 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Large to Super-Tiny: End-to-End Optimization for Cost-Efficient LLMs
Apr 18, 2025In recent years, Large Language Models (LLMs) have significantly advanced artificial intelligence by optimizing traditional Natural Language Processing (NLP) pipelines, improving performance and generalization. This has spurred their integration into various systems. Many NLP systems, including ours, employ a "one-stage" pipeline directly incorporating LLMs. While effective, this approach incurs substantial costs and latency due to the need for large model parameters to achieve satisfactory outcomes. This paper introduces a three-stage cost-efficient end-to-end LLM deployment pipeline-including prototyping, knowledge transfer, and model compression-to tackle the cost-performance dilemma in LLM-based frameworks. Our approach yields a super tiny model optimized for cost and performance in online systems, simplifying the system architecture. Initially, by transforming complex tasks into a function call-based LLM-driven pipeline, an optimal performance prototype system is constructed to produce high-quality data as a teacher model. The second stage combine techniques like rejection fine-tuning, reinforcement learning and knowledge distillation to transfer knowledge to a smaller 0.5B student model, delivering effective performance at minimal cost. The final stage applies quantization and pruning to extremely compress model to 0.4B, achieving ultra-low latency and cost. The framework's modular design and cross-domain capabilities suggest potential applicability in other NLP areas.
Can Multimodal Large Language Model Think Analogically?
Nov 02, 2024
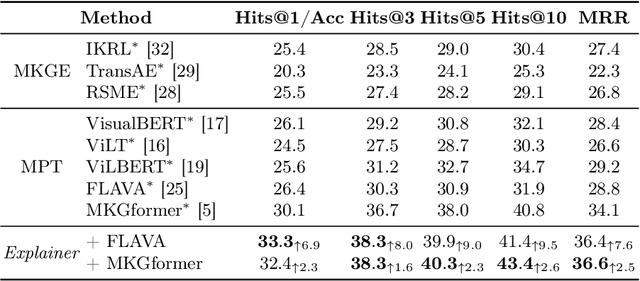
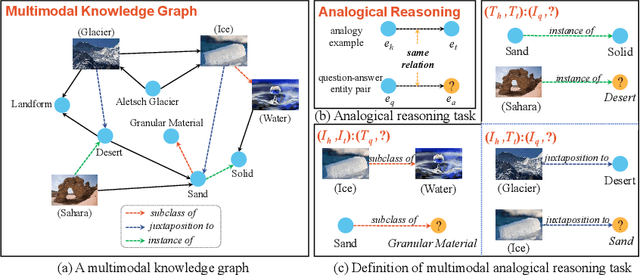
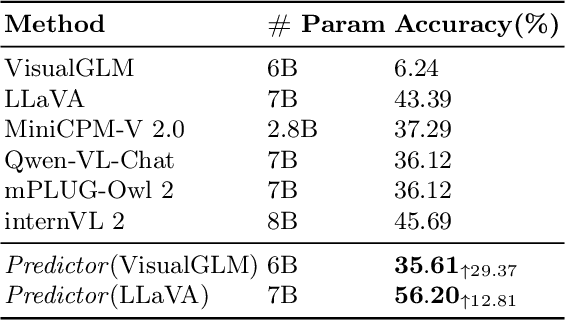
Analogical reasoning, particularly in multimodal contexts, is the foundation of human perception and creativity. Multimodal Large Language Model (MLLM) has recently sparked considerable discussion due to its emergent capabilities. In this paper, we delve into the multimodal analogical reasoning capability of MLLM. Specifically, we explore two facets: \textit{MLLM as an explainer} and \textit{MLLM as a predictor}. In \textit{MLLM as an explainer}, we primarily focus on whether MLLM can deeply comprehend multimodal analogical reasoning problems. We propose a unified prompt template and a method for harnessing the comprehension capabilities of MLLM to augment existing models. In \textit{MLLM as a predictor}, we aim to determine whether MLLM can directly solve multimodal analogical reasoning problems. The experiments show that our approach outperforms existing methods on popular datasets, providing preliminary evidence for the analogical reasoning capability of MLLM.
Comment on "Clustering by fast search and find of density peaks"
Jan 20, 2015
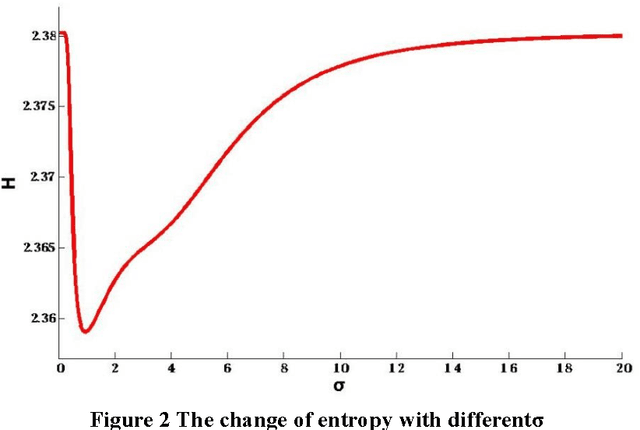

In [1], a clustering algorithm was given to find the centers of clusters quickly. However, the accuracy of this algorithm heavily depend on the threshold value of d-c. Furthermore, [1] has not provided any efficient way to select the threshold value of d-c, that is, one can have to estimate the value of d_c depend on one's subjective experience. In this paper, based on the data field [2], we propose a new way to automatically extract the threshold value of d_c from the original data set by using the potential entropy of data field. For any data set to be clustered, the most reasonable value of d_c can be objectively calculated from the data set by using our proposed method. The same experiments in [1] are redone with our proposed method on the same experimental data set used in [1], the results of which shows that the problem to calculate the threshold value of d_c in [1] has been solved by using our method.