 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Refinement of Universal Multimodal Attacks on Vision-Language Models
Jan 15, 2026Existing adversarial attacks for VLP models are mostly sample-specific, resulting in substantial computational overhead when scaled to large datasets or new scenarios. To overcome this limitation, we propose Hierarchical Refinement Attack (HRA), a multimodal universal attack framework for VLP models. HRA refines universal adversarial perturbations (UAPs) at both the sample level and the optimization level. For the image modality, we disentangle adversarial examples into clean images and perturbations, allowing each component to be handled independently for more effective disruption of cross-modal alignment. We further introduce a ScMix augmentation strategy that diversifies visual contexts and strengthens both global and local utility of UAPs, thereby reducing reliance on spurious features. In addition, we refine the optimization path by leveraging a temporal hierarchy of historical and estimated future gradients to avoid local minima and stabilize universal perturbation learning. For the text modality, HRA identifies globally influential words by combining intra-sentence and inter-sentence importance measures, and subsequently utilizes these words as universal text perturbations. Extensive experiments across various downstream tasks, VLP models, and datasets demonstrate the superiority of the proposed universal multimodal attacks.
MAA: Meticulous Adversarial Attack against Vision-Language Pre-trained Models
Feb 12, 2025Current adversarial attacks for evaluating the robustness of vision-language pre-trained (VLP) models in multi-modal tasks suffer from limited transferability, where attacks crafted for a specific model often struggle to generalize effectively across different models, limiting their utility in assessing robustness more broadly. This is mainly attributed to the over-reliance on model-specific features and regions, particularly in the image modality. In this paper, we propose an elegant yet highly effective method termed Meticulous Adversarial Attack (MAA) to fully exploit model-independent characteristics and vulnerabilities of individual samples, achieving enhanced generalizability and reduced model dependence. MAA emphasizes fine-grained optimization of adversarial images by developing a novel resizing and sliding crop (RScrop) technique, incorporating a multi-granularity similarity disruption (MGSD) strategy. Extensive experiments across diverse VLP models, multiple benchmark datasets, and a variety of downstream tasks demonstrate that MAA significantly enhances the effectiveness and transferability of adversarial attacks. A large cohort of performance studies is conducted to generate insights into the effectiveness of various model configurations, guiding future advancements in this domain.
Effective and Robust Adversarial Training against Data and Label Corruptions
May 07, 2024



Corruptions due to data perturbations and label noise are prevalent in the datasets from unreliable sources, which poses significant threats to model training. Despite existing efforts in developing robust models, current learning methods commonly overlook the possible co-existence of both corruptions, limiting the effectiveness and practicability of the model. In this paper, we develop an Effective and Robust Adversarial Training (ERAT) framework to simultaneously handle two types of corruption (i.e., data and label) without prior knowledge of their specifics. We propose a hybrid adversarial training surrounding multiple potential adversarial perturbations, alongside a semi-supervised learning based on class-rebalancing sample selection to enhance the resilience of the model for dual corruption. On the one hand, in the proposed adversarial training, the perturbation generation module learns multiple surrogate malicious data perturbations by taking a DNN model as the victim, while the model is trained to maintain semantic consistency between the original data and the hybrid perturbed data. It is expected to enable the model to cope with unpredictable perturbations in real-world data corruption. On the other hand, a class-rebalancing data selection strategy is designed to fairly differentiate clean labels from noisy labels. Semi-supervised learning is performed accordingly by discarding noisy labels. Extensive experiments demonstrate the superiority of the proposed ERAT framework.
Balanced and Explainable Social Media Analysis for Public Health with Large Language Models
Sep 12, 2023



As social media becomes increasingly popular, more and more public health activities emerge, which is worth noting for pandemic monitoring and government decision-making. Current techniques for public health analysis involve popular models such as BERT and large language models (LLMs). Although recent progress in LLMs has shown a strong ability to comprehend knowledge by being fine-tuned on specific domain datasets, the costs of training an in-domain LLM for every specific public health task are especially expensive. Furthermore, such kinds of in-domain datasets from social media are generally highly imbalanced, which will hinder the efficiency of LLMs tuning. To tackle these challenges, the data imbalance issue can be overcome by sophisticated data augmentation methods for social media datasets. In addition, the ability of the LLMs can be effectively utilised by prompting the model properly. In light of the above discussion, in this paper, a novel ALEX framework is proposed for social media analysis on public health. Specifically, an augmentation pipeline is developed to resolve the data imbalance issue. Furthermore, an LLMs explanation mechanism is proposed by prompting an LLM with the predicted results from BERT models. Extensive experiments conducted on three tasks at the Social Media Mining for Health 2023 (SMM4H) competition with the first ranking in two tasks demonstrate the superior performance of the proposed ALEX method. Our code has been released in https://github.com/YanJiangJerry/ALEX.
FedVMR: A New Federated Learning method for Video Moment Retrieval
Oct 28, 2022



Despite the great success achieved, existing video moment retrieval (VMR) methods are developed under the assumption that data are centralizedly stored. However, in real-world applications, due to the inherent nature of data generation and privacy concerns, data are often distributed on different silos, bringing huge challenges to effective large-scale training. In this work, we try to overcome above limitation by leveraging the recent success of federated learning. As the first that is explored in VMR field, the new task is defined as video moment retrieval with distributed data. Then, a novel federated learning method named FedVMR is proposed to facilitate large-scale and secure training of VMR models in decentralized environment. Experiments on benchmark datasets demonstrate its effectiveness. This work is the very first attempt to enable safe and efficient VMR training in decentralized scene, which is hoped to pave the way for further study in the related research field.
Self-supervised Graph-based Point-of-interest Recommendation
Oct 22, 2022



The exponential growth of Location-based Social Networks (LBSNs) has greatly stimulated the demand for precise location-based recommendation services. Next Point-of-Interest (POI) recommendation, which aims to provide personalised POI suggestions for users based on their visiting histories, has become a prominent component in location-based e-commerce. Recent POI recommenders mainly employ self-attention mechanism or graph neural networks to model complex high-order POI-wise interactions. However, most of them are merely trained on the historical check-in data in a standard supervised learning manner, which fail to fully explore each user's multi-faceted preferences, and suffer from data scarcity and long-tailed POI distribution, resulting in sub-optimal performance. To this end, we propose a Self-s}upervised Graph-enhanced POI Recommender (S2GRec) for next POI recommendation. In particular, we devise a novel Graph-enhanced Self-attentive layer to incorporate the collaborative signals from both global transition graph and local trajectory graphs to uncover the transitional dependencies among POIs and capture a user's temporal interests. In order to counteract the scarcity and incompleteness of POI check-ins, we propose a novel self-supervised learning paradigm in \ssgrec, where the trajectory representations are contrastively learned from two augmented views on geolocations and temporal transitions. Extensive experiments are conducted on three real-world LBSN datasets, demonstrating the effectiveness of our model against state-of-the-art methods.
Discovering Domain Disentanglement for Generalized Multi-source Domain Adaptation
Jul 11, 2022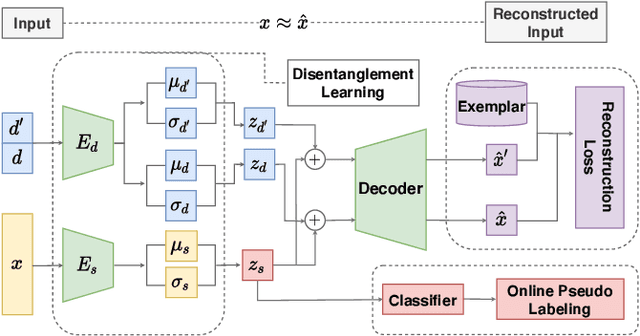



A typical multi-source domain adaptation (MSDA) approach aims to transfer knowledge learned from a set of labeled source domains, to an unlabeled target domain. Nevertheless, prior works strictly assume that each source domain shares the identical group of classes with the target domain, which could hardly be guaranteed as the target label space is not observable. In this paper, we consider a more versatile setting of MSDA, namely Generalized Multi-source Domain Adaptation, wherein the source domains are partially overlapped, and the target domain is allowed to contain novel categories that are not presented in any source domains. This new setting is more elusive than any existing domain adaptation protocols due to the coexistence of the domain and category shifts across the source and target domains. To address this issue, we propose a variational domain disentanglement (VDD) framework, which decomposes the domain representations and semantic features for each instance by encouraging dimension-wise independence. To identify the target samples of unknown classes, we leverage online pseudo labeling, which assigns the pseudo-labels to unlabeled target data based on the confidence scores. Quantitative and qualitative experiments conducted on two benchmark datasets demonstrate the validity of the proposed framework.
Lightweight Self-Attentive Sequential Recommendation
Aug 25, 2021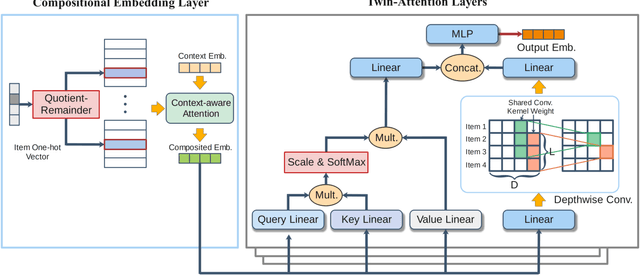

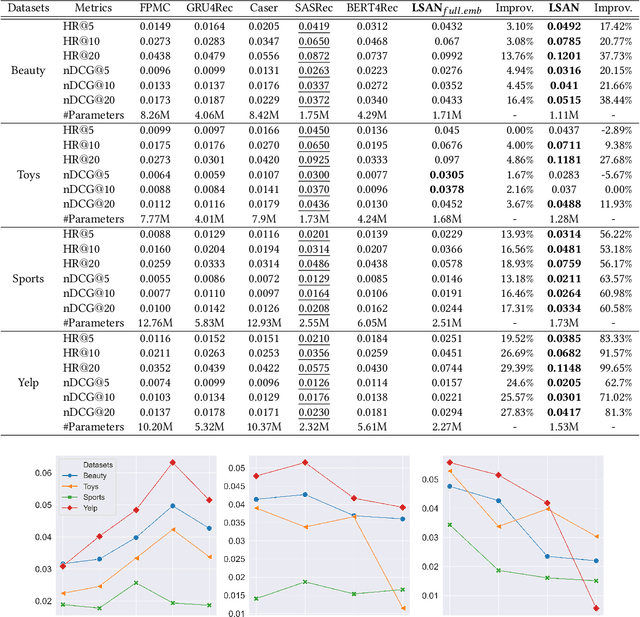
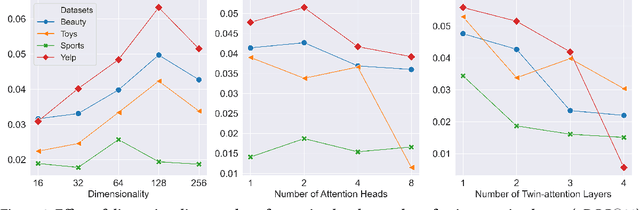
Modern deep neural networks (DNNs) have greatly facilitated the development of sequential recommender systems by achieving state-of-the-art recommendation performance on various sequential recommendation tasks. Given a sequence of interacted items, existing DNN-based sequential recommenders commonly embed each item into a unique vector to support subsequent computations of the user interest. However, due to the potentially large number of items, the over-parameterised item embedding matrix of a sequential recommender has become a memory bottleneck for efficient deployment in resource-constrained environments, e.g., smartphones and other edge devices. Furthermore, we observe that the widely-used multi-head self-attention, though being effective in modelling sequential dependencies among items, heavily relies on redundant attention units to fully capture both global and local item-item transition patterns within a sequence. In this paper, we introduce a novel lightweight self-attentive network (LSAN) for sequential recommendation. To aggressively compress the original embedding matrix, LSAN leverages the notion of compositional embeddings, where each item embedding is composed by merging a group of selected base embedding vectors derived from substantially smaller embedding matrices. Meanwhile, to account for the intrinsic dynamics of each item, we further propose a temporal context-aware embedding composition scheme. Besides, we develop an innovative twin-attention network that alleviates the redundancy of the traditional multi-head self-attention while retaining full capacity for capturing long- and short-term (i.e., global and local) item dependencies. Comprehensive experiments demonstrate that LSAN significantly advances the accuracy and memory efficiency of existing sequential recommenders.