 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniFashion: A Unified Vision-Language Model for Multimodal Fashion Retrieval and Generation
Paper and Code

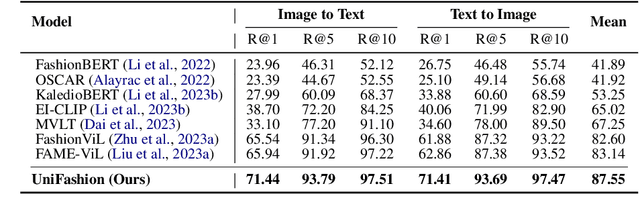
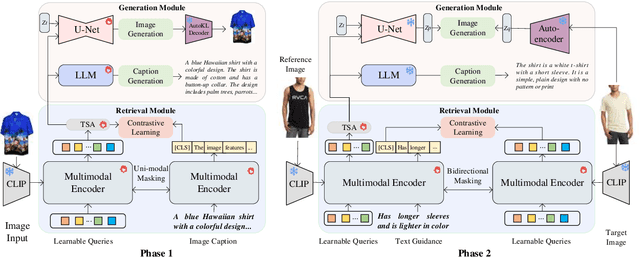
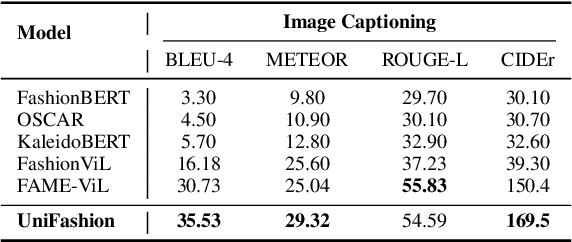
The fashion domain encompasses a variety of real-world multimodal tasks, including multimodal retrieval and multimodal generation. The rapid advancements in artificial intelligence generated content, particularly in technologies like large language models for text generation and diffusion models for visual generation, have sparked widespread research interest in applying these multimodal models in the fashion domain. However, tasks involving embeddings, such as image-to-text or text-to-image retrieval, have been largely overlooked from this perspective due to the diverse nature of the multimodal fashion domain. And current research on multi-task single models lack focus on image generation. In this work, we present UniFashion, a unified framework that simultaneously tackles the challenges of multimodal generation and retrieval tasks within the fashion domain, integrating image generation with retrieval tasks and text generation tasks. UniFashion unifies embedding and generative tasks by integrating a diffusion model and LLM, enabling controllable and high-fidelity generation. Our model significantly outperforms previous single-task state-of-the-art models across diverse fashion tasks, and can be readily adapted to manage complex vision-language tasks. This work demonstrates the potential learning synergy between multimodal generation and retrieval, offering a promising direction for future research in the fashion domain. The source code is available at https://github.com/xiangyu-mm/UniFashion.