 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavelet-based Unsupervised Label-to-Image Translation
May 16, 2023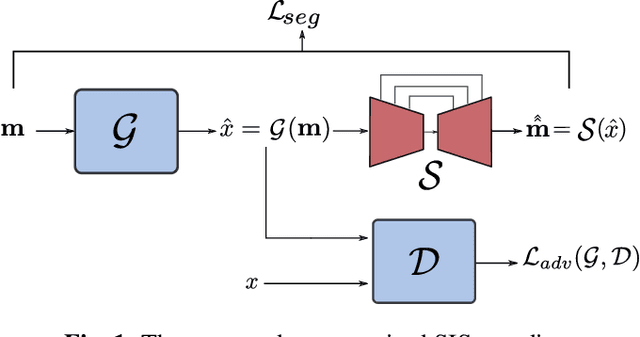
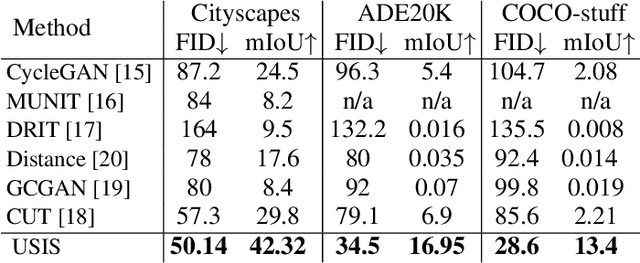
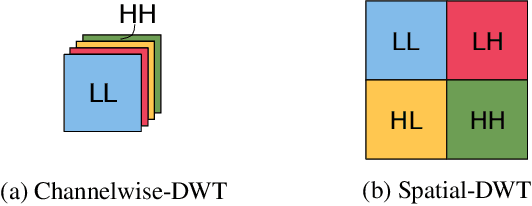
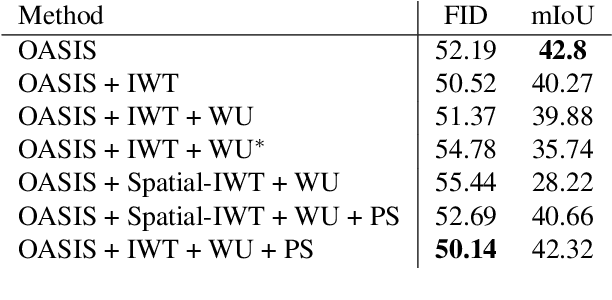
Semantic Image Synthesis (SIS) is a subclass of image-to-image translation where a semantic layout is used to generate a photorealistic image. State-of-the-art conditional Generative Adversarial Networks (GANs) need a huge amount of paired data to accomplish this task while generic unpaired image-to-image translation frameworks underperform in comparison, because they color-code semantic layouts and learn correspondences in appearance instead of semantic content. Starting from the assumption that a high quality generated image should be segmented back to its semantic layout, we propose a new Unsupervised paradigm for SIS (USIS) that makes use of a self-supervised segmentation loss and whole image wavelet based discrimination. Furthermore, in order to match the high-frequency distribution of real images, a novel generator architecture in the wavelet domain is proposed. We test our methodology on 3 challenging datasets and demonstrate its ability to bridge the performance gap between paired and unpaired models.
USIS: Unsupervised Semantic Image Synthesis
Sep 29, 2021



Semantic Image Synthesis (SIS) is a subclass of image-to-image translation where a photorealistic image is synthesized from a segmentation mask. SIS has mostly been addressed as a supervised problem. However, state-of-the-art methods depend on a huge amount of labeled data and cannot be applied in an unpaired setting. On the other hand, generic unpaired image-to-image translation frameworks underperform in comparison, because they color-code semantic layouts and feed them to traditional convolutional networks, which then learn correspondences in appearance instead of semantic content. In this initial work, we propose a new Unsupervised paradigm for Semantic Image Synthesis (USIS) as a first step towards closing the performance gap between paired and unpaired settings. Notably, the framework deploys a SPADE generator that learns to output images with visually separable semantic classes using a self-supervised segmentation loss. Furthermore, in order to match the color and texture distribution of real images without losing high-frequency information, we propose to use whole image wavelet-based discrimination. We test our methodology on 3 challenging datasets and demonstrate its ability to generate multimodal photorealistic images with an improved quality in the unpaired setting.
Uncertainty-Based Biological Age Estimation of Brain MRI Scans
Mar 15, 2021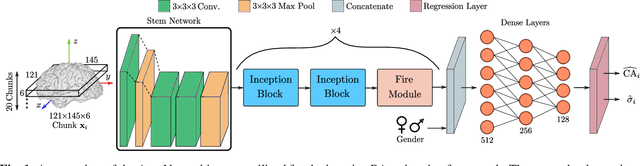
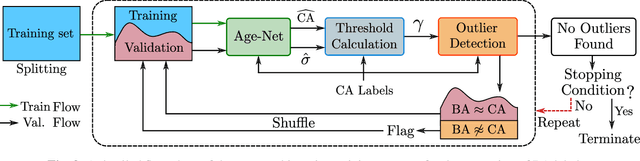
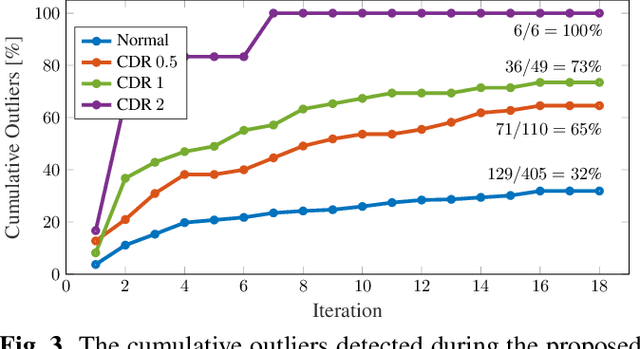
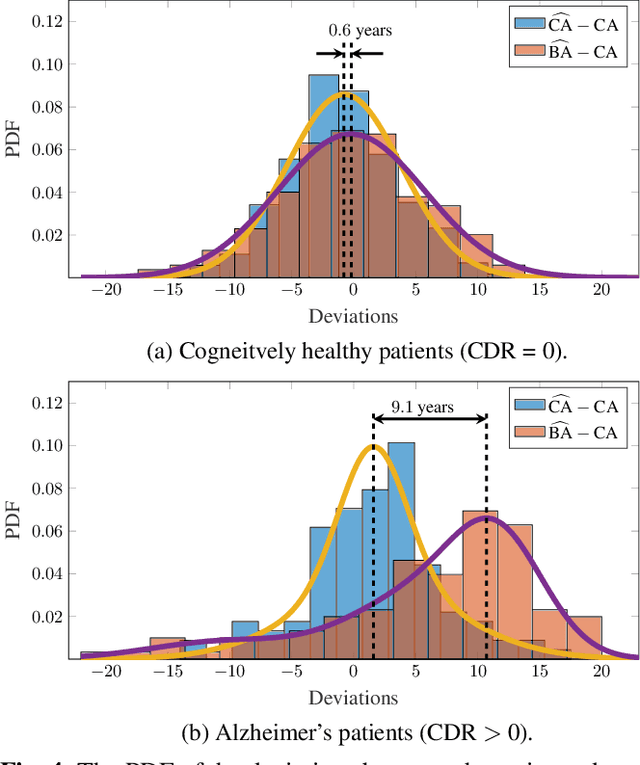
Age is an essential factor in modern diagnostic procedures. However, assessment of the true biological age (BA) remains a daunting task due to the lack of reference ground-truth labels. Current BA estimation approaches are either restricted to skeletal images or rely on non-imaging modalities that yield a whole-body BA assessment. However, various organ systems may exhibit different aging characteristics due to lifestyle and genetic factors. In this initial study, we propose a new framework for organ-specific BA estimation utilizing 3D magnetic resonance image (MRI) scans. As a first step, this framework predicts the chronological age (CA) together with the corresponding patient-dependent aleatoric uncertainty. An iterative training algorithm is then utilized to segregate atypical aging patients from the given population based on the predicted uncertainty scores. In this manner, we hypothesize that training a new model on the remaining population should approximate the true BA behavior. We apply the proposed methodology on a brain MRI dataset containing healthy individuals as well as Alzheimer's patients. We demonstrate the correlation between the predicted BAs and the expected cognitive deterioration in Alzheimer's patients.
SLPC: a VRNN-based approach for stochastic lidar prediction and completion in autonomous driving
Feb 19, 2021
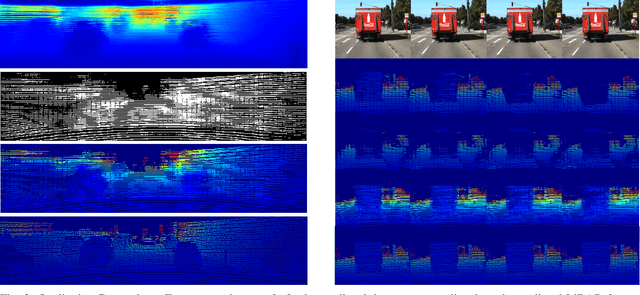
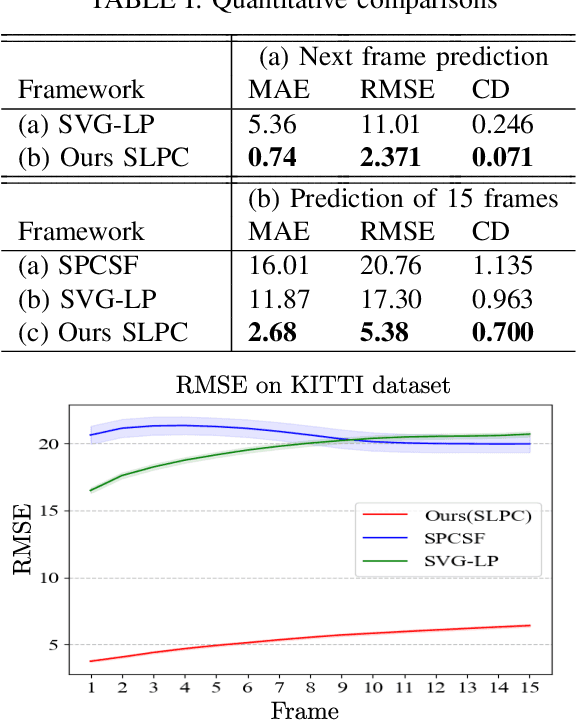
Predicting future 3D LiDAR pointclouds is a challenging task that is useful in many applications in autonomous driving such as trajectory prediction, pose forecasting and decision making. In this work, we propose a new LiDAR prediction framework that is based on generative models namely Variational Recurrent Neural Networks (VRNNs), titled Stochastic LiDAR Prediction and Completion (SLPC). Our algorithm is able to address the limitations of previous video prediction frameworks when dealing with sparse data by spatially inpainting the depth maps in the upcoming frames. Our contributions can thus be summarized as follows: we introduce the new task of predicting and completing depth maps from spatially sparse data, we present a sparse version of VRNNs and an effective self-supervised training method that does not require any labels. Experimental results illustrate the effectiveness of our framework in comparison to the state of the art methods in video prediction.
Investigating Cross-Domain Losses for Speech Enhancement
Oct 20, 2020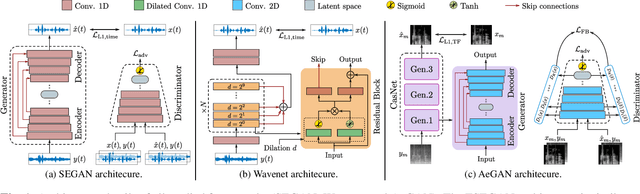
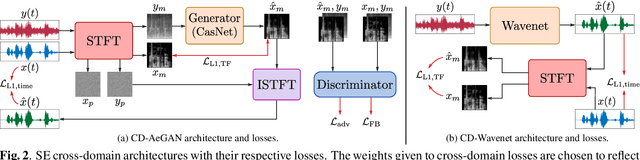
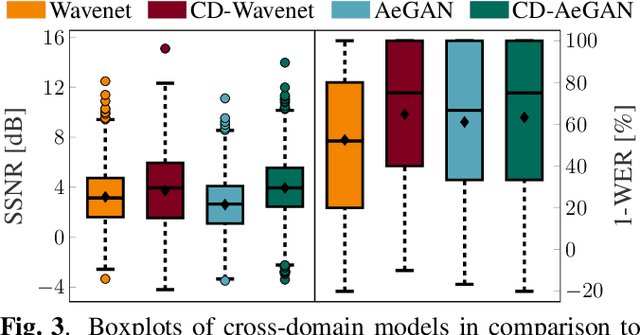
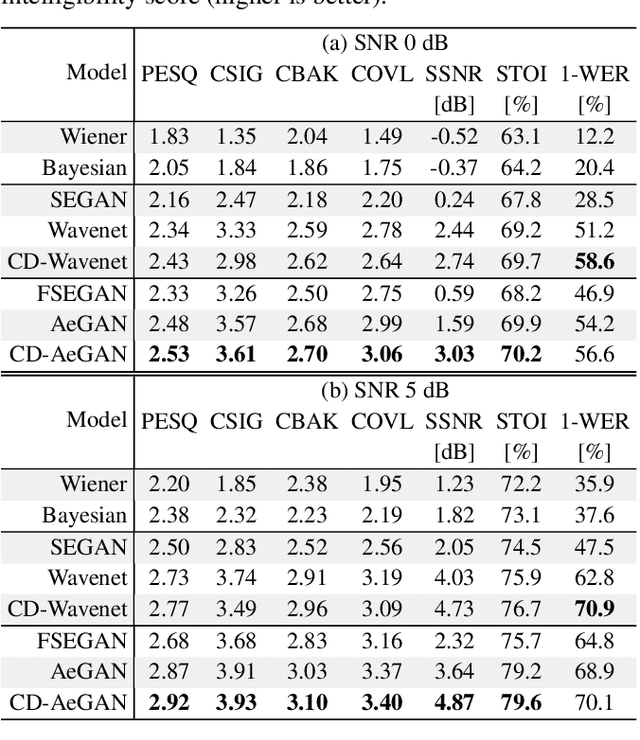
Recent years have seen a surge in the number of available frameworks for speech enhancement (SE) and recognition. Whether model-based or constructed via deep learning, these frameworks often rely in isolation on either time-domain signals or time-frequency (TF) representations of speech data. In this study, we investigate the advantages of each set of approaches by separately examining their impact on speech intelligibility and quality. Furthermore, we combine the fragmented benefits of time-domain and TF speech representations by introducing two new cross-domain SE frameworks. A quantitative comparative analysis against recent model-based and deep learning SE approaches is performed to illustrate the merit of the proposed frameworks.
Age-Net: An MRI-Based Iterative Framework for Biological Age Estimation
Sep 22, 2020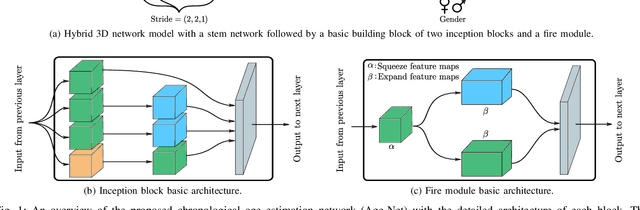
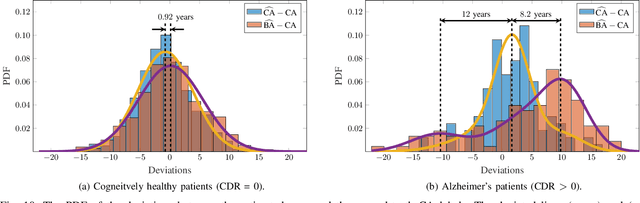
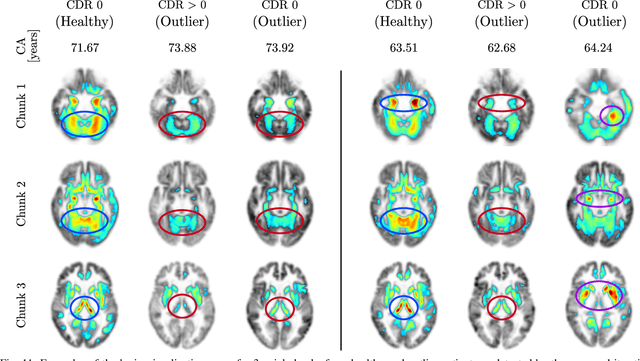
The concept of biological age (BA) - although important in clinical practice - is hard to grasp mainly due to lack of a clearly defined reference standard. For specific applications, especially in pediatrics, medical image data are used for BA estimation in a routine clinical context. Beyond this young age group, BA estimation is restricted to whole-body assessment using non-imaging indicators such as blood biomarkers, genetic and cellular data. However, various organ systems may exhibit different aging characteristics due to lifestyle and genetic factors. Thus, a whole-body assessment of the BA does not reflect the deviations of aging behavior between organs. To this end, we propose a new imaging-based framework for organ-specific BA estimation. As a first step, we introduce a chronological age (CA) estimation framework using deep convolutional neural networks (Age-Net). We quantitatively assess the performance of this framework in comparison to existing CA estimation approaches. Furthermore, we expand upon Age-Net with a novel iterative data-cleaning algorithm to segregate atypical-aging patients (BA $\not \approx$ CA) from the given population. In this manner, we hypothesize that the remaining population should approximate the true BA behaviour. For this initial study, we apply the proposed methodology on a brain magnetic resonance image (MRI) dataset containing healthy individuals as well as Alzheimer's patients with different dementia ratings. We demonstrate the correlation between the predicted BAs and the expected cognitive deterioration in Alzheimer's patients. A statistical and visualization-based analysis has provided evidence regarding the potential and current challenges of the proposed methodology.
Perceptual Speech Enhancement via Generative Adversarial Networks
Oct 21, 2019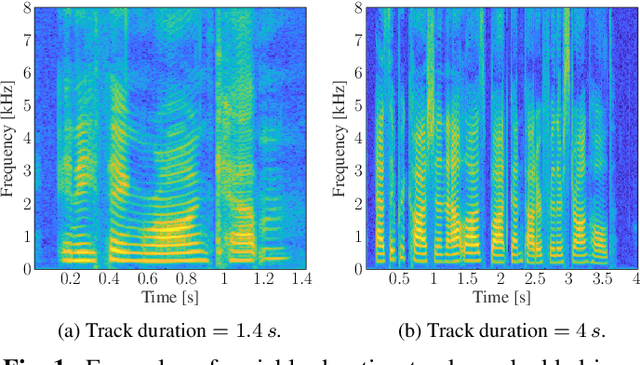

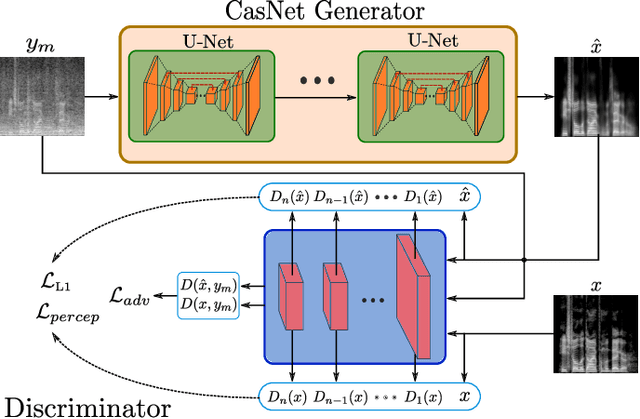

Automatic speech recognition (ASR) systems are of vital importance nowadays in commonplace tasks such as speech-to-text processing and language translation. This created the need of an ASR system that can operate in realistic crowded environments. Thus, speech enhancement is now considered as a fundamental building block in newly developed ASR systems. In this paper, a generative adversarial network (GAN) based framework is investigated for the task of speech enhancement of audio tracks. A new architecture based on CasNet generator and additional perceptual loss is incorporated to get realistically denoised speech phonetics. Finally, the proposed framework is shown to quantitatively outperform other GAN-based speech enhancement approaches.
ipA-MedGAN: Inpainting of Arbitrarily Regions in Medical Modalities
Oct 21, 2019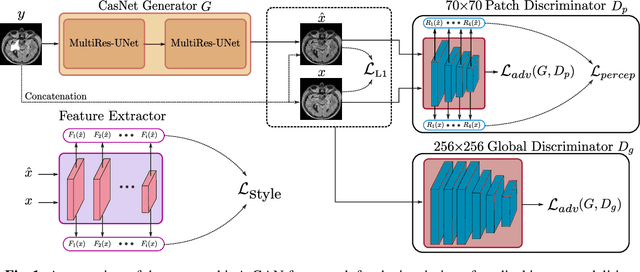
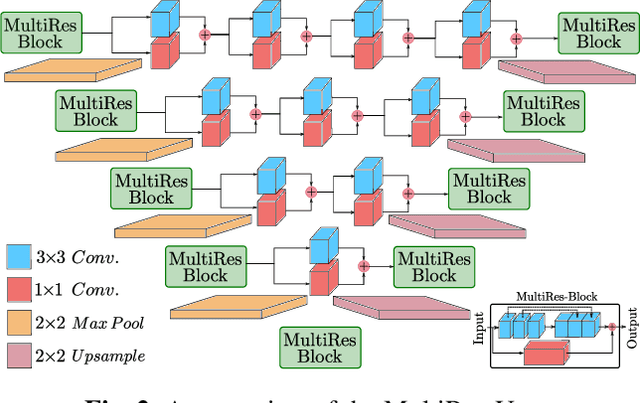
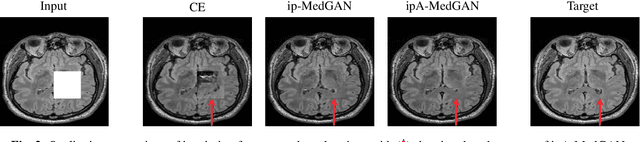
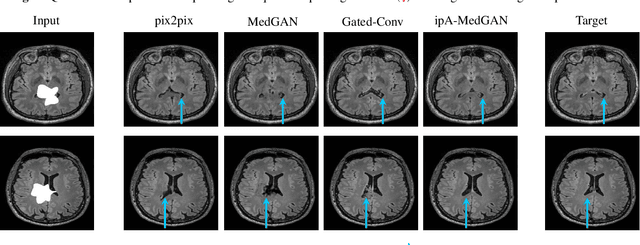
Local deformations in medical modalities are common phenomena due to a multitude of factors such as metallic implants or limited field of views in magnetic resonance imaging (MRI). Completion of the missing or distorted regions is of special interest for automatic image analysis frameworks to enhance post-processing tasks such as segmentation or classification. In this work, we propose a new generative framework for medical image inpainting, titled ipA-MedGAN. It bypasses the limitations of previous frameworks by enabling inpainting of arbitrarily shaped regions without a prior localization of the regions of interest. Thorough qualitative and quantitative comparisons with other inpainting and translational approaches have illustrated the superior performance of the proposed framework for the task of brain MR inpainting.
Organ-based Age Estimation based on 3D MRI Scans
Oct 14, 2019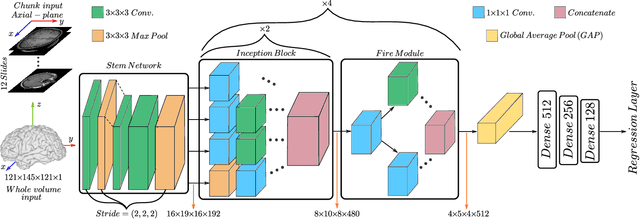
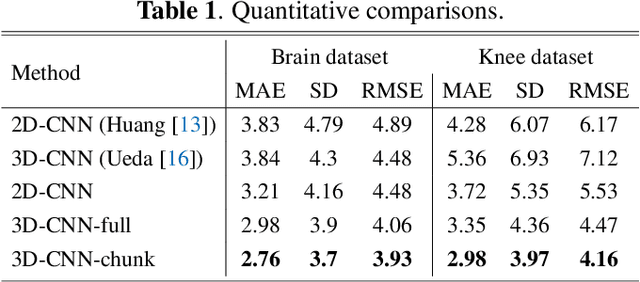

Individuals age differently depending on a multitude of different factors such as lifestyle, medical history and genetics. Often, the global chronological age is not indicative of the true ageing process. An organ-based age estimation would yield a more accurate health state assessment. In this work, we propose a new deep learning architecture for organ-based age estimation based on magnetic resonance images (MRI). The proposed network is a 3D convolutional neural network (CNN) with increased depth and width made possible by the hybrid utilization of inception and fire modules. We apply the proposed framework for the tasks of brain and knee age estimation. Quantitative comparisons against concurrent MR-based regression networks illustrated the superior performance of the proposed work.
Unsupervised Adversarial Correction of Rigid MR Motion Artifacts
Oct 12, 2019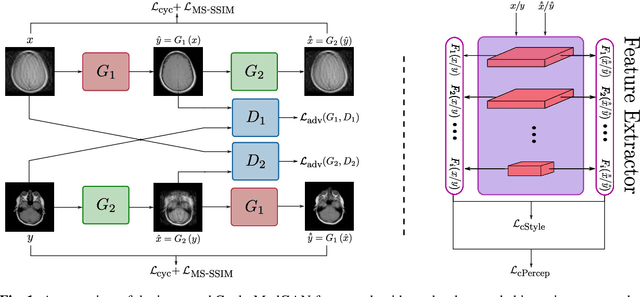
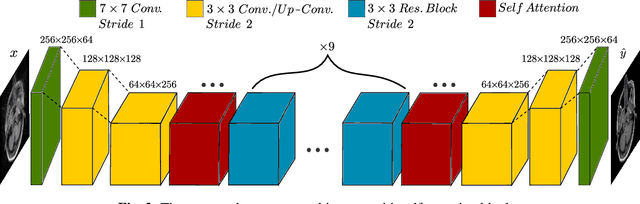
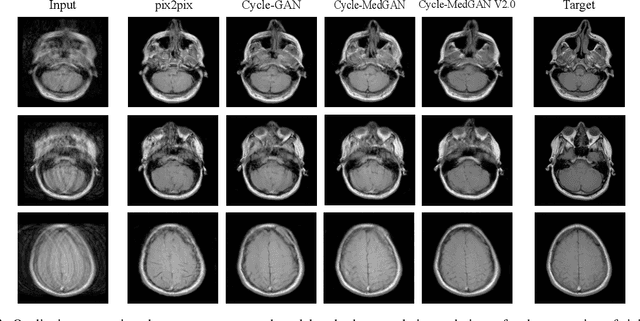
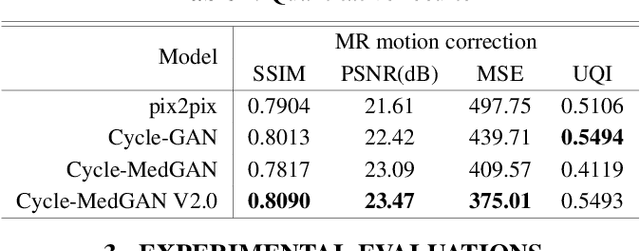
Motion is one of the main sources for artifacts in magnetic resonance (MR) images. It can have significant consequences on the diagnostic quality of the resultant scans. Previously, supervised adversarial approaches have been suggested for the correction of MR motion artifacts. However, these approaches suffer from the limitation of required paired co-registered datasets for training which are often hard or impossible to acquire. Building upon our previous work, we introduce a new adversarial framework with a new generator architecture and loss function for the unsupervised correction of severe rigid motion artifacts in the brain region. Quantitative and qualitative comparisons with other supervised and unsupervised translation approaches showcase the enhanced performance of the introduced framework.