 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaoding: Supervised Robustness-preserving Data-free Neural Network Pruning
Paper and Code


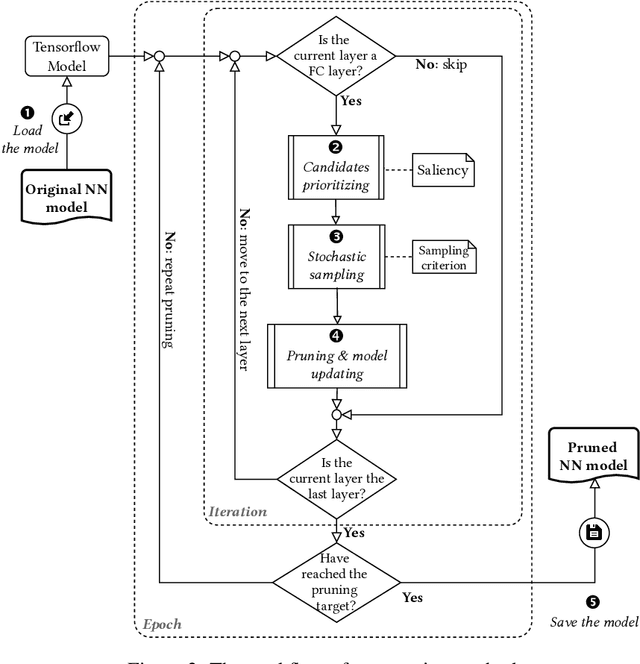
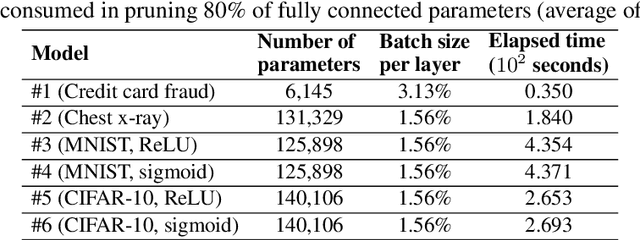
When deploying pre-trained neural network models in real-world applications, model consumers often encounter resource-constraint platforms such as mobile and smart devices. They typically use the pruning technique to reduce the size and complexity of the model, generating a lighter one with less resource consumption. Nonetheless, most existing pruning methods are proposed with a premise that the model after being pruned has a chance to be fine-tuned or even retrained based on the original training data. This may be unrealistic in practice, as the data controllers are often reluctant to provide their model consumers with the original data. In this work, we study the neural network pruning in the \emph{data-free} context, aiming to yield lightweight models that are not only accurate in prediction but also robust against undesired inputs in open-world deployments. Considering the absence of the fine-tuning and retraining that can fix the mis-pruned units, we replace the traditional aggressive one-shot strategy with a conservative one that treats the pruning as a progressive process. We propose a pruning method based on stochastic optimization that uses robustness-related metrics to guide the pruning process. Our method is implemented as a Python package named \textsc{Paoding} and evaluated with a series of experiments on diverse neural network models. The experimental results show that it significantly outperforms existing one-shot data-free pruning approaches in terms of robustness preservation and accuracy.