 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRAFT: Calibrated Reasoning with Answer-Faithful Traces via Reinforcement Learning for Multi-Hop Question Answering
Feb 01, 2026Retrieval-augmented generation (RAG) is widely used to ground Large Language Models (LLMs) for multi-hop question answering. Recent work mainly focused on improving answer accuracy via fine-tuning and structured or reinforcement-based optimization. However, reliable reasoning in response generation faces three challenges: 1) Reasoning Collapse. Reasoning in multi-hop QA is inherently complex due to multi-hop composition and is further destabilized by noisy retrieval. 2) Reasoning-answer inconsistency. Due to the intrinsic uncertainty of LLM generation and exposure to evidence--distractor mixtures, models may produce correct answers that are not faithfully supported by their intermediate reasoning or evidence. 3) Loss of format control. Traditional chain-of-thought generation often deviates from required structured output formats, leading to incomplete or malformed structured content. To address these challenges, we propose CRAFT (Calibrated Reasoning with Answer-Faithful Traces), a Group Relative Policy Optimization (GRPO) based reinforcement learning framework that trains models to perform faithful reasoning during response generation. CRAFT employs dual reward mechanisms to optimize multi-hop reasoning: deterministic rewards ensure structural correctness while judge-based rewards verify semantic faithfulness. This optimization framework supports controllable trace variants that enable systematic analysis of how structure and scale affect reasoning performance and faithfulness. Experiments on three multi-hop QA benchmarks show that CRAFT improves both answer accuracy and reasoning faithfulness across model scales, with the CRAFT 7B model achieving competitive performance with closed-source LLMs across multiple reasoning trace settings.
MuVaC: AVariational Causal Framework for Multimodal Sarcasm Understanding in Dialogues
Jan 28, 2026The prevalence of sarcasm in multimodal dialogues on the social platforms presents a crucial yet challenging task for understanding the true intent behind online content. Comprehensive sarcasm analysis requires two key aspects: Multimodal Sarcasm Detection (MSD) and Multimodal Sarcasm Explanation (MuSE). Intuitively, the act of detection is the result of the reasoning process that explains the sarcasm. Current research predominantly focuses on addressing either MSD or MuSE as a single task. Even though some recent work has attempted to integrate these tasks, their inherent causal dependency is often overlooked. To bridge this gap, we propose MuVaC, a variational causal inference framework that mimics human cognitive mechanisms for understanding sarcasm, enabling robust multimodal feature learning to jointly optimize MSD and MuSE. Specifically, we first model MSD and MuSE from the perspective of structural causal models, establishing variational causal pathways to define the objectives for joint optimization. Next, we design an alignment-then-fusion approach to integrate multimodal features, providing robust fusion representations for sarcasm detection and explanation generation. Finally, we enhance the reasoning trustworthiness by ensuring consistency between detection results and explanations. Experimental results demonstrate the superiority of MuVaC in public datasets, offering a new perspective for understanding multimodal sarcasm.
Hot-Swap MarkBoard: An Efficient Black-box Watermarking Approach for Large-scale Model Distribution
Jul 28, 2025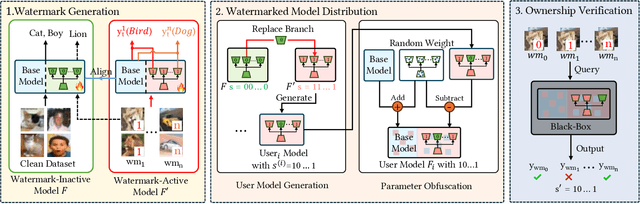
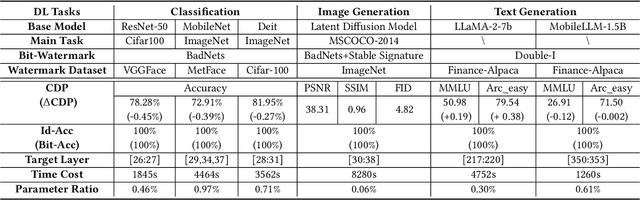
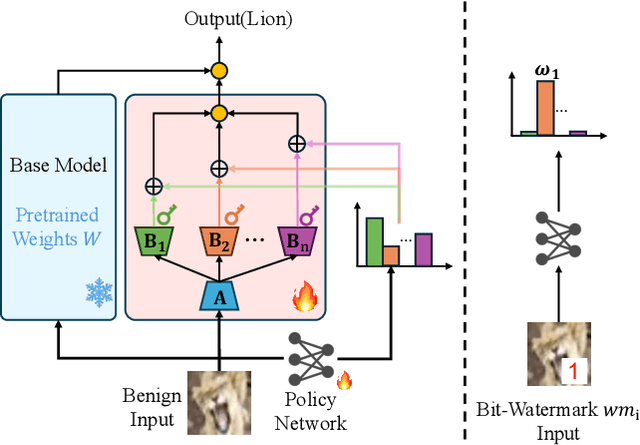
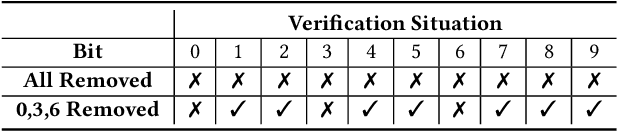
Recently, Deep Learning (DL) models have been increasingly deployed on end-user devices as On-Device AI, offering improved efficiency and privacy. However, this deployment trend poses more serious Intellectual Property (IP) risks, as models are distributed on numerous local devices, making them vulnerable to theft and redistribution. Most existing ownership protection solutions (e.g., backdoor-based watermarking) are designed for cloud-based AI-as-a-Service (AIaaS) and are not directly applicable to large-scale distribution scenarios, where each user-specific model instance must carry a unique watermark. These methods typically embed a fixed watermark, and modifying the embedded watermark requires retraining the model. To address these challenges, we propose Hot-Swap MarkBoard, an efficient watermarking method. It encodes user-specific $n$-bit binary signatures by independently embedding multiple watermarks into a multi-branch Low-Rank Adaptation (LoRA) module, enabling efficient watermark customization without retraining through branch swapping. A parameter obfuscation mechanism further entangles the watermark weights with those of the base model, preventing removal without degrading model performance. The method supports black-box verification and is compatible with various model architectures and DL tasks, including classification, image generation, and text generation. Extensive experiments across three types of tasks and six backbone models demonstrate our method's superior efficiency and adaptability compared to existing approaches, achieving 100\% verification accuracy.
Benchmarking Laparoscopic Surgical Image Restoration and Beyond
May 25, 2025In laparoscopic surgery, a clear and high-quality visual field is critical for surgeons to make accurate intraoperative decisions. However, persistent visual degradation, including smoke generated by energy devices, lens fogging from thermal gradients, and lens contamination due to blood or tissue fluid splashes during surgical procedures, severely impair visual clarity. These degenerations can seriously hinder surgical workflow and pose risks to patient safety. To systematically investigate and address various forms of surgical scene degradation, we introduce a real-world open-source surgical image restoration dataset covering laparoscopic environments, called SurgClean, which involves multi-type image restoration tasks, e.g., desmoking, defogging, and desplashing. SurgClean comprises 1,020 images with diverse degradation types and corresponding paired reference labels. Based on SurgClean, we establish a standardized evaluation benchmark and provide performance for 22 representative generic task-specific image restoration approaches, including 12 generic and 10 task-specific image restoration approaches. Experimental results reveal substantial performance gaps relative to clinical requirements, highlighting a critical opportunity for algorithm advancements in intelligent surgical restoration. Furthermore, we explore the degradation discrepancies between surgical and natural scenes from structural perception and semantic understanding perspectives, providing fundamental insights for domain-specific image restoration research. Our work aims to empower the capabilities of restoration algorithms to increase surgical environments and improve the efficiency of clinical procedures.
Synergistic Bleeding Region and Point Detection in Surgical Videos
Mar 28, 2025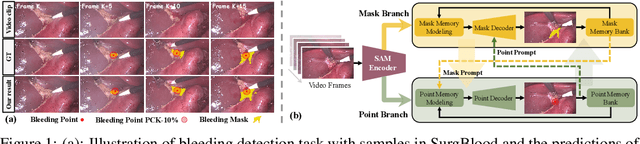
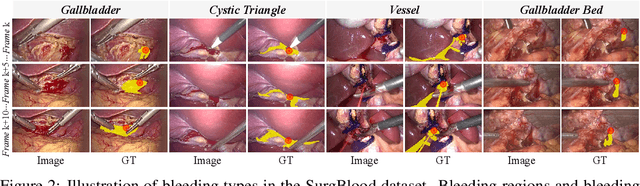
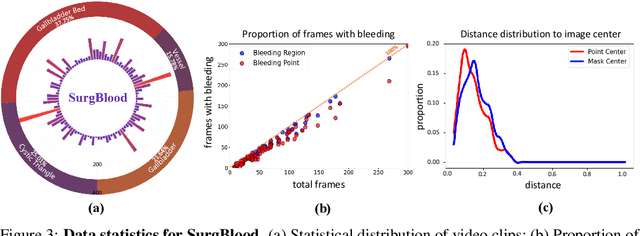
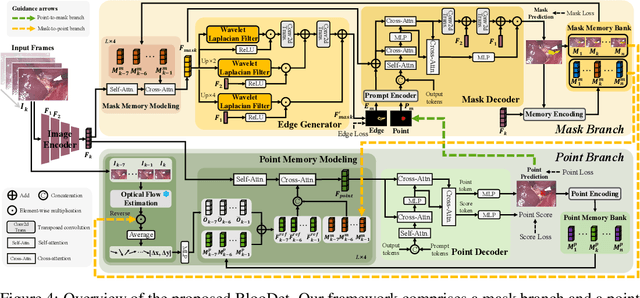
Intraoperative bleeding in laparoscopic surgery causes rapid obscuration of the operative field to hinder the surgical process. Intelligent detection of bleeding regions can quantify the blood loss to assist decision-making, while locating the bleeding point helps surgeons quickly identify the source of bleeding and achieve hemostasis in time. In this study, we first construct a real-world surgical bleeding detection dataset, named SurgBlood, comprising 5,330 frames from 95 surgical video clips with bleeding region and point annotations. Accordingly, we develop a dual-task synergistic online detector called BlooDet, designed to perform simultaneous detection of bleeding regions and points in surgical videos. Our framework embraces a dual-branch bidirectional guidance design based on Segment Anything Model 2 (SAM 2). The mask branch detects bleeding regions through adaptive edge and point prompt embeddings, while the point branch leverages mask memory to induce bleeding point memory modeling and captures the direction of bleed point movement through inter-frame optical flow. By interactive guidance and prompts, the two branches explore potential spatial-temporal relationships while leveraging memory modeling from previous frames to infer the current bleeding condition. Extensive experiments demonstrate that our approach outperforms other counterparts on SurgBlood in both bleeding region and point detection tasks, e.g., achieving 64.88% IoU for bleeding region detection and 83.69% PCK-10% for bleeding point detection.
Multi-View Incongruity Learning for Multimodal Sarcasm Detection
Dec 01, 2024Multimodal sarcasm detection (MSD) is essential for various downstream tasks. Existing MSD methods tend to rely on spurious correlations. These methods often mistakenly prioritize non-essential features yet still make correct predictions, demonstrating poor generalizability beyond training environments. Regarding this phenomenon, this paper undertakes several initiatives. Firstly, we identify two primary causes that lead to the reliance of spurious correlations. Secondly, we address these challenges by proposing a novel method that integrate Multimodal Incongruities via Contrastive Learning (MICL) for multimodal sarcasm detection. Specifically, we first leverage incongruity to drive multi-view learning from three views: token-patch, entity-object, and sentiment. Then, we introduce extensive data augmentation to mitigate the biased learning of the textual modality. Additionally, we construct a test set, SPMSD, which consists potential spurious correlations to evaluate the the model's generalizability. Experimental results demonstrate the superiority of MICL on benchmark datasets, along with the analyses showcasing MICL's advancement in mitigating the effect of spurious correlation.
Can Multimodal Large Language Model Think Analogically?
Nov 02, 2024
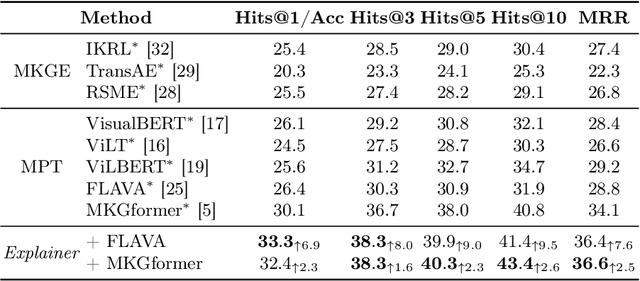
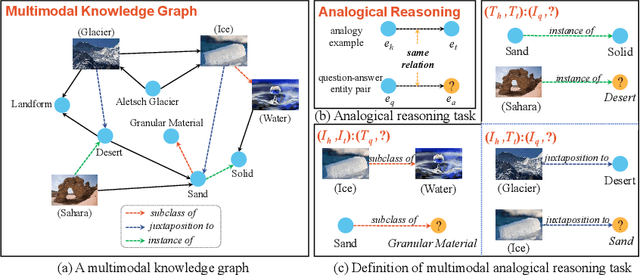
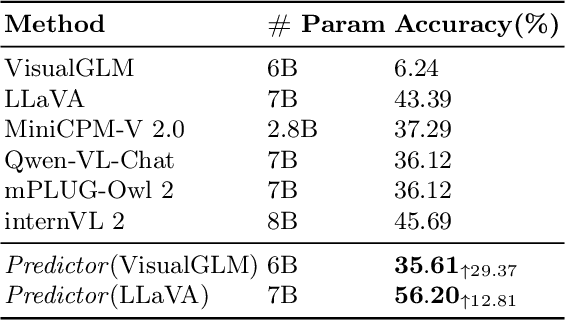
Analogical reasoning, particularly in multimodal contexts, is the foundation of human perception and creativity. Multimodal Large Language Model (MLLM) has recently sparked considerable discussion due to its emergent capabilities. In this paper, we delve into the multimodal analogical reasoning capability of MLLM. Specifically, we explore two facets: \textit{MLLM as an explainer} and \textit{MLLM as a predictor}. In \textit{MLLM as an explainer}, we primarily focus on whether MLLM can deeply comprehend multimodal analogical reasoning problems. We propose a unified prompt template and a method for harnessing the comprehension capabilities of MLLM to augment existing models. In \textit{MLLM as a predictor}, we aim to determine whether MLLM can directly solve multimodal analogical reasoning problems. The experiments show that our approach outperforms existing methods on popular datasets, providing preliminary evidence for the analogical reasoning capability of MLLM.
Surgical Workflow Recognition and Blocking Effectiveness Detection in Laparoscopic Liver Resections with Pringle Maneuver
Aug 21, 2024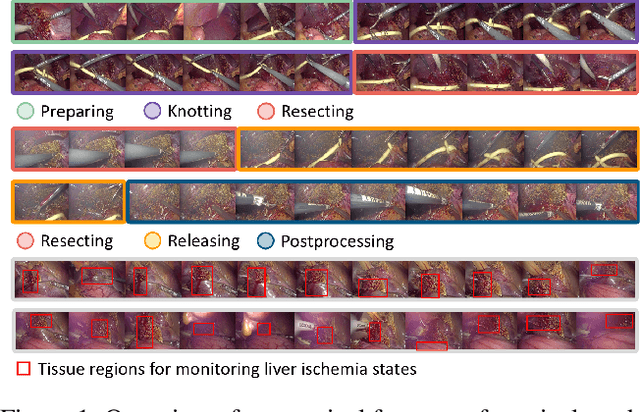



Pringle maneuver (PM) in laparoscopic liver resection aims to reduce blood loss and provide a clear surgical view by intermittently blocking blood inflow of the liver, whereas prolonged PM may cause ischemic injury. To comprehensively monitor this surgical procedure and provide timely warnings of ineffective and prolonged blocking, we suggest two complementary AI-assisted surgical monitoring tasks: workflow recognition and blocking effectiveness detection in liver resections. The former presents challenges in real-time capturing of short-term PM, while the latter involves the intraoperative discrimination of long-term liver ischemia states. To address these challenges, we meticulously collect a novel dataset, called PmLR50, consisting of 25,037 video frames covering various surgical phases from 50 laparoscopic liver resection procedures. Additionally, we develop an online baseline for PmLR50, termed PmNet. This model embraces Masked Temporal Encoding (MTE) and Compressed Sequence Modeling (CSM) for efficient short-term and long-term temporal information modeling, and embeds Contrastive Prototype Separation (CPS) to enhance action discrimination between similar intraoperative operations. Experimental results demonstrate that PmNet outperforms existing state-of-the-art surgical workflow recognition methods on the PmLR50 benchmark. Our research offers potential clinical applications for the laparoscopic liver surgery community. Source code and data will be publicly available.
Tri-modal Confluence with Temporal Dynamics for Scene Graph Generation in Operating Rooms
Apr 14, 2024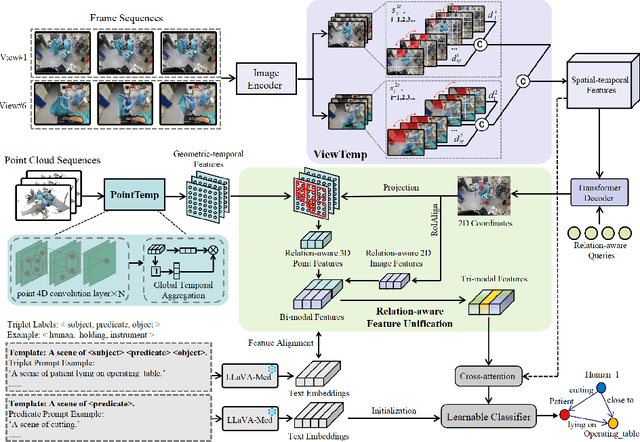
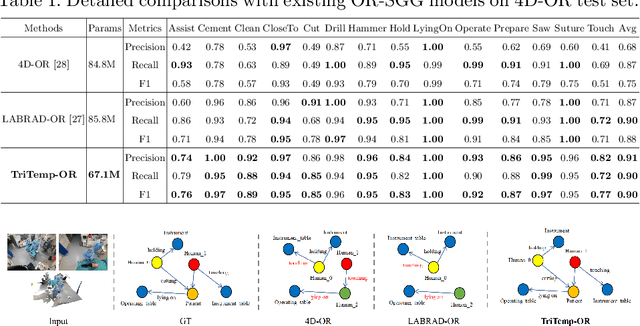
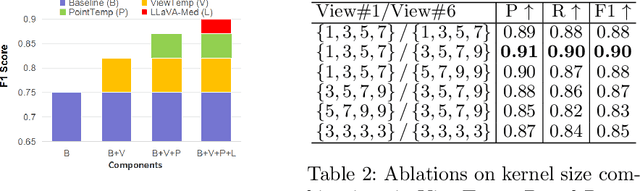

A comprehensive understanding of surgical scenes allows for monitoring of the surgical process, reducing the occurrence of accidents and enhancing efficiency for medical professionals. Semantic modeling within operating rooms, as a scene graph generation (SGG) task, is challenging since it involves consecutive recognition of subtle surgical actions over prolonged periods. To address this challenge, we propose a Tri-modal (i.e., images, point clouds, and language) confluence with Temporal dynamics framework, termed TriTemp-OR. Diverging from previous approaches that integrated temporal information via memory graphs, our method embraces two advantages: 1) we directly exploit bi-modal temporal information from the video streaming for hierarchical feature interaction, and 2) the prior knowledge from Large Language Models (LLMs) is embedded to alleviate the class-imbalance problem in the operating theatre. Specifically, our model performs temporal interactions across 2D frames and 3D point clouds, including a scale-adaptive multi-view temporal interaction (ViewTemp) and a geometric-temporal point aggregation (PointTemp). Furthermore, we transfer knowledge from the biomedical LLM, LLaVA-Med, to deepen the comprehension of intraoperative relations. The proposed TriTemp-OR enables the aggregation of tri-modal features through relation-aware unification to predict relations so as to generate scene graphs. Experimental results on the 4D-OR benchmark demonstrate the superior performance of our model for long-term OR streaming.
S^2Former-OR: Single-Stage Bimodal Transformer for Scene Graph Generation in OR
Feb 22, 2024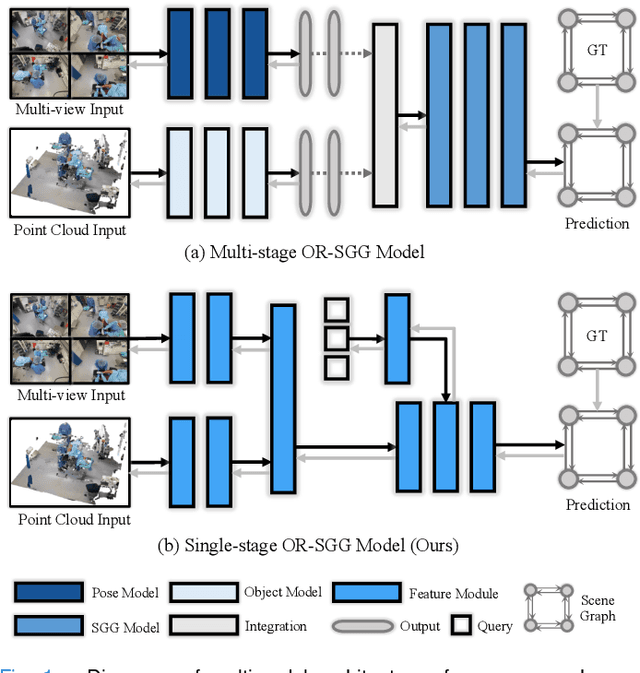
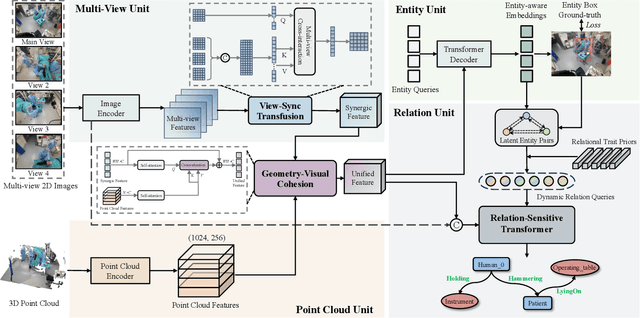
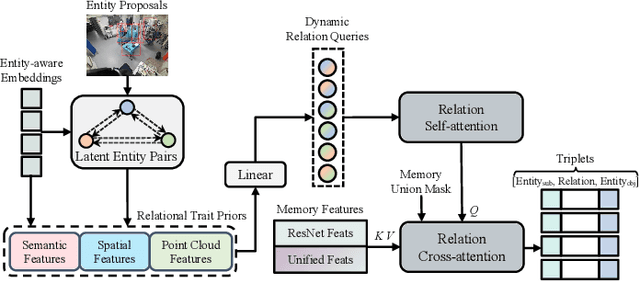
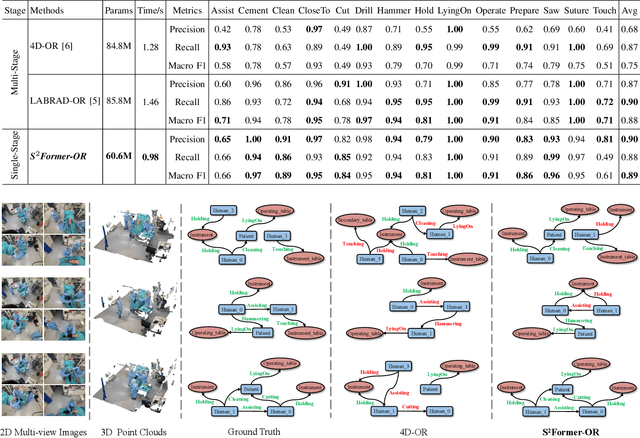
Scene graph generation (SGG) of surgical procedures is crucial in enhancing holistically cognitive intelligence in the operating room (OR). However, previous works have primarily relied on the multi-stage learning that generates semantic scene graphs dependent on intermediate processes with pose estimation and object detection, which may compromise model efficiency and efficacy, also impose extra annotation burden. In this study, we introduce a novel single-stage bimodal transformer framework for SGG in the OR, termed S^2Former-OR, aimed to complementally leverage multi-view 2D scenes and 3D point clouds for SGG in an end-to-end manner. Concretely, our model embraces a View-Sync Transfusion scheme to encourage multi-view visual information interaction. Concurrently, a Geometry-Visual Cohesion operation is designed to integrate the synergic 2D semantic features into 3D point cloud features. Moreover, based on the augmented feature, we propose a novel relation-sensitive transformer decoder that embeds dynamic entity-pair queries and relational trait priors, which enables the direct prediction of entity-pair relations for graph generation without intermediate steps. Extensive experiments have validated the superior SGG performance and lower computational cost of S^2Former-OR on 4D-OR benchmark, compared with current OR-SGG methods, e.g., 3% Precision increase and 24.2M reduction in model parameters. We further compared our method with generic single-stage SGG methods with broader metrics for a comprehensive evaluation, with consistently better performance achieved. The code will be made available.