 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Sample Pair Generation for Ultrasound Video Contrastive Representation Learning
Nov 25, 2020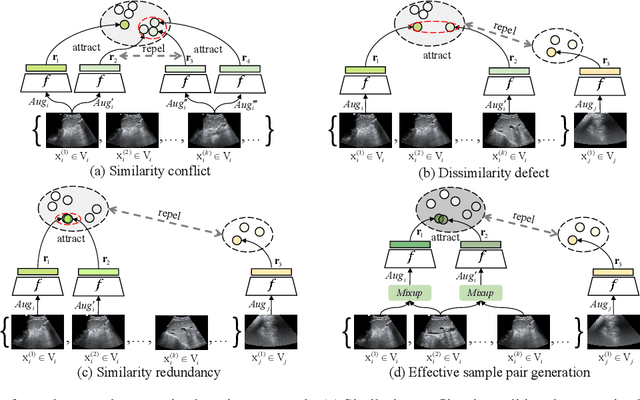

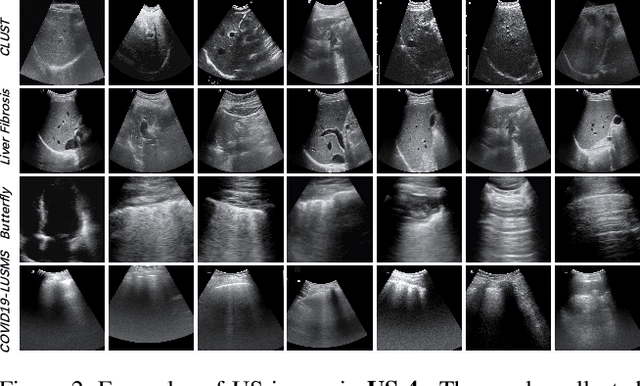

Most deep neural networks (DNNs) based ultrasound (US) medical image analysis models use pretrained backbones (e.g., ImageNet) for better model generalization. However, the domain gap between natural and medical images causes an inevitable performance bottleneck when applying to US image analysis. Our idea is to pretrain DNNs on US images directly to avoid this bottleneck. Due to the lack of annotated large-scale datasets of US images, we first construct a new large-scale US video-based image dataset named US-4, containing over 23,000 high-resolution images from four US video sub-datasets, where two sub-datasets are newly collected by our local experienced doctors. To make full use of this dataset, we then innovatively propose an US semi-supervised contrastive learning (USCL) method to effectively learn feature representations of US images, with a new sample pair generation (SPG) scheme to tackle the problem that US images extracted from videos have high similarities. Moreover, the USCL treats contrastive loss as a consistent regularization, which boosts the performance of pretrained backbones by combining the supervised loss in a mutually reinforcing way. Extensive experiments on down-stream tasks' fine-tuning show the superiority of our approach against ImageNet pretraining and pretraining using previous state-of-the-art semi-supervised learning approaches. In particular, our pretrained backbone gets fine-tuning accuracy of over 94%, which is 9% higher than 85% of the ImageNet pretrained model on the widely used POCUS dataset. The constructed US-4 dataset and source codes of this work will be made public.
Multi-Modal Active Learning for Automatic Liver Fibrosis Diagnosis based on Ultrasound Shear Wave Elastography
Nov 02, 2020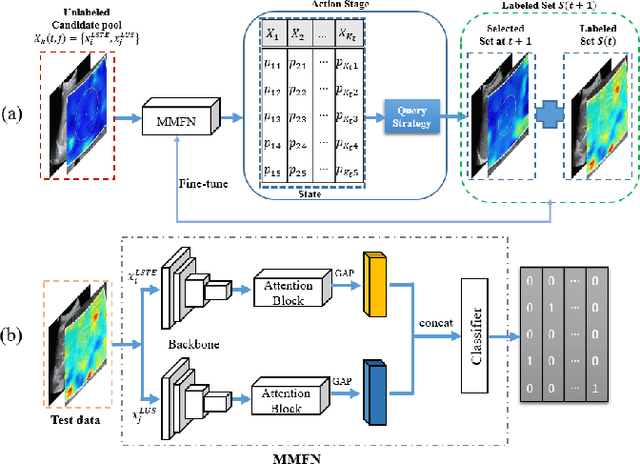
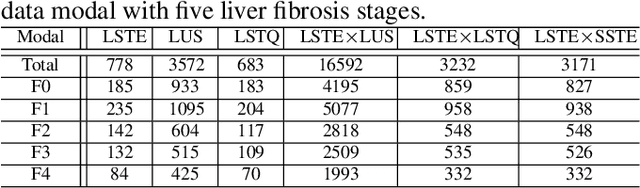
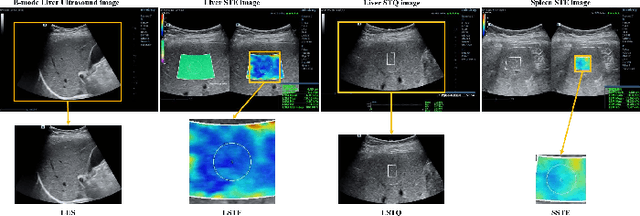
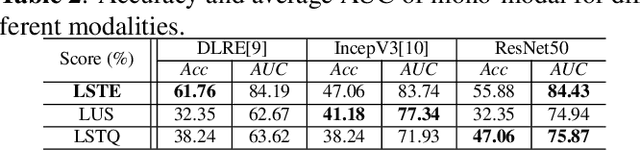
With the development of radiomics, noninvasive diagnosis like ultrasound (US) imaging plays a very important role in automatic liver fibrosis diagnosis (ALFD). Due to the noisy data, expensive annotations of US images, the application of Artificial Intelligence (AI) assisting approaches encounters a bottleneck. Besides, the use of mono-modal US data limits the further improve of the classification results. In this work, we innovatively propose a multi-modal fusion network with active learning (MMFN-AL) for ALFD to exploit the information of multiple modalities, eliminate the noisy data and reduce the annotation cost. Four image modalities including US and three types of shear wave elastography (SWEs) are exploited. A new dataset containing these modalities from 214 candidates is well-collected and pre-processed, with the labels obtained from the liver biopsy results. Experimental results show that our proposed method outperforms the state-of-the-art performance using less than 30% data, and by using only around 80% data, the proposed fusion network achieves high AUC 89.27% and accuracy 70.59%.