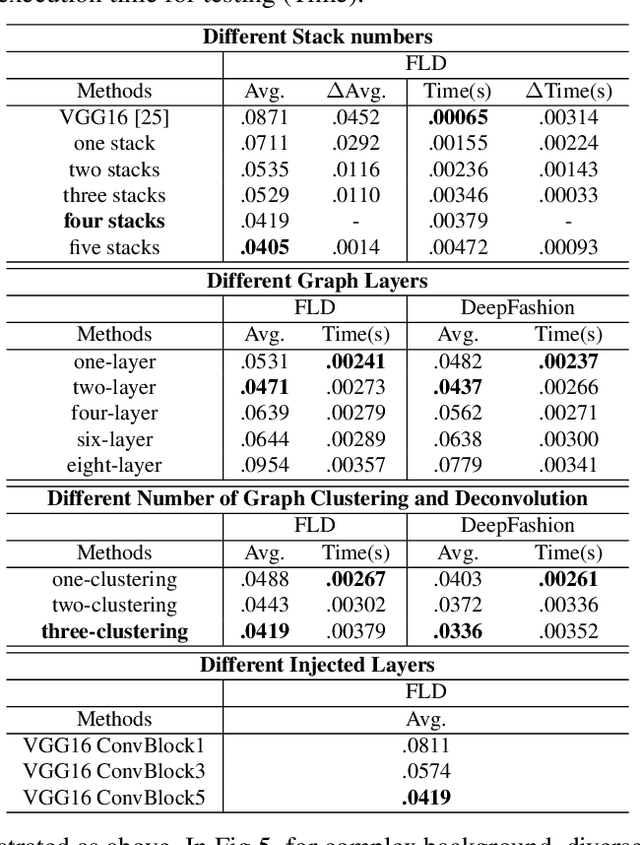
Detecting dense landmarks for diverse clothes, as a fundamental technique for clothes analysis, has attracted increasing research attention due to its huge application potential. However, due to the lack of modeling underlying semantic layout constraints among landmarks, prior works often detect ambiguous and structure-inconsistent landmarks of multiple overlapped clothes in one person. In this paper, we propose to seamlessly enforce structural layout relationships among landmarks on the intermediate representations via multiple stacked layout-graph reasoning layers. We define the layout-graph as a hierarchical structure including a root node, body-part nodes (e.g. upper body, lower body), coarse clothes-part nodes (e.g. collar, sleeve) and leaf landmark nodes (e.g. left-collar, right-collar). Each Layout-Graph Reasoning(LGR) layer aims to map feature representations into structural graph nodes via a Map-to-Node module, performs reasoning over structural graph nodes to achieve global layout coherency via a layout-graph reasoning module, and then maps graph nodes back to enhance feature representations via a Node-to-Map module. The layout-graph reasoning module integrates a graph clustering operation to generate representations of intermediate nodes (bottom-up inference) and then a graph deconvolution operation (top-down inference) over the whole graph. Extensive experiments on two public fashion landmark datasets demonstrate the superiority of our model. Furthermore, to advance the fine-grained fashion landmark research for supporting more comprehensive clothes generation and attribute recognition, we contribute the first Fine-grained Fashion Landmark Dataset (FFLD) containing 200k images annotated with at most 32 key-points for 13 clothes types.
Graphonomy: Universal Human Parsing via Graph Transfer Learning
Apr 09, 2019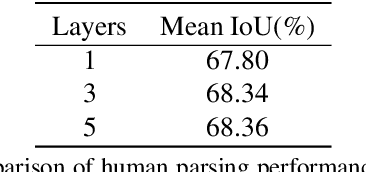



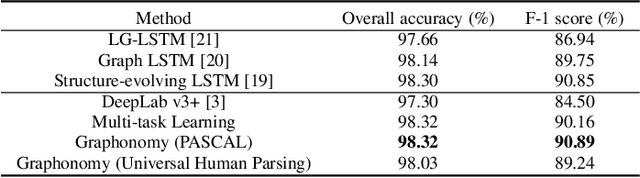
Prior highly-tuned human parsing models tend to fit towards each dataset in a specific domain or with discrepant label granularity, and can hardly be adapted to other human parsing tasks without extensive re-training. In this paper, we aim to learn a single universal human parsing model that can tackle all kinds of human parsing needs by unifying label annotations from different domains or at various levels of granularity. This poses many fundamental learning challenges, e.g. discovering underlying semantic structures among different label granularity, performing proper transfer learning across different image domains, and identifying and utilizing label redundancies across related tasks. To address these challenges, we propose a new universal human parsing agent, named "Graphonomy", which incorporates hierarchical graph transfer learning upon the conventional parsing network to encode the underlying label semantic structures and propagate relevant semantic information. In particular, Graphonomy first learns and propagates compact high-level graph representation among the labels within one dataset via Intra-Graph Reasoning, and then transfers semantic information across multiple datasets via Inter-Graph Transfer. Various graph transfer dependencies (\eg, similarity, linguistic knowledge) between different datasets are analyzed and encoded to enhance graph transfer capability. By distilling universal semantic graph representation to each specific task, Graphonomy is able to predict all levels of parsing labels in one system without piling up the complexity. Experimental results show Graphonomy effectively achieves the state-of-the-art results on three human parsing benchmarks as well as advantageous universal human parsing performance.
End-to-End Knowledge-Routed Relational Dialogue System for Automatic Diagnosis
Mar 18, 2019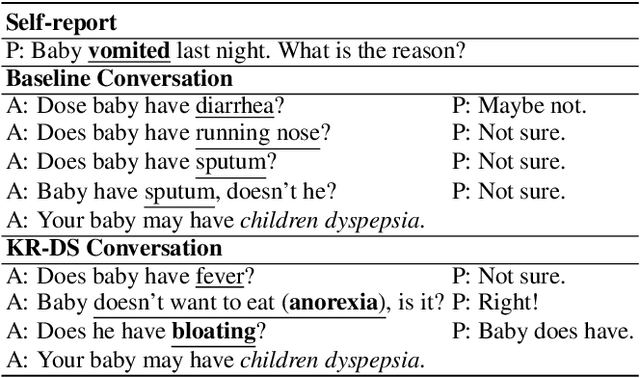
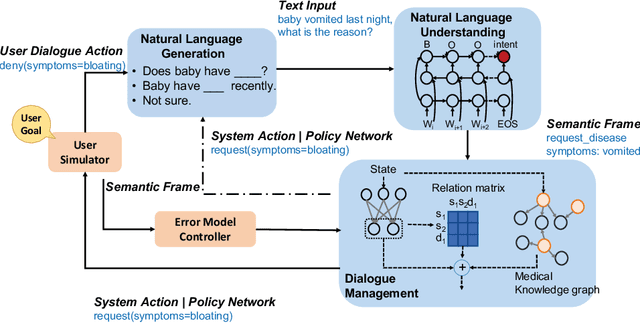
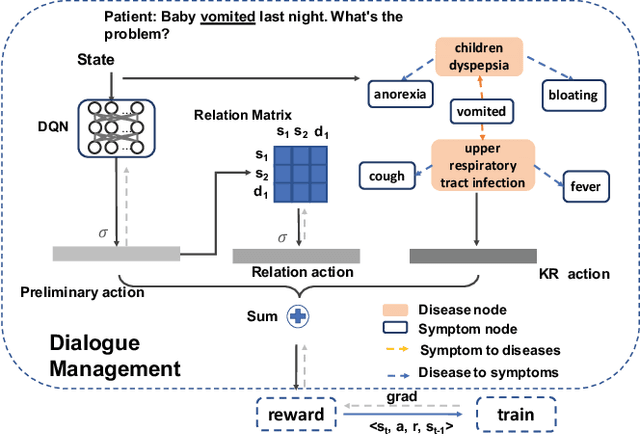

Beyond current conversational chatbots or task-oriented dialogue systems that have attracted increasing attention, we move forward to develop a dialogue system for automatic medical diagnosis that converses with patients to collect additional symptoms beyond their self-reports and automatically makes a diagnosis. Besides the challenges for conversational dialogue systems (e.g. topic transition coherency and question understanding), automatic medical diagnosis further poses more critical requirements for the dialogue rationality in the context of medical knowledge and symptom-disease relations. Existing dialogue systems (Madotto, Wu, and Fung 2018; Wei et al. 2018; Li et al. 2017) mostly rely on data-driven learning and cannot be able to encode extra expert knowledge graph. In this work, we propose an End-to-End Knowledge-routed Relational Dialogue System (KR-DS) that seamlessly incorporates rich medical knowledge graph into the topic transition in dialogue management, and makes it cooperative with natural language understanding and natural language generation. A novel Knowledge-routed Deep Q-network (KR-DQN) is introduced to manage topic transitions, which integrates a relational refinement branch for encoding relations among different symptoms and symptom-disease pairs, and a knowledge-routed graph branch for topic decision-making. Extensive experiments on a public medical dialogue dataset show our KR-DS significantly beats state-of-the-art methods (by more than 8% in diagnosis accuracy). We further show the superiority of our KR-DS on a newly collected medical dialogue system dataset, which is more challenging retaining original self-reports and conversational data between patients and doctors.
Soft-Gated Warping-GAN for Pose-Guided Person Image Synthesis
Oct 27, 2018
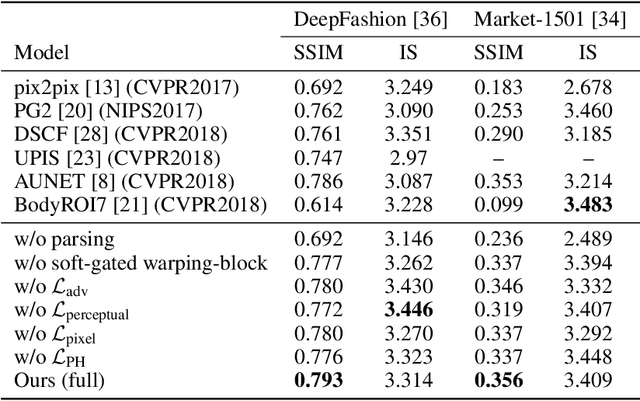
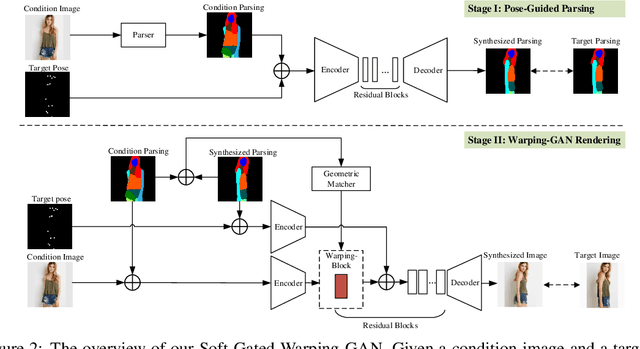

Despite remarkable advances in image synthesis research, existing works often fail in manipulating images under the context of large geometric transformations. Synthesizing person images conditioned on arbitrary poses is one of the most representative examples where the generation quality largely relies on the capability of identifying and modeling arbitrary transformations on different body parts. Current generative models are often built on local convolutions and overlook the key challenges (e.g. heavy occlusions, different views or dramatic appearance changes) when distinct geometric changes happen for each part, caused by arbitrary pose manipulations. This paper aims to resolve these challenges induced by geometric variability and spatial displacements via a new Soft-Gated Warping Generative Adversarial Network (Warping-GAN), which is composed of two stages: 1) it first synthesizes a target part segmentation map given a target pose, which depicts the region-level spatial layouts for guiding image synthesis with higher-level structure constraints; 2) the Warping-GAN equipped with a soft-gated warping-block learns feature-level mapping to render textures from the original image into the generated segmentation map. Warping-GAN is capable of controlling different transformation degrees given distinct target poses. Moreover, the proposed warping-block is light-weight and flexible enough to be injected into any networks. Human perceptual studies and quantitative evaluations demonstrate the superiority of our Warping-GAN that significantly outperforms all existing methods on two large datasets.