 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Manipulated Contents Using Knowledge-Grounded Inference
Apr 29, 2025The detection of manipulated content, a prevalent form of fake news, has been widely studied in recent years. While existing solutions have been proven effective in fact-checking and analyzing fake news based on historical events, the reliance on either intrinsic knowledge obtained during training or manually curated context hinders them from tackling zero-day manipulated content, which can only be recognized with real-time contextual information. In this work, we propose Manicod, a tool designed for detecting zero-day manipulated content. Manicod first sources contextual information about the input claim from mainstream search engines, and subsequently vectorizes the context for the large language model (LLM) through retrieval-augmented generation (RAG). The LLM-based inference can produce a "truthful" or "manipulated" decision and offer a textual explanation for the decision. To validate the effectiveness of Manicod, we also propose a dataset comprising 4270 pieces of manipulated fake news derived from 2500 recent real-world news headlines. Manicod achieves an overall F1 score of 0.856 on this dataset and outperforms existing methods by up to 1.9x in F1 score on their benchmarks on fact-checking and claim verification.
I Can Find You in Seconds! Leveraging Large Language Models for Code Authorship Attribution
Jan 14, 2025


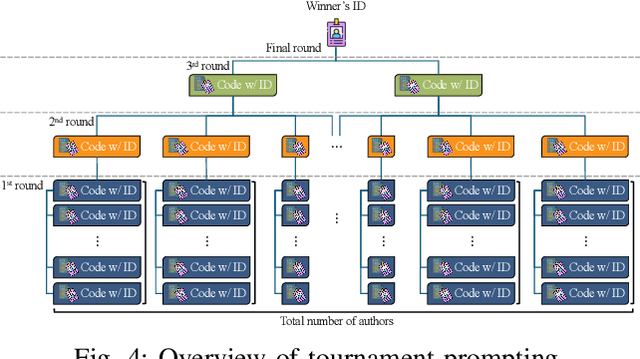
Source code authorship attribution is important in software forensics, plagiarism detection, and protecting software patch integrity. Existing techniques often rely on supervised machine learning, which struggles with generalization across different programming languages and coding styles due to the need for large labeled datasets. Inspired by recent advances in natural language authorship analysis using large language models (LLMs), which have shown exceptional performance without task-specific tuning, this paper explores the use of LLMs for source code authorship attribution. We present a comprehensive study demonstrating that state-of-the-art LLMs can successfully attribute source code authorship across different languages. LLMs can determine whether two code snippets are written by the same author with zero-shot prompting, achieving a Matthews Correlation Coefficient (MCC) of 0.78, and can attribute code authorship from a small set of reference code snippets via few-shot learning, achieving MCC of 0.77. Additionally, LLMs show some adversarial robustness against misattribution attacks. Despite these capabilities, we found that naive prompting of LLMs does not scale well with a large number of authors due to input token limitations. To address this, we propose a tournament-style approach for large-scale attribution. Evaluating this approach on datasets of C++ (500 authors, 26,355 samples) and Java (686 authors, 55,267 samples) code from GitHub, we achieve classification accuracy of up to 65% for C++ and 68.7% for Java using only one reference per author. These results open new possibilities for applying LLMs to code authorship attribution in cybersecurity and software engineering.
GlitchProber: Advancing Effective Detection and Mitigation of Glitch Tokens in Large Language Models
Aug 09, 2024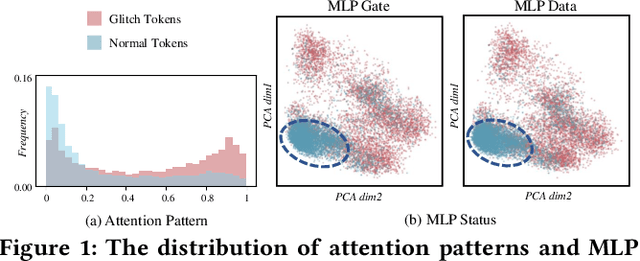
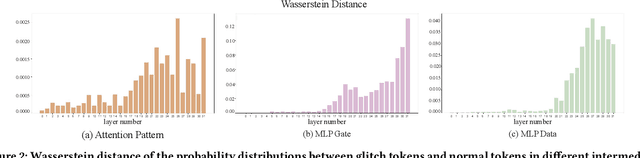
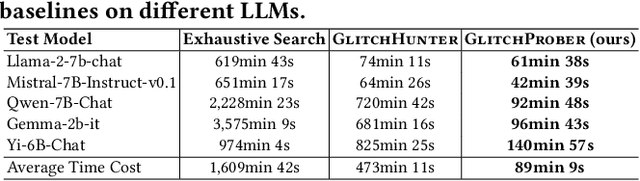
Large language models (LLMs) have achieved unprecedented success in the field of natural language processing. However, the black-box nature of their internal mechanisms has brought many concerns about their trustworthiness and interpretability. Recent research has discovered a class of abnormal tokens in the model's vocabulary space and named them "glitch tokens". Those tokens, once included in the input, may induce the model to produce incorrect, irrelevant, or even harmful results, drastically undermining the reliability and practicality of LLMs. In this work, we aim to enhance the understanding of glitch tokens and propose techniques for their detection and mitigation. We first reveal the characteristic features induced by glitch tokens on LLMs, which are evidenced by significant deviations in the distributions of attention patterns and dynamic information from intermediate model layers. Based on the insights, we develop GlitchProber, a tool for efficient glitch token detection and mitigation. GlitchProber utilizes small-scale sampling, principal component analysis for accelerated feature extraction, and a simple classifier for efficient vocabulary screening. Taking one step further, GlitchProber rectifies abnormal model intermediate layer values to mitigate the destructive effects of glitch tokens. Evaluated on five mainstream open-source LLMs, GlitchProber demonstrates higher efficiency, precision, and recall compared to existing approaches, with an average F1 score of 0.86 and an average repair rate of 50.06%. GlitchProber unveils a novel path to address the challenges posed by glitch tokens and inspires future research toward more robust and interpretable LLMs.
PAODING: A High-fidelity Data-free Pruning Toolkit for Debloating Pre-trained Neural Networks
Apr 30, 2024

We present PAODING, a toolkit to debloat pretrained neural network models through the lens of data-free pruning. To preserve the model fidelity, PAODING adopts an iterative process, which dynamically measures the effect of deleting a neuron to identify candidates that have the least impact to the output layer. Our evaluation shows that PAODING can significantly reduce the model size, generalize on different datasets and models, and meanwhile preserve the model fidelity in terms of test accuracy and adversarial robustness. PAODING is publicly available on PyPI via https://pypi.org/project/paoding-dl.
Adversarial Robustness of Deep Neural Networks: A Survey from a Formal Verification Perspective
Jun 24, 2022
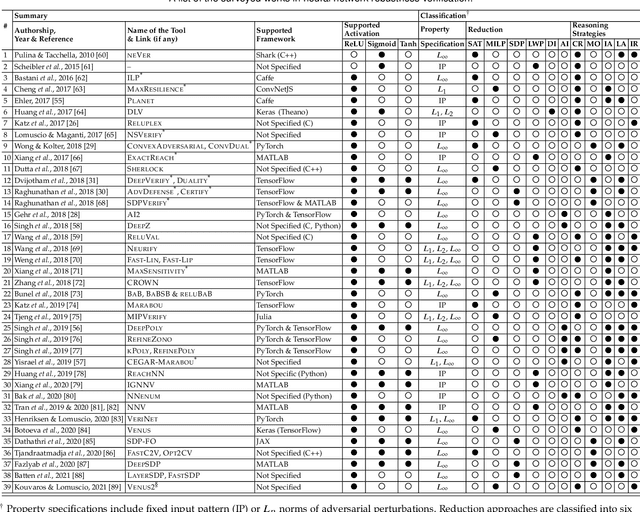
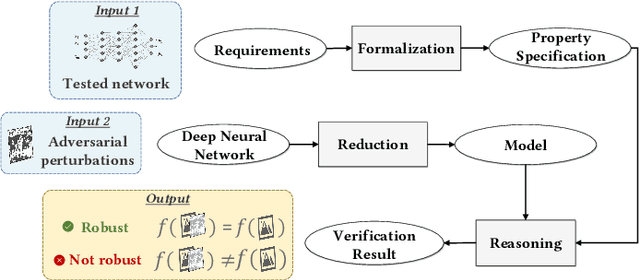

Neural networks have been widely applied in security applications such as spam and phishing detection, intrusion prevention, and malware detection. This black-box method, however, often has uncertainty and poor explainability in applications. Furthermore, neural networks themselves are often vulnerable to adversarial attacks. For those reasons, there is a high demand for trustworthy and rigorous methods to verify the robustness of neural network models. Adversarial robustness, which concerns the reliability of a neural network when dealing with maliciously manipulated inputs, is one of the hottest topics in security and machine learning. In this work, we survey existing literature in adversarial robustness verification for neural networks and collect 39 diversified research works across machine learning, security, and software engineering domains. We systematically analyze their approaches, including how robustness is formulated, what verification techniques are used, and the strengths and limitations of each technique. We provide a taxonomy from a formal verification perspective for a comprehensive understanding of this topic. We classify the existing techniques based on property specification, problem reduction, and reasoning strategies. We also demonstrate representative techniques that have been applied in existing studies with a sample model. Finally, we discuss open questions for future research.
Paoding: Supervised Robustness-preserving Data-free Neural Network Pruning
Apr 02, 2022

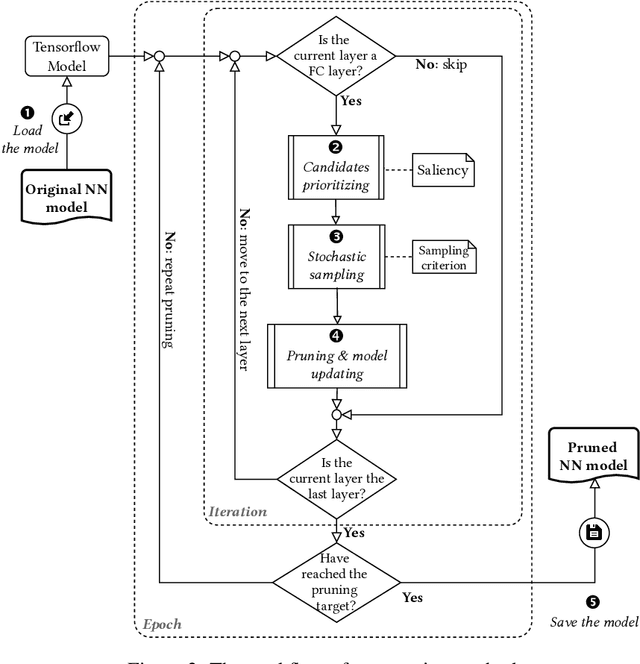
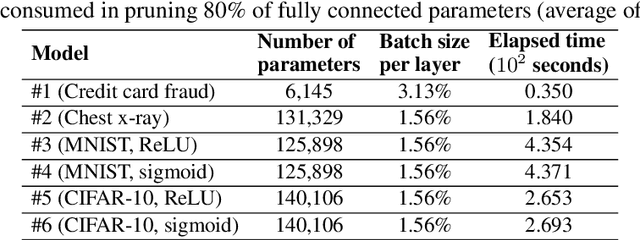
When deploying pre-trained neural network models in real-world applications, model consumers often encounter resource-constraint platforms such as mobile and smart devices. They typically use the pruning technique to reduce the size and complexity of the model, generating a lighter one with less resource consumption. Nonetheless, most existing pruning methods are proposed with a premise that the model after being pruned has a chance to be fine-tuned or even retrained based on the original training data. This may be unrealistic in practice, as the data controllers are often reluctant to provide their model consumers with the original data. In this work, we study the neural network pruning in the \emph{data-free} context, aiming to yield lightweight models that are not only accurate in prediction but also robust against undesired inputs in open-world deployments. Considering the absence of the fine-tuning and retraining that can fix the mis-pruned units, we replace the traditional aggressive one-shot strategy with a conservative one that treats the pruning as a progressive process. We propose a pruning method based on stochastic optimization that uses robustness-related metrics to guide the pruning process. Our method is implemented as a Python package named \textsc{Paoding} and evaluated with a series of experiments on diverse neural network models. The experimental results show that it significantly outperforms existing one-shot data-free pruning approaches in terms of robustness preservation and accuracy.