 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAGRAMPLIFIER: Defending Federated Learning Against Poisoning Attacks Through Local Update Amplification
Paper and Code
Nov 23, 2023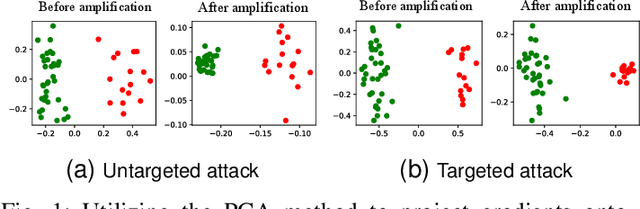


The collaborative nature of federated learning (FL) poses a major threat in the form of manipulation of local training data and local updates, known as the Byzantine poisoning attack. To address this issue, many Byzantine-robust aggregation rules (AGRs) have been proposed to filter out or moderate suspicious local updates uploaded by Byzantine participants. This paper introduces a novel approach called AGRAMPLIFIER, aiming to simultaneously improve the robustness, fidelity, and efficiency of the existing AGRs. The core idea of AGRAMPLIFIER is to amplify the "morality" of local updates by identifying the most repressive features of each gradient update, which provides a clearer distinction between malicious and benign updates, consequently improving the detection effect. To achieve this objective, two approaches, namely AGRMP and AGRXAI, are proposed. AGRMP organizes local updates into patches and extracts the largest value from each patch, while AGRXAI leverages explainable AI methods to extract the gradient of the most activated features. By equipping AGRAMPLIFIER with the existing Byzantine-robust mechanisms, we successfully enhance the model's robustness, maintaining its fidelity and improving overall efficiency. AGRAMPLIFIER is universally compatible with the existing Byzantine-robust mechanisms. The paper demonstrates its effectiveness by integrating it with all mainstream AGR mechanisms. Extensive evaluations conducted on seven datasets from diverse domains against seven representative poisoning attacks consistently show enhancements in robustness, fidelity, and efficiency, with average gains of 40.08%, 39.18%, and 10.68%, respectively.