 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRule-based Data Selection for Large Language Models
Paper and Code

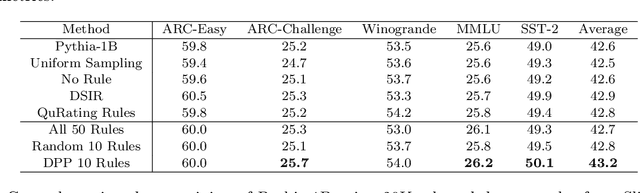
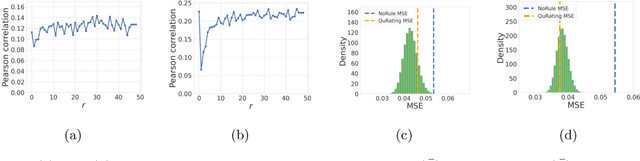
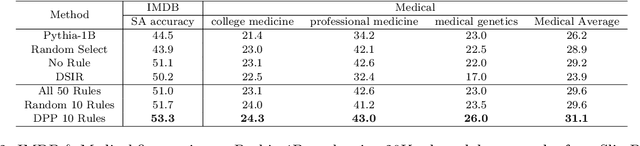
The quality of training data significantly impacts the performance of large language models (LLMs). There are increasing studies using LLMs to rate and select data based on several human-crafted metrics (rules). However, these conventional rule-based approaches often depend too heavily on human heuristics, lack effective metrics for assessing rules, and exhibit limited adaptability to new tasks. In our study, we introduce an innovative rule-based framework that utilizes the orthogonality of score vectors associated with rules as a novel metric for rule evaluations. Our approach includes an automated pipeline that first uses LLMs to generate a diverse set of rules, encompassing various rating dimensions to evaluate data quality. Then it rates a batch of data based on these rules and uses the determinantal point process (DPP) from random matrix theory to select the most orthogonal score vectors, thereby identifying a set of independent rules. These rules are subsequently used to evaluate all data, selecting samples with the highest average scores for downstream tasks such as LLM training. We verify the effectiveness of our method through two experimental setups: 1) comparisons with ground truth ratings and 2) benchmarking LLMs trained with the chosen data. Our comprehensive experiments cover a range of scenarios, including general pre-training and domain-specific fine-tuning in areas such as IMDB, Medical, Math, and Code. The outcomes demonstrate that our DPP-based rule rating method consistently outperforms other approaches, including rule-free rating, uniform sampling, importance resampling, and QuRating, in terms of both rating precision and model performance.