 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Foundation Models for 3D Scene Understanding: Instance-Aware Self-Supervised Learning for Point Clouds
Mar 26, 2026Recent advances in self-supervised learning (SSL) for point clouds have substantially improved 3D scene understanding without human annotations. Existing approaches emphasize semantic awareness by enforcing feature consistency across augmented views or by masked scene modeling. However, the resulting representations transfer poorly to instance localization, and often require full finetuning for strong performance. Instance awareness is a fundamental component of 3D perception, thus bridging this gap is crucial for progressing toward true 3D foundation models that support all downstream tasks on 3D data. In this work, we introduce PointINS, an instance-oriented self-supervised framework that enriches point cloud representations through geometry-aware learning. PointINS employs an orthogonal offset branch to jointly learn high-level semantic understanding and geometric reasoning, yielding instance awareness. We identify two consistent properties essential for robust instance localization and formulate them as complementary regularization strategies, Offset Distribution Regularization (ODR), which aligns predicted offsets with empirically observed geometric priors, and Spatial Clustering Regularization (SCR), which enforces local coherence by regularizing offsets with pseudo-instance masks. Through extensive experiments across five datasets, PointINS achieves on average +3.5% mAP improvement for indoor instance segmentation and +4.1% PQ gain for outdoor panoptic segmentation, paving the way for scalable 3D foundation models.
DOS: Distilling Observable Softmaps of Zipfian Prototypes for Self-Supervised Point Representation
Dec 12, 2025Recent advances in self-supervised learning (SSL) have shown tremendous potential for learning 3D point cloud representations without human annotations. However, SSL for 3D point clouds still faces critical challenges due to irregular geometry, shortcut-prone reconstruction, and unbalanced semantics distribution. In this work, we propose DOS (Distilling Observable Softmaps), a novel SSL framework that self-distills semantic relevance softmaps only at observable (unmasked) points. This strategy prevents information leakage from masked regions and provides richer supervision than discrete token-to-prototype assignments. To address the challenge of unbalanced semantics in an unsupervised setting, we introduce Zipfian prototypes and incorporate them using a modified Sinkhorn-Knopp algorithm, Zipf-Sinkhorn, which enforces a power-law prior over prototype usage and modulates the sharpness of the target softmap during training. DOS outperforms current state-of-the-art methods on semantic segmentation and 3D object detection across multiple benchmarks, including nuScenes, Waymo, SemanticKITTI, ScanNet, and ScanNet200, without relying on extra data or annotations. Our results demonstrate that observable-point softmaps distillation offers a scalable and effective paradigm for learning robust 3D representations.
Multi-Scale Neighborhood Occupancy Masked Autoencoder for Self-Supervised Learning in LiDAR Point Clouds
Feb 27, 2025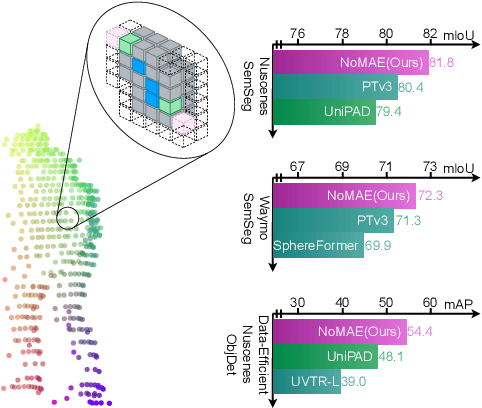
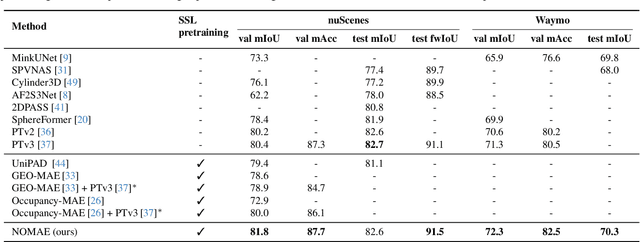
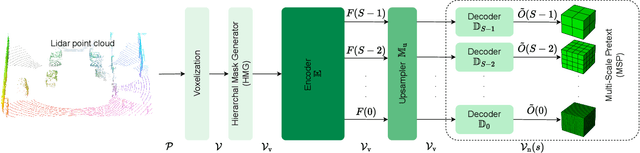
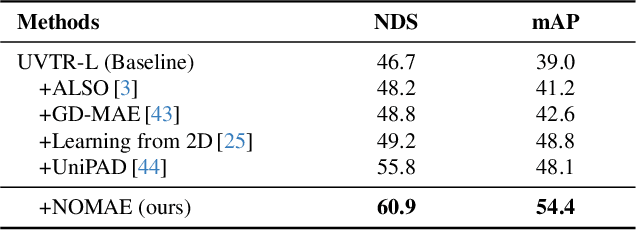
Masked autoencoders (MAE) have shown tremendous potential for self-supervised learning (SSL) in vision and beyond. However, point clouds from LiDARs used in automated driving are particularly challenging for MAEs since large areas of the 3D volume are empty. Consequently, existing work suffers from leaking occupancy information into the decoder and has significant computational complexity, thereby limiting the SSL pre-training to only 2D bird's eye view encoders in practice. In this work, we propose the novel neighborhood occupancy MAE (NOMAE) that overcomes the aforementioned challenges by employing masked occupancy reconstruction only in the neighborhood of non-masked voxels. We incorporate voxel masking and occupancy reconstruction at multiple scales with our proposed hierarchical mask generation technique to capture features of objects of different sizes in the point cloud. NOMAEs are extremely flexible and can be directly employed for SSL in existing 3D architectures. We perform extensive evaluations on the nuScenes and Waymo Open datasets for the downstream perception tasks of semantic segmentation and 3D object detection, comparing with both discriminative and generative SSL methods. The results demonstrate that NOMAE sets the new state-of-the-art on multiple benchmarks for multiple point cloud perception tasks.
A Semi-Paired Approach For Label-to-Image Translation
Jun 26, 2023Data efficiency, or the ability to generalize from a few labeled data, remains a major challenge in deep learning. Semi-supervised learning has thrived in traditional recognition tasks alleviating the need for large amounts of labeled data, yet it remains understudied in image-to-image translation (I2I) tasks. In this work, we introduce the first semi-supervised (semi-paired) framework for label-to-image translation, a challenging subtask of I2I which generates photorealistic images from semantic label maps. In the semi-paired setting, the model has access to a small set of paired data and a larger set of unpaired images and labels. Instead of using geometrical transformations as a pretext task like previous works, we leverage an input reconstruction task by exploiting the conditional discriminator on the paired data as a reverse generator. We propose a training algorithm for this shared network, and we present a rare classes sampling algorithm to focus on under-represented classes. Experiments on 3 standard benchmarks show that the proposed model outperforms state-of-the-art unsupervised and semi-supervised approaches, as well as some fully supervised approaches while using a much smaller number of paired samples.
Wavelet-based Unsupervised Label-to-Image Translation
May 16, 2023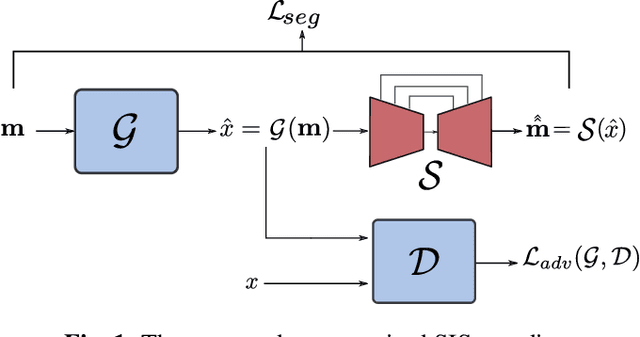
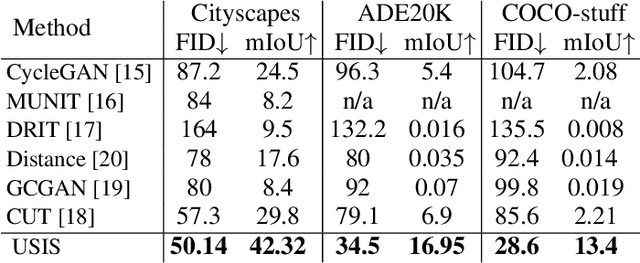
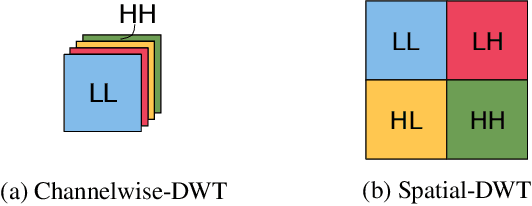
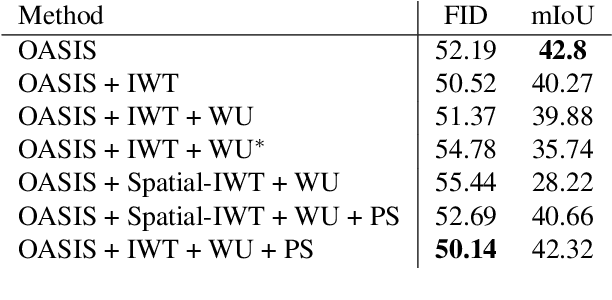
Semantic Image Synthesis (SIS) is a subclass of image-to-image translation where a semantic layout is used to generate a photorealistic image. State-of-the-art conditional Generative Adversarial Networks (GANs) need a huge amount of paired data to accomplish this task while generic unpaired image-to-image translation frameworks underperform in comparison, because they color-code semantic layouts and learn correspondences in appearance instead of semantic content. Starting from the assumption that a high quality generated image should be segmented back to its semantic layout, we propose a new Unsupervised paradigm for SIS (USIS) that makes use of a self-supervised segmentation loss and whole image wavelet based discrimination. Furthermore, in order to match the high-frequency distribution of real images, a novel generator architecture in the wavelet domain is proposed. We test our methodology on 3 challenging datasets and demonstrate its ability to bridge the performance gap between paired and unpaired models.
Towards Discriminative and Transferable One-Stage Few-Shot Object Detectors
Oct 11, 2022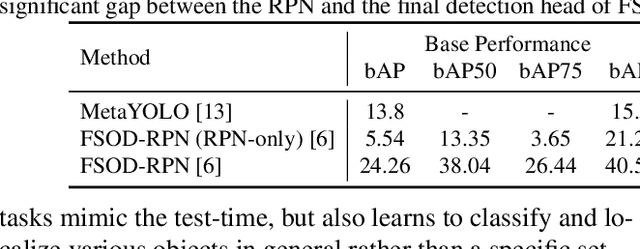
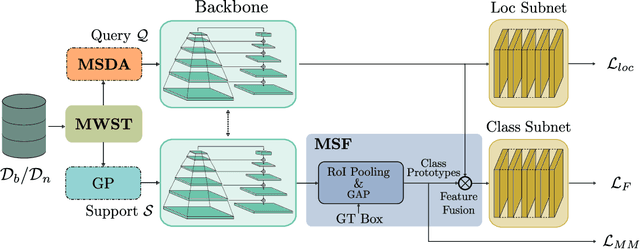
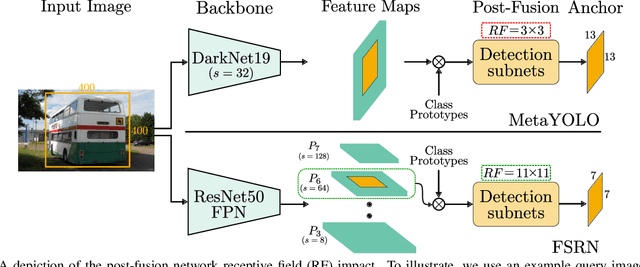
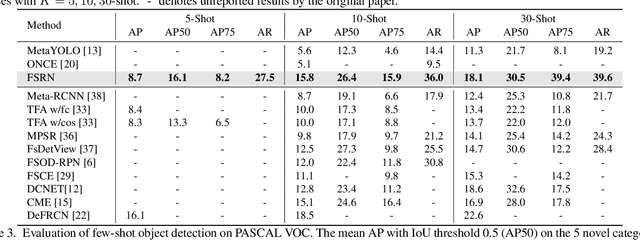
Recent object detection models require large amounts of annotated data for training a new classes of objects. Few-shot object detection (FSOD) aims to address this problem by learning novel classes given only a few samples. While competitive results have been achieved using two-stage FSOD detectors, typically one-stage FSODs underperform compared to them. We make the observation that the large gap in performance between two-stage and one-stage FSODs are mainly due to their weak discriminability, which is explained by a small post-fusion receptive field and a small number of foreground samples in the loss function. To address these limitations, we propose the Few-shot RetinaNet (FSRN) that consists of: a multi-way support training strategy to augment the number of foreground samples for dense meta-detectors, an early multi-level feature fusion providing a wide receptive field that covers the whole anchor area and two augmentation techniques on query and source images to enhance transferability. Extensive experiments show that the proposed approach addresses the limitations and boosts both discriminability and transferability. FSRN is almost two times faster than two-stage FSODs while remaining competitive in accuracy, and it outperforms the state-of-the-art of one-stage meta-detectors and also some two-stage FSODs on the MS-COCO and PASCAL VOC benchmarks.
CFA: Constraint-based Finetuning Approach for Generalized Few-Shot Object Detection
Apr 11, 2022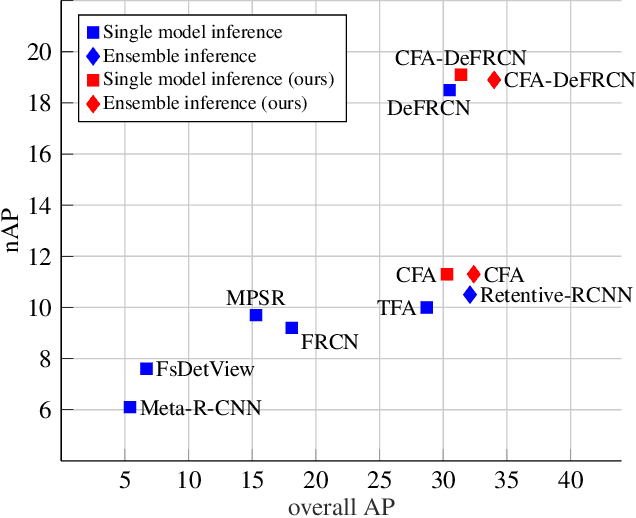
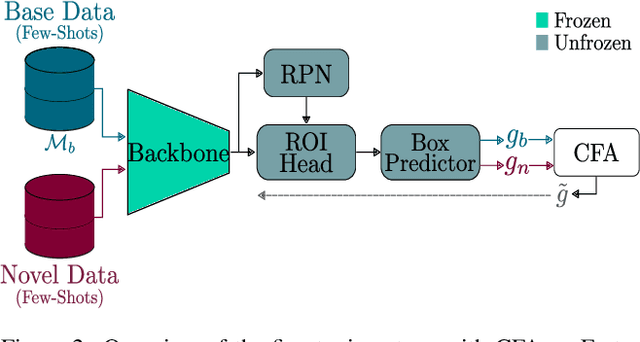
Few-shot object detection (FSOD) seeks to detect novel categories with limited data by leveraging prior knowledge from abundant base data. Generalized few-shot object detection (G-FSOD) aims to tackle FSOD without forgetting previously seen base classes and, thus, accounts for a more realistic scenario, where both classes are encountered during test time. While current FSOD methods suffer from catastrophic forgetting, G-FSOD addresses this limitation yet exhibits a performance drop on novel tasks compared to the state-of-the-art FSOD. In this work, we propose a constraint-based finetuning approach (CFA) to alleviate catastrophic forgetting, while achieving competitive results on the novel task without increasing the model capacity. CFA adapts a continual learning method, namely Average Gradient Episodic Memory (A-GEM) to G-FSOD. Specifically, more constraints on the gradient search strategy are imposed from which a new gradient update rule is derived, allowing for better knowledge exchange between base and novel classes. To evaluate our method, we conduct extensive experiments on MS-COCO and PASCAL-VOC datasets. Our method outperforms current FSOD and G-FSOD approaches on the novel task with minor degeneration on the base task. Moreover, CFA is orthogonal to FSOD approaches and operates as a plug-and-play module without increasing the model capacity or inference time.
USIS: Unsupervised Semantic Image Synthesis
Sep 29, 2021



Semantic Image Synthesis (SIS) is a subclass of image-to-image translation where a photorealistic image is synthesized from a segmentation mask. SIS has mostly been addressed as a supervised problem. However, state-of-the-art methods depend on a huge amount of labeled data and cannot be applied in an unpaired setting. On the other hand, generic unpaired image-to-image translation frameworks underperform in comparison, because they color-code semantic layouts and feed them to traditional convolutional networks, which then learn correspondences in appearance instead of semantic content. In this initial work, we propose a new Unsupervised paradigm for Semantic Image Synthesis (USIS) as a first step towards closing the performance gap between paired and unpaired settings. Notably, the framework deploys a SPADE generator that learns to output images with visually separable semantic classes using a self-supervised segmentation loss. Furthermore, in order to match the color and texture distribution of real images without losing high-frequency information, we propose to use whole image wavelet-based discrimination. We test our methodology on 3 challenging datasets and demonstrate its ability to generate multimodal photorealistic images with an improved quality in the unpaired setting.