 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Cross-Domain Losses for Speech Enhancement
Oct 20, 2020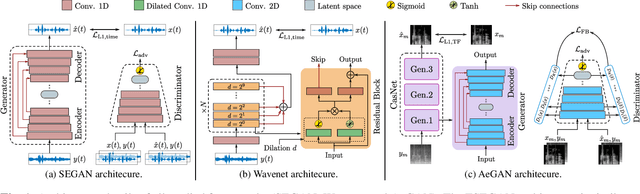
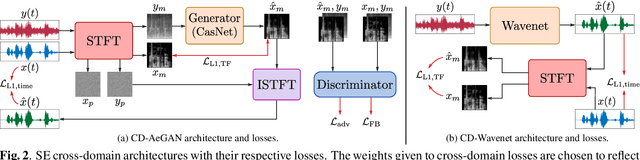
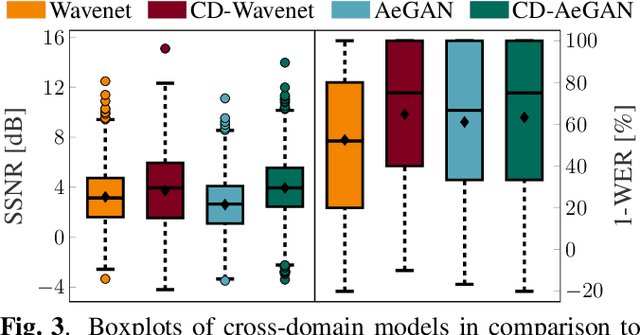
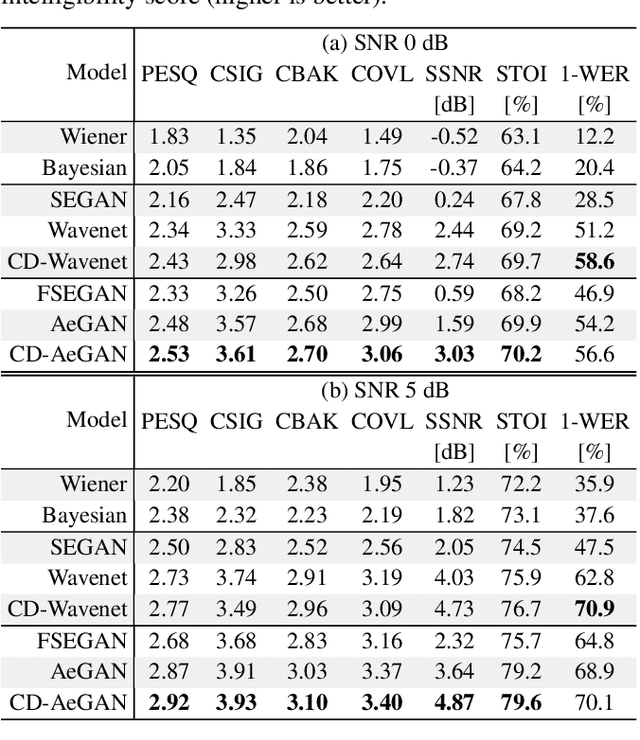
Recent years have seen a surge in the number of available frameworks for speech enhancement (SE) and recognition. Whether model-based or constructed via deep learning, these frameworks often rely in isolation on either time-domain signals or time-frequency (TF) representations of speech data. In this study, we investigate the advantages of each set of approaches by separately examining their impact on speech intelligibility and quality. Furthermore, we combine the fragmented benefits of time-domain and TF speech representations by introducing two new cross-domain SE frameworks. A quantitative comparative analysis against recent model-based and deep learning SE approaches is performed to illustrate the merit of the proposed frameworks.
Perceptual Speech Enhancement via Generative Adversarial Networks
Oct 21, 2019

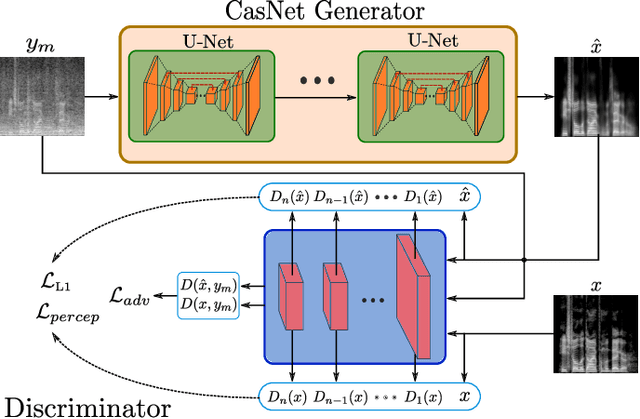

Automatic speech recognition (ASR) systems are of vital importance nowadays in commonplace tasks such as speech-to-text processing and language translation. This created the need of an ASR system that can operate in realistic crowded environments. Thus, speech enhancement is now considered as a fundamental building block in newly developed ASR systems. In this paper, a generative adversarial network (GAN) based framework is investigated for the task of speech enhancement of audio tracks. A new architecture based on CasNet generator and additional perceptual loss is incorporated to get realistically denoised speech phonetics. Finally, the proposed framework is shown to quantitatively outperform other GAN-based speech enhancement approaches.