 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Sample Pair Generation for Ultrasound Video Contrastive Representation Learning
Nov 25, 2020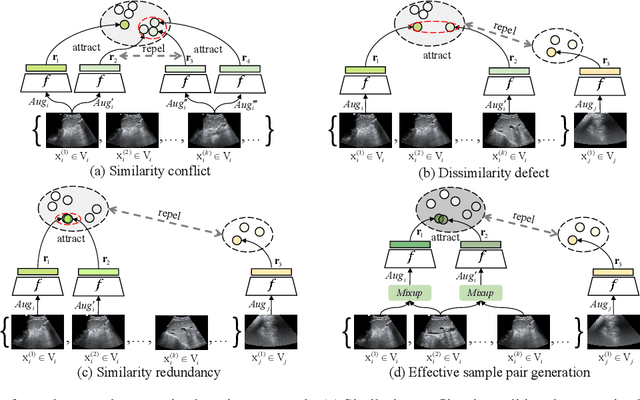

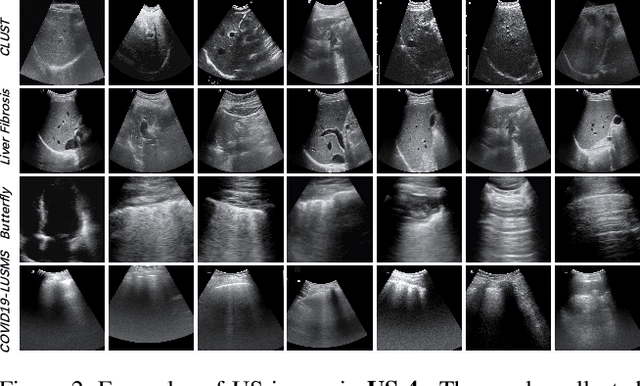

Most deep neural networks (DNNs) based ultrasound (US) medical image analysis models use pretrained backbones (e.g., ImageNet) for better model generalization. However, the domain gap between natural and medical images causes an inevitable performance bottleneck when applying to US image analysis. Our idea is to pretrain DNNs on US images directly to avoid this bottleneck. Due to the lack of annotated large-scale datasets of US images, we first construct a new large-scale US video-based image dataset named US-4, containing over 23,000 high-resolution images from four US video sub-datasets, where two sub-datasets are newly collected by our local experienced doctors. To make full use of this dataset, we then innovatively propose an US semi-supervised contrastive learning (USCL) method to effectively learn feature representations of US images, with a new sample pair generation (SPG) scheme to tackle the problem that US images extracted from videos have high similarities. Moreover, the USCL treats contrastive loss as a consistent regularization, which boosts the performance of pretrained backbones by combining the supervised loss in a mutually reinforcing way. Extensive experiments on down-stream tasks' fine-tuning show the superiority of our approach against ImageNet pretraining and pretraining using previous state-of-the-art semi-supervised learning approaches. In particular, our pretrained backbone gets fine-tuning accuracy of over 94%, which is 9% higher than 85% of the ImageNet pretrained model on the widely used POCUS dataset. The constructed US-4 dataset and source codes of this work will be made public.
Semi-Supervised Active Learning for COVID-19 Lung Ultrasound Multi-symptom Classification
Sep 09, 2020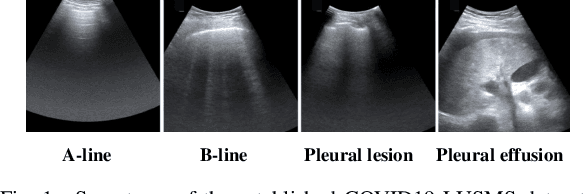
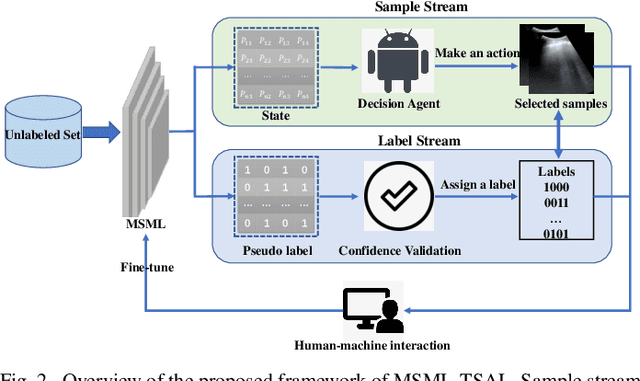
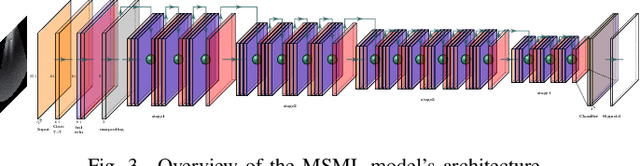
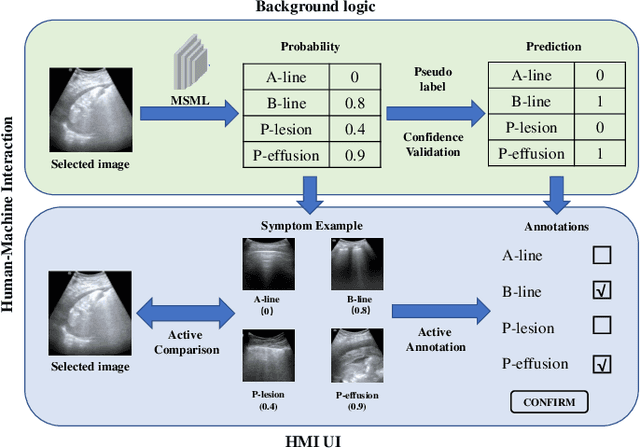
Ultrasound (US) is a non-invasive yet effective medical diagnostic imaging technique for the COVID-19 global pandemic. However, due to complex feature behaviors and expensive annotations of US images, it is difficult to apply Artificial Intelligence (AI) assisting approaches for lung's multi-symptom (multi-label) classification. To overcome these difficulties, we propose a novel semi-supervised Two-Stream Active Learning (TSAL) method to model complicated features and reduce labeling costs in an iterative procedure. The core component of TSAL is the multi-label learning mechanism, in which label correlations information is used to design multi-label margin (MLM) strategy and confidence validation for automatically selecting informative samples and confident labels. On this basis, a multi-symptom multi-label (MSML) classification network is proposed to learn discriminative features of lung symptoms, and a human-machine interaction is exploited to confirm the final annotations that are used to fine-tune MSML with progressively labeled data. Moreover, a novel lung US dataset named COVID19-LUSMS is built, currently containing 71 clinical patients with 6,836 images sampled from 678 videos. Experimental evaluations show that TSAL using only 20% data can achieve superior performance to the baseline and the state-of-the-art. Qualitatively, visualization of both attention map and sample distribution confirms the good consistency with the clinic knowledge.