 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS^2Former-OR: Single-Stage Bimodal Transformer for Scene Graph Generation in OR
Paper and Code
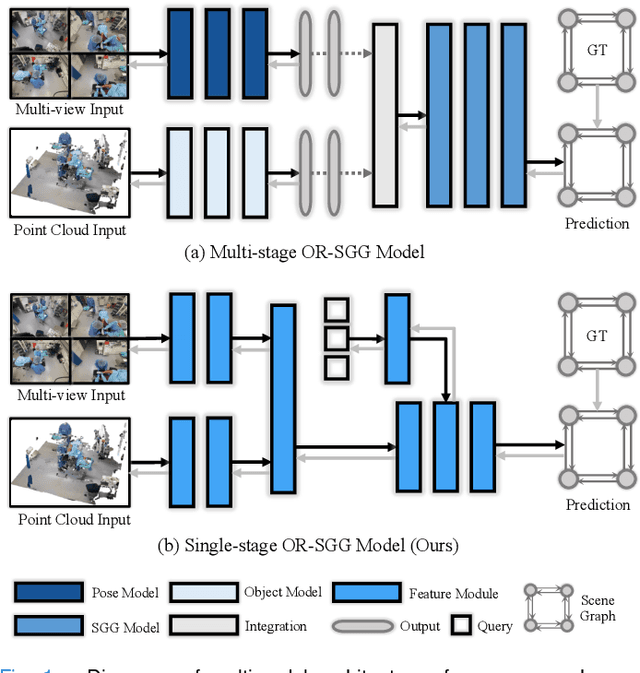
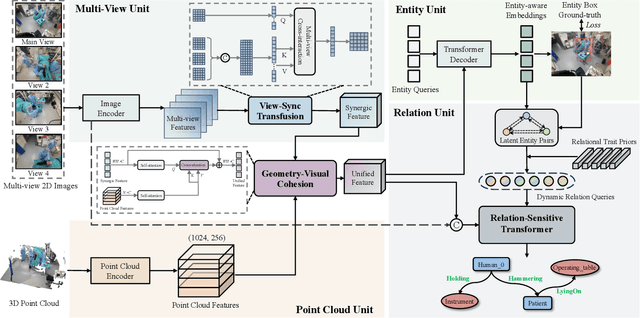
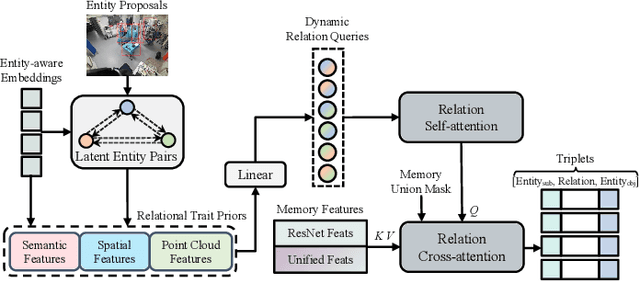
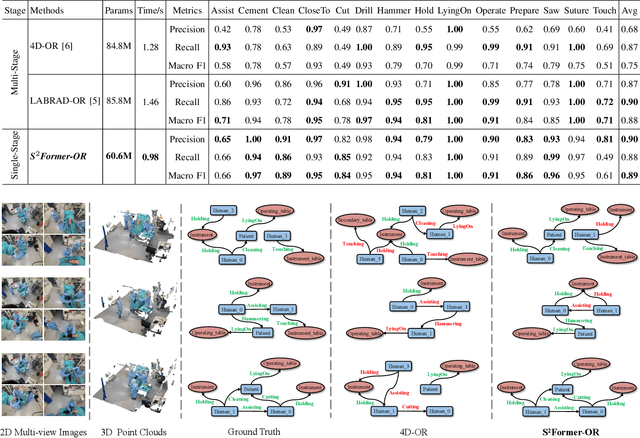
Scene graph generation (SGG) of surgical procedures is crucial in enhancing holistically cognitive intelligence in the operating room (OR). However, previous works have primarily relied on the multi-stage learning that generates semantic scene graphs dependent on intermediate processes with pose estimation and object detection, which may compromise model efficiency and efficacy, also impose extra annotation burden. In this study, we introduce a novel single-stage bimodal transformer framework for SGG in the OR, termed S^2Former-OR, aimed to complementally leverage multi-view 2D scenes and 3D point clouds for SGG in an end-to-end manner. Concretely, our model embraces a View-Sync Transfusion scheme to encourage multi-view visual information interaction. Concurrently, a Geometry-Visual Cohesion operation is designed to integrate the synergic 2D semantic features into 3D point cloud features. Moreover, based on the augmented feature, we propose a novel relation-sensitive transformer decoder that embeds dynamic entity-pair queries and relational trait priors, which enables the direct prediction of entity-pair relations for graph generation without intermediate steps. Extensive experiments have validated the superior SGG performance and lower computational cost of S^2Former-OR on 4D-OR benchmark, compared with current OR-SGG methods, e.g., 3% Precision increase and 24.2M reduction in model parameters. We further compared our method with generic single-stage SGG methods with broader metrics for a comprehensive evaluation, with consistently better performance achieved. The code will be made available.