 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlitchProber: Advancing Effective Detection and Mitigation of Glitch Tokens in Large Language Models
Aug 09, 2024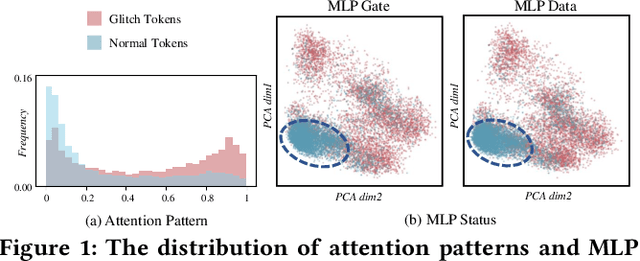
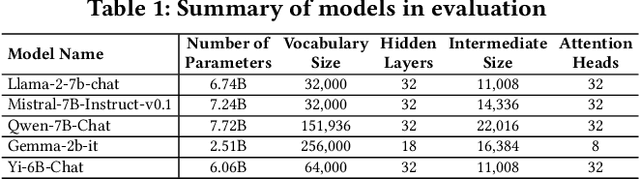
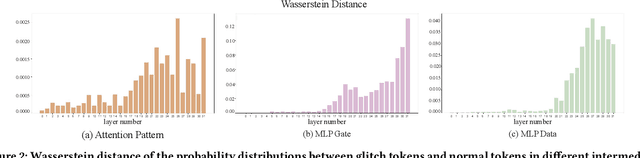
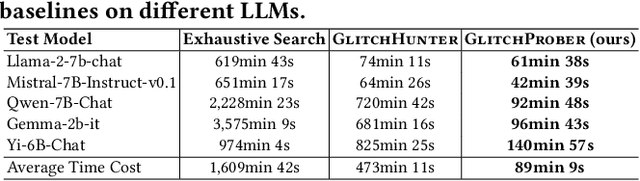
Large language models (LLMs) have achieved unprecedented success in the field of natural language processing. However, the black-box nature of their internal mechanisms has brought many concerns about their trustworthiness and interpretability. Recent research has discovered a class of abnormal tokens in the model's vocabulary space and named them "glitch tokens". Those tokens, once included in the input, may induce the model to produce incorrect, irrelevant, or even harmful results, drastically undermining the reliability and practicality of LLMs. In this work, we aim to enhance the understanding of glitch tokens and propose techniques for their detection and mitigation. We first reveal the characteristic features induced by glitch tokens on LLMs, which are evidenced by significant deviations in the distributions of attention patterns and dynamic information from intermediate model layers. Based on the insights, we develop GlitchProber, a tool for efficient glitch token detection and mitigation. GlitchProber utilizes small-scale sampling, principal component analysis for accelerated feature extraction, and a simple classifier for efficient vocabulary screening. Taking one step further, GlitchProber rectifies abnormal model intermediate layer values to mitigate the destructive effects of glitch tokens. Evaluated on five mainstream open-source LLMs, GlitchProber demonstrates higher efficiency, precision, and recall compared to existing approaches, with an average F1 score of 0.86 and an average repair rate of 50.06%. GlitchProber unveils a novel path to address the challenges posed by glitch tokens and inspires future research toward more robust and interpretable LLMs.