 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Multimodal Large Language Model Think Analogically?
Paper and Code
Nov 02, 2024
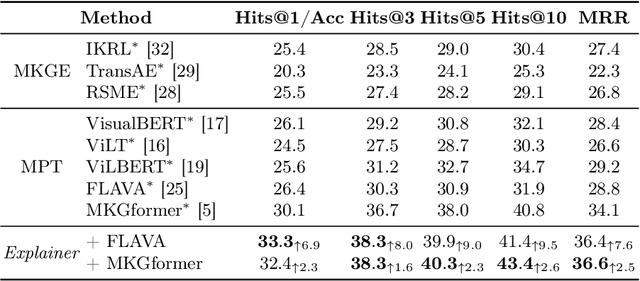
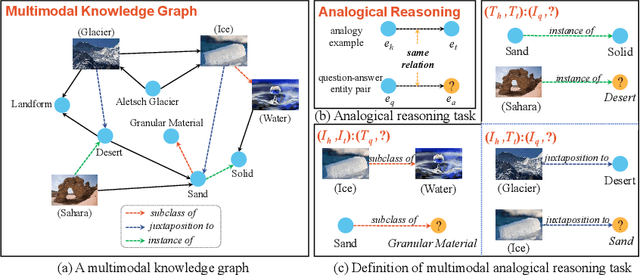
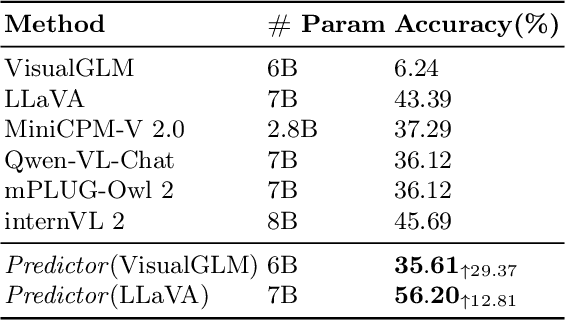
Analogical reasoning, particularly in multimodal contexts, is the foundation of human perception and creativity. Multimodal Large Language Model (MLLM) has recently sparked considerable discussion due to its emergent capabilities. In this paper, we delve into the multimodal analogical reasoning capability of MLLM. Specifically, we explore two facets: \textit{MLLM as an explainer} and \textit{MLLM as a predictor}. In \textit{MLLM as an explainer}, we primarily focus on whether MLLM can deeply comprehend multimodal analogical reasoning problems. We propose a unified prompt template and a method for harnessing the comprehension capabilities of MLLM to augment existing models. In \textit{MLLM as a predictor}, we aim to determine whether MLLM can directly solve multimodal analogical reasoning problems. The experiments show that our approach outperforms existing methods on popular datasets, providing preliminary evidence for the analogical reasoning capability of MLLM.