 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLPC: a VRNN-based approach for stochastic lidar prediction and completion in autonomous driving
Paper and Code
Feb 19, 2021
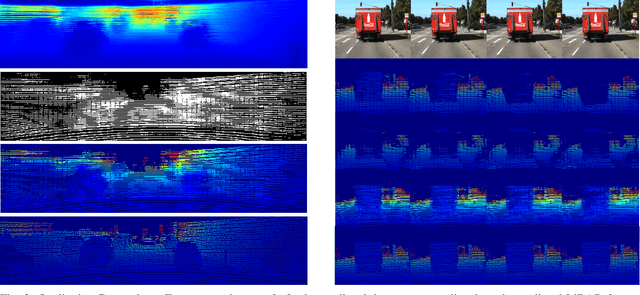
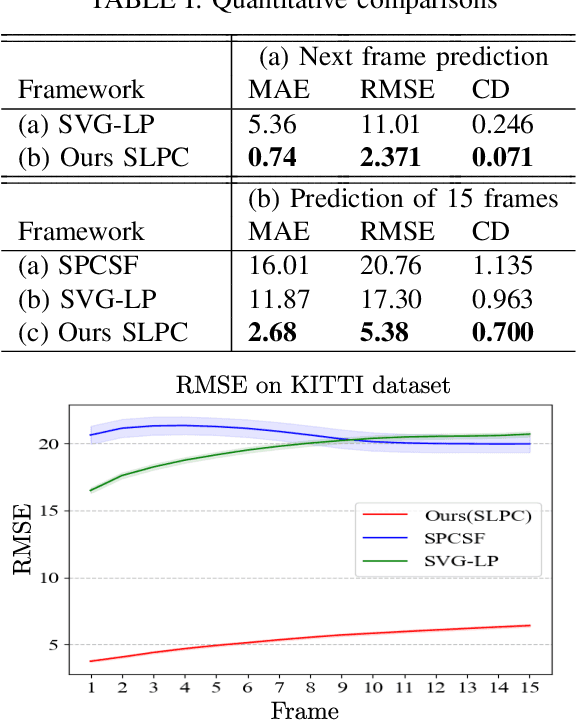
Predicting future 3D LiDAR pointclouds is a challenging task that is useful in many applications in autonomous driving such as trajectory prediction, pose forecasting and decision making. In this work, we propose a new LiDAR prediction framework that is based on generative models namely Variational Recurrent Neural Networks (VRNNs), titled Stochastic LiDAR Prediction and Completion (SLPC). Our algorithm is able to address the limitations of previous video prediction frameworks when dealing with sparse data by spatially inpainting the depth maps in the upcoming frames. Our contributions can thus be summarized as follows: we introduce the new task of predicting and completing depth maps from spatially sparse data, we present a sparse version of VRNNs and an effective self-supervised training method that does not require any labels. Experimental results illustrate the effectiveness of our framework in comparison to the state of the art methods in video prediction.