 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Plan-Execute Framework for Smart Contract Security Auditing
May 21, 2025Large Language Models (LLMs) have shown great promise in code analysis and auditing; however, they still struggle with hallucinations and limited context-aware reasoning. We introduce SmartAuditFlow, a novel Plan-Execute framework that enhances smart contract security analysis through dynamic audit planning and structured execution. Unlike conventional LLM-based auditing approaches that follow fixed workflows and predefined steps, SmartAuditFlow dynamically generates and refines audit plans based on the unique characteristics of each smart contract. It continuously adjusts its auditing strategy in response to intermediate LLM outputs and newly detected vulnerabilities, ensuring a more adaptive and precise security assessment. The framework then executes these plans step by step, applying a structured reasoning process to enhance vulnerability detection accuracy while minimizing hallucinations and false positives. To further improve audit precision, SmartAuditFlow integrates iterative prompt optimization and external knowledge sources, such as static analysis tools and Retrieval-Augmented Generation (RAG). This ensures audit decisions are contextually informed and backed by real-world security knowledge, producing comprehensive security reports. Extensive evaluations across multiple benchmarks demonstrate that SmartAuditFlow outperforms existing methods, achieving 100 percent accuracy on common and critical vulnerabilities, 41.2 percent accuracy for comprehensive coverage of known smart contract weaknesses in real-world projects, and successfully identifying all 13 tested CVEs. These results highlight SmartAuditFlow's scalability, cost-effectiveness, and superior adaptability over traditional static analysis tools and contemporary LLM-based approaches, establishing it as a robust solution for automated smart contract auditing.
VisionCoder: Empowering Multi-Agent Auto-Programming for Image Processing with Hybrid LLMs
Oct 25, 2024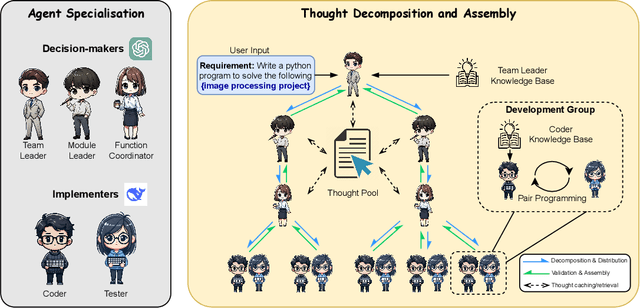



In the field of automated programming, large language models (LLMs) have demonstrated foundational generative capabilities when given detailed task descriptions. However, their current functionalities are primarily limited to function-level development, restricting their effectiveness in complex project environments and specific application scenarios, such as complicated image-processing tasks. This paper presents a multi-agent framework that utilises a hybrid set of LLMs, including GPT-4o and locally deployed open-source models, which collaboratively complete auto-programming tasks. Each agent plays a distinct role in the software development cycle, collectively forming a virtual organisation that works together to produce software products. By establishing a tree-structured thought distribution and development mechanism across project, module, and function levels, this framework offers a cost-effective and efficient solution for code generation. We evaluated our approach using benchmark datasets, and the experimental results demonstrate that VisionCoder significantly outperforms existing methods in image processing auto-programming tasks.
Studying Vulnerable Code Entities in R
Feb 06, 2024
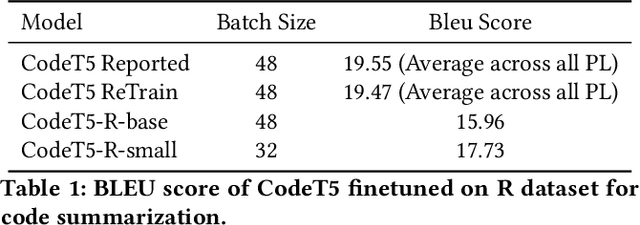
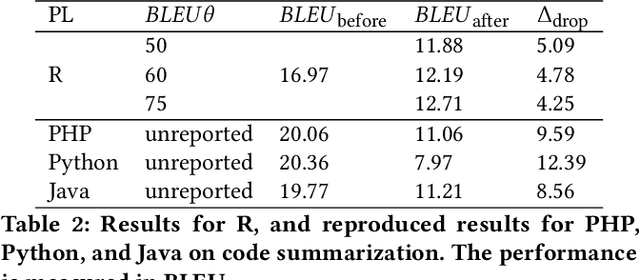

Pre-trained Code Language Models (Code-PLMs) have shown many advancements and achieved state-of-the-art results for many software engineering tasks in the past few years. These models are mainly targeted for popular programming languages such as Java and Python, leaving out many other ones like R. Though R has a wide community of developers and users, there is little known about the applicability of Code-PLMs for R. In this preliminary study, we aim to investigate the vulnerability of Code-PLMs for code entities in R. For this purpose, we use an R dataset of code and comment pairs and then apply CodeAttack, a black-box attack model that uses the structure of code to generate adversarial code samples. We investigate how the model can attack different entities in R. This is the first step towards understanding the importance of R token types, compared to popular programming languages (e.g., Java). We limit our study to code summarization. Our results show that the most vulnerable code entity is the identifier, followed by some syntax tokens specific to R. The results can shed light on the importance of token types and help in developing models for code summarization and method name prediction for the R language.
A Two-Dimensional Deep Network for RF-based Drone Detection and Identification Towards Secure Coverage Extension
Aug 26, 2023



As drones become increasingly prevalent in human life, they also raises security concerns such as unauthorized access and control, as well as collisions and interference with manned aircraft. Therefore, ensuring the ability to accurately detect and identify between different drones holds significant implications for coverage extension. Assisted by machine learning, radio frequency (RF) detection can recognize the type and flight mode of drones based on the sampled drone signals. In this paper, we first utilize Short-Time Fourier. Transform (STFT) to extract two-dimensional features from the raw signals, which contain both time-domain and frequency-domain information. Then, we employ a Convolutional Neural Network (CNN) built with ResNet structure to achieve multi-class classifications. Our experimental results show that the proposed ResNet-STFT can achieve higher accuracy and faster convergence on the extended dataset. Additionally, it exhibits balanced performance compared to other baselines on the raw dataset.