 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecovery thresholds for hidden weighted sparse graphs
Jun 12, 2026Recovering structural information from noisy high-dimensional data is a fundamental task in statistical inference. We investigate the recovery thresholds for a graph hidden in a randomly weighted complete graph. Specifically, an unknown graph $H^* \in H_n$ is chosen uniformly at random, and hidden in a complete graph of $n$ vertices as follows: the weight of an edge $e \in H$ is distributed independently according to $P_n$; otherwise the weight is distributed independently according to $Q_n$. The goal is to recover almost all of $H$ from these edge weights. Assuming a local Lipschitzness of the Rényi divergence between distributions $P_n$ and $Q_n$, and a mild density condition for the graphs $H_n$, we give a unified characterization of the information-theoretic limit for recovering almost all of $H$ (also known as almost exact recovery). Our characterization connects the KL divergence between $P_n$ and $Q_n$ to the logarithm of the first moment threshold of $H$ in the Erdős-Rényi random graph model $G(n,p)$. Our lower bound also extends to the task of partial recovery, in which only a constant $λ$-fraction of $H$ needs to be recovered. Last but not least, for certain Bernoulli and Exponential regimes, and for Gaussian distributions, we are able to show an All-or-Nothing (AoN) threshold phenomenon at the exponential scale.
Uncertainty Reasoning with Large Language Models for Explainable Disease Diagnosis
May 25, 2026Clinical decision-making requires reasoning over incomplete, imprecise, and linguistically expressed patient narratives. While large language models (LLMs) excel at extracting latent information from natural language, they lack the verifiability and interpretability essential for trustworthy medical AI. We propose a neuro-symbolic reasoning framework that aligns LLMs with formal logic to enable explainable and formally verifiable medical diagnosis. Patient descriptions and clinical guidelines are embedded into a neural knowledge base, where LLMs extract structured medical entities, temporal relations, and fuzzy symptom patterns, which are decoded into a symbolic knowledge base expressed in fuzzy logic and declarative rules. We perform two-stage reasoning: (1) inductive symbolic generalization to capture diagnostic patterns from encoded narratives, and (2) inference verification via a logic programming engine to derive and validate diagnoses consistent with clinical standards. Each symptom is treated as a fuzzy predicate with probabilistic weights, and inference paths are auditable, adjustable, and compatible with physician feedback. Unlike purely statistical methods, our system supports iterative refinement: misalignment between LLM-generated diagnoses and ground truth can be traced, explained, and corrected through formal rules. By combining logic-based transparency, LLM adaptability, and probabilistic robustness, the framework enables human-aligned healthcare inference with strong generalization and verifiable, step-by-step reasoning chains. We validate our framework on public benchmarks, demonstrating effective reconciliation of symbolic reasoning and LLMs with real-world clinical narratives. Results show performance comparable to state-of-the-art LLMs, while additionally providing interpretable reasoning paths and formally verifiable diagnostic conclusions.
TennisExpert: Towards Expert-Level Analytical Sports Video Understanding
Mar 17, 2026Tennis is one of the most widely followed sports, generating extensive broadcast footage with strong potential for professional analysis, automated coaching, and real-time commentary. However, automatic tennis understanding remains underexplored due to two key challenges: (1) the lack of large-scale benchmarks with fine-grained annotations and expert-level commentary, and (2) the difficulty of building accurate yet efficient multimodal systems suitable for real-time deployment. To address these challenges, we introduce TennisVL, a large-scale tennis benchmark comprising over 200 professional matches (471.9 hours) and 40,000+ rally-level clips. Unlike existing commentary datasets that focus on descriptive play-by-play narration, TennisVL emphasizes expert analytical commentary capturing tactical reasoning, player decisions, and match momentum. Furthermore, we propose TennisExpert, a multimodal tennis understanding framework that integrates a video semantic parser with a memory-augmented model built on Qwen3-VL-8B. The parser extracts key match elements (e.g., scores, shot sequences, ball bounces, and player locations), while hierarchical memory modules capture both short- and long-term temporal context. Experiments show that TennisExpert consistently outperforms strong proprietary baselines, including GPT-5, Gemini, and Claude, and demonstrates improved ability to capture tactical context and match dynamics. Our dataset and code are publicly available at https://github.com/LZYAndy/TennisExpert.
Vibe Coding an LLM-powered Theorem Prover
Jan 08, 2026We present Isabellm, an LLM-powered theorem prover for Isabelle/HOL that performs fully automatic proof synthesis. Isabellm works with any local LLM on Ollama and APIs such as Gemini CLI, and it is designed to run on consumer grade computers. The system combines a stepwise prover, which uses large language models to propose proof commands validated by Isabelle in a bounded search loop, with a higher-level proof planner that generates structured Isar outlines and attempts to fill and repair remaining gaps. The framework includes beam search for tactics, tactics reranker ML and RL models, premise selection with small transformer models, micro-RAG for Isar proofs built from AFP, and counter-example guided proof repair. All the code is implemented by GPT 4.1 - 5.2, Gemini 3 Pro, and Claude 4.5. Empirically, Isabellm can prove certain lemmas that defeat Isabelle's standard automation, including Sledgehammer, demonstrating the practical value of LLM-guided proof search. At the same time, we find that even state-of-the-art LLMs, such as GPT 5.2 Extended Thinking and Gemini 3 Pro struggle to reliably implement the intended fill-and-repair mechanisms with complex algorithmic designs, highlighting fundamental challenges in LLM code generation and reasoning. The code of Isabellm is available at https://github.com/zhehou/llm-isabelle
Few-Shot Precise Event Spotting via Unified Multi-Entity Graph and Distillation
Nov 18, 2025Precise event spotting (PES) aims to recognize fine-grained events at exact moments and has become a key component of sports analytics. This task is particularly challenging due to rapid succession, motion blur, and subtle visual differences. Consequently, most existing methods rely on domain-specific, end-to-end training with large labeled datasets and often struggle in few-shot conditions due to their dependence on pixel- or pose-based inputs alone. However, obtaining large labeled datasets is practically hard. We propose a Unified Multi-Entity Graph Network (UMEG-Net) for few-shot PES. UMEG-Net integrates human skeletons and sport-specific object keypoints into a unified graph and features an efficient spatio-temporal extraction module based on advanced GCN and multi-scale temporal shift. To further enhance performance, we employ multimodal distillation to transfer knowledge from keypoint-based graphs to visual representations. Our approach achieves robust performance with limited labeled data and significantly outperforms baseline models in few-shot settings, providing a scalable and effective solution for few-shot PES. Code is publicly available at https://github.com/LZYAndy/UMEG-Net.
Adaptive Plan-Execute Framework for Smart Contract Security Auditing
May 21, 2025Large Language Models (LLMs) have shown great promise in code analysis and auditing; however, they still struggle with hallucinations and limited context-aware reasoning. We introduce SmartAuditFlow, a novel Plan-Execute framework that enhances smart contract security analysis through dynamic audit planning and structured execution. Unlike conventional LLM-based auditing approaches that follow fixed workflows and predefined steps, SmartAuditFlow dynamically generates and refines audit plans based on the unique characteristics of each smart contract. It continuously adjusts its auditing strategy in response to intermediate LLM outputs and newly detected vulnerabilities, ensuring a more adaptive and precise security assessment. The framework then executes these plans step by step, applying a structured reasoning process to enhance vulnerability detection accuracy while minimizing hallucinations and false positives. To further improve audit precision, SmartAuditFlow integrates iterative prompt optimization and external knowledge sources, such as static analysis tools and Retrieval-Augmented Generation (RAG). This ensures audit decisions are contextually informed and backed by real-world security knowledge, producing comprehensive security reports. Extensive evaluations across multiple benchmarks demonstrate that SmartAuditFlow outperforms existing methods, achieving 100 percent accuracy on common and critical vulnerabilities, 41.2 percent accuracy for comprehensive coverage of known smart contract weaknesses in real-world projects, and successfully identifying all 13 tested CVEs. These results highlight SmartAuditFlow's scalability, cost-effectiveness, and superior adaptability over traditional static analysis tools and contemporary LLM-based approaches, establishing it as a robust solution for automated smart contract auditing.
Clustering and analysis of user behaviour in blockchain: A case study of Planet IX
Apr 16, 2025Decentralised applications (dApps) that run on public blockchains have the benefit of trustworthiness and transparency as every activity that happens on the blockchain can be publicly traced through the transaction data. However, this introduces a potential privacy problem as this data can be tracked and analysed, which can reveal user-behaviour information. A user behaviour analysis pipeline was proposed to present how this type of information can be extracted and analysed to identify separate behavioural clusters that can describe how users behave in the game. The pipeline starts with the collection of transaction data, involving smart contracts, that is collected from a blockchain-based game called Planet IX. Both the raw transaction information and the transaction events are considered in the data collection. From this data, separate game actions can be formed and those are leveraged to present how and when the users conducted their in-game activities in the form of user flows. An extended version of these user flows also presents how the Non-Fungible Tokens (NFTs) are being leveraged in the user actions. The latter is given as input for a Graph Neural Network (GNN) model to provide graph embeddings for these flows which then can be leveraged by clustering algorithms to cluster user behaviours into separate behavioural clusters. We benchmark and compare well-known clustering algorithms as a part of the proposed method. The user behaviour clusters were analysed and visualised in a graph format. It was found that behavioural information can be extracted regarding the users that belong to these clusters. Such information can be exploited by malicious users to their advantage. To demonstrate this, a privacy threat model was also presented based on the results that correspond to multiple potentially affected areas.
F$^3$Set: Towards Analyzing Fast, Frequent, and Fine-grained Events from Videos
Apr 15, 2025Analyzing Fast, Frequent, and Fine-grained (F$^3$) events presents a significant challenge in video analytics and multi-modal LLMs. Current methods struggle to identify events that satisfy all the F$^3$ criteria with high accuracy due to challenges such as motion blur and subtle visual discrepancies. To advance research in video understanding, we introduce F$^3$Set, a benchmark that consists of video datasets for precise F$^3$ event detection. Datasets in F$^3$Set are characterized by their extensive scale and comprehensive detail, usually encompassing over 1,000 event types with precise timestamps and supporting multi-level granularity. Currently, F$^3$Set contains several sports datasets, and this framework may be extended to other applications as well. We evaluated popular temporal action understanding methods on F$^3$Set, revealing substantial challenges for existing techniques. Additionally, we propose a new method, F$^3$ED, for F$^3$ event detections, achieving superior performance. The dataset, model, and benchmark code are available at https://github.com/F3Set/F3Set.
The Fusion of Large Language Models and Formal Methods for Trustworthy AI Agents: A Roadmap
Dec 09, 2024


Large Language Models (LLMs) have emerged as a transformative AI paradigm, profoundly influencing daily life through their exceptional language understanding and contextual generation capabilities. Despite their remarkable performance, LLMs face a critical challenge: the propensity to produce unreliable outputs due to the inherent limitations of their learning-based nature. Formal methods (FMs), on the other hand, are a well-established computation paradigm that provides mathematically rigorous techniques for modeling, specifying, and verifying the correctness of systems. FMs have been extensively applied in mission-critical software engineering, embedded systems, and cybersecurity. However, the primary challenge impeding the deployment of FMs in real-world settings lies in their steep learning curves, the absence of user-friendly interfaces, and issues with efficiency and adaptability. This position paper outlines a roadmap for advancing the next generation of trustworthy AI systems by leveraging the mutual enhancement of LLMs and FMs. First, we illustrate how FMs, including reasoning and certification techniques, can help LLMs generate more reliable and formally certified outputs. Subsequently, we highlight how the advanced learning capabilities and adaptability of LLMs can significantly enhance the usability, efficiency, and scalability of existing FM tools. Finally, we show that unifying these two computation paradigms -- integrating the flexibility and intelligence of LLMs with the rigorous reasoning abilities of FMs -- has transformative potential for the development of trustworthy AI software systems. We acknowledge that this integration has the potential to enhance both the trustworthiness and efficiency of software engineering practices while fostering the development of intelligent FM tools capable of addressing complex yet real-world challenges.
VisionCoder: Empowering Multi-Agent Auto-Programming for Image Processing with Hybrid LLMs
Oct 25, 2024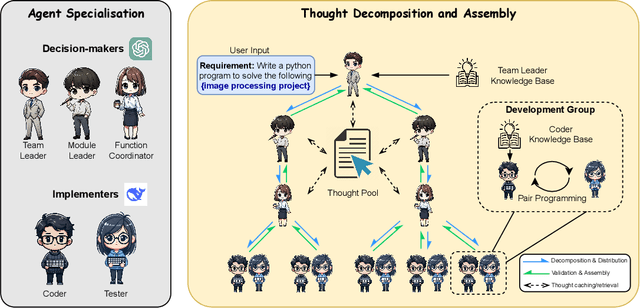



In the field of automated programming, large language models (LLMs) have demonstrated foundational generative capabilities when given detailed task descriptions. However, their current functionalities are primarily limited to function-level development, restricting their effectiveness in complex project environments and specific application scenarios, such as complicated image-processing tasks. This paper presents a multi-agent framework that utilises a hybrid set of LLMs, including GPT-4o and locally deployed open-source models, which collaboratively complete auto-programming tasks. Each agent plays a distinct role in the software development cycle, collectively forming a virtual organisation that works together to produce software products. By establishing a tree-structured thought distribution and development mechanism across project, module, and function levels, this framework offers a cost-effective and efficient solution for code generation. We evaluated our approach using benchmark datasets, and the experimental results demonstrate that VisionCoder significantly outperforms existing methods in image processing auto-programming tasks.