 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEXAONE 4.5 Technical Report
Apr 09, 2026This technical report introduces EXAONE 4.5, the first open-weight vision language model released by LG AI Research. EXAONE 4.5 is architected by integrating a dedicated visual encoder into the existing EXAONE 4.0 framework, enabling native multimodal pretraining over both visual and textual modalities. The model is trained on large-scale data with careful curation, particularly emphasizing document-centric corpora that align with LG's strategic application domains. This targeted data design enables substantial performance gains in document understanding and related tasks, while also delivering broad improvements across general language capabilities. EXAONE 4.5 extends context length up to 256K tokens, facilitating long-context reasoning and enterprise-scale use cases. Comparative evaluations demonstrate that EXAONE 4.5 achieves competitive performance in general benchmarks while outperforming state-of-the-art models of similar scale in document understanding and Korean contextual reasoning. As part of LG's ongoing effort toward practical industrial deployment, EXAONE 4.5 is designed to be continuously extended with additional domains and application scenarios to advance AI for a better life.
MolMole: Molecule Mining from Scientific Literature
May 08, 2025The extraction of molecular structures and reaction data from scientific documents is challenging due to their varied, unstructured chemical formats and complex document layouts. To address this, we introduce MolMole, a vision-based deep learning framework that unifies molecule detection, reaction diagram parsing, and optical chemical structure recognition (OCSR) into a single pipeline for automating the extraction of chemical data directly from page-level documents. Recognizing the lack of a standard page-level benchmark and evaluation metric, we also present a testset of 550 pages annotated with molecule bounding boxes, reaction labels, and MOLfiles, along with a novel evaluation metric. Experimental results demonstrate that MolMole outperforms existing toolkits on both our benchmark and public datasets. The benchmark testset will be publicly available, and the MolMole toolkit will be accessible soon through an interactive demo on the LG AI Research website. For commercial inquiries, please contact us at \href{mailto:contact_ddu@lgresearch.ai}{contact\_ddu@lgresearch.ai}.
Universal Noise Annotation: Unveiling the Impact of Noisy annotation on Object Detection
Dec 21, 2023For object detection task with noisy labels, it is important to consider not only categorization noise, as in image classification, but also localization noise, missing annotations, and bogus bounding boxes. However, previous studies have only addressed certain types of noise (e.g., localization or categorization). In this paper, we propose Universal-Noise Annotation (UNA), a more practical setting that encompasses all types of noise that can occur in object detection, and analyze how UNA affects the performance of the detector. We analyzed the development direction of previous works of detection algorithms and examined the factors that impact the robustness of detection model learning method. We open-source the code for injecting UNA into the dataset and all the training log and weight are also shared.
Misalign, Contrast then Distill: Rethinking Misalignments in Language-Image Pretraining
Dec 19, 2023Contrastive Language-Image Pretraining has emerged as a prominent approach for training vision and text encoders with uncurated image-text pairs from the web. To enhance data-efficiency, recent efforts have introduced additional supervision terms that involve random-augmented views of the image. However, since the image augmentation process is unaware of its text counterpart, this procedure could cause various degrees of image-text misalignments during training. Prior methods either disregarded this discrepancy or introduced external models to mitigate the impact of misalignments during training. In contrast, we propose a novel metric learning approach that capitalizes on these misalignments as an additional training source, which we term "Misalign, Contrast then Distill (MCD)". Unlike previous methods that treat augmented images and their text counterparts as simple positive pairs, MCD predicts the continuous scales of misalignment caused by the augmentation. Our extensive experimental results show that our proposed MCD achieves state-of-the-art transferability in multiple classification and retrieval downstream datasets.
Expediting Contrastive Language-Image Pretraining via Self-distilled Encoders
Dec 19, 2023Recent advances in vision language pretraining (VLP) have been largely attributed to the large-scale data collected from the web. However, uncurated dataset contains weakly correlated image-text pairs, causing data inefficiency. To address the issue, knowledge distillation have been explored at the expense of extra image and text momentum encoders to generate teaching signals for misaligned image-text pairs. In this paper, our goal is to resolve the misalignment problem with an efficient distillation framework. To this end, we propose ECLIPSE: Expediting Contrastive Language-Image Pretraining with Self-distilled Encoders. ECLIPSE features a distinctive distillation architecture wherein a shared text encoder is utilized between an online image encoder and a momentum image encoder. This strategic design choice enables the distillation to operate within a unified projected space of text embedding, resulting in better performance. Based on the unified text embedding space, ECLIPSE compensates for the additional computational cost of the momentum image encoder by expediting the online image encoder. Through our extensive experiments, we validate that there is a sweet spot between expedition and distillation where the partial view from the expedited online image encoder interacts complementarily with the momentum teacher. As a result, ECLIPSE outperforms its counterparts while achieving substantial acceleration in inference speed.
Rethinking Deep Image Prior for Denoising
Aug 29, 2021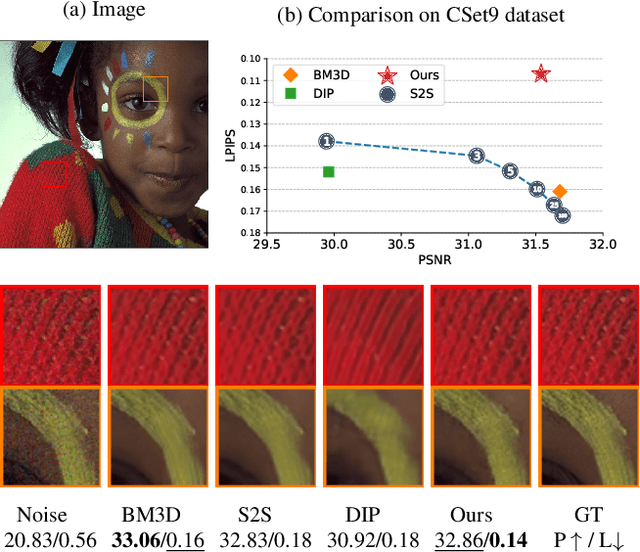
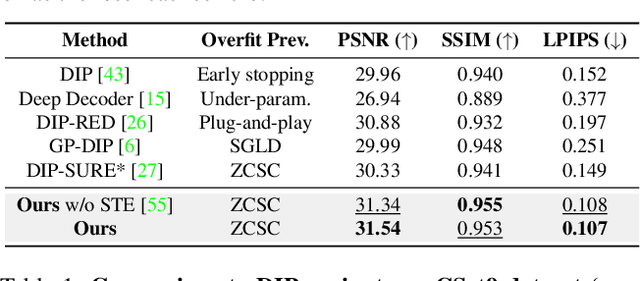
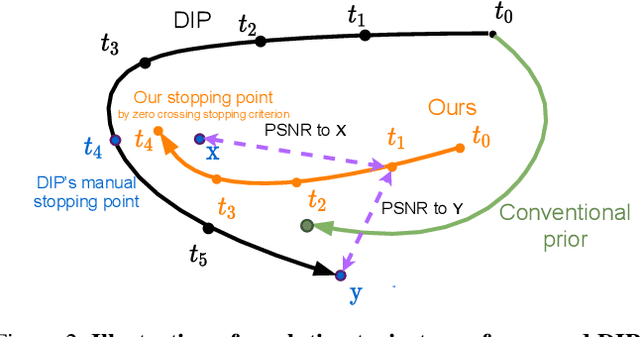

Deep image prior (DIP) serves as a good inductive bias for diverse inverse problems. Among them, denoising is known to be particularly challenging for the DIP due to noise fitting with the requirement of an early stopping. To address the issue, we first analyze the DIP by the notion of effective degrees of freedom (DF) to monitor the optimization progress and propose a principled stopping criterion before fitting to noise without access of a paired ground truth image for Gaussian noise. We also propose the `stochastic temporal ensemble (STE)' method for incorporating techniques to further improve DIP's performance for denoising. We additionally extend our method to Poisson noise. Our empirical validations show that given a single noisy image, our method denoises the image while preserving rich textual details. Further, our approach outperforms prior arts in LPIPS by large margins with comparable PSNR and SSIM on seven different datasets.
Incremental Learning with Maximum Entropy Regularization: Rethinking Forgetting and Intransigence
Feb 03, 2019
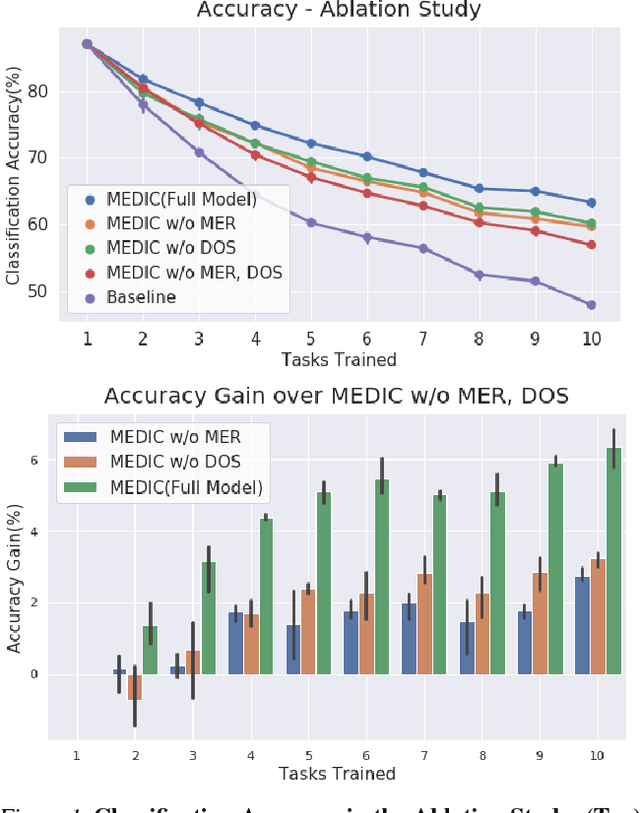
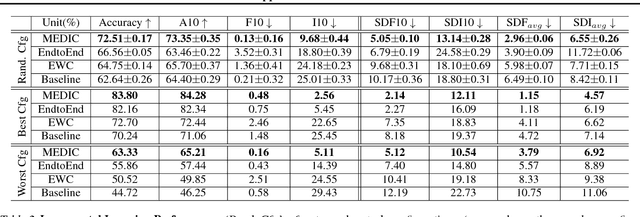
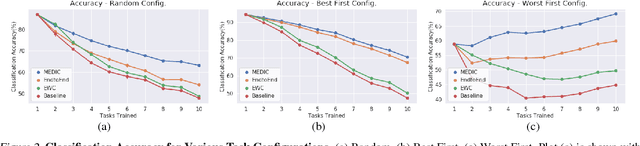
Incremental learning suffers from two challenging problems; forgetting of old knowledge and intransigence on learning new knowledge. Prediction by the model incrementally learned with a subset of the dataset are thus uncertain and the uncertainty accumulates through the tasks by knowledge transfer. To prevent overfitting to the uncertain knowledge, we propose to penalize confident fitting to the uncertain knowledge by the Maximum Entropy Regularizer (MER). Additionally, to reduce class imbalance and induce a self-paced curriculum on new classes, we exclude a few samples from the new classes in every mini-batch, which we call DropOut Sampling (DOS). We further rethink evaluation metrics for forgetting and intransigence in incremental learning by tracking each sample's confusion at the transition of a task since the existing metrics that compute the difference in accuracy are often misleading. We show that the proposed method, named 'MEDIC', outperforms the state-of-the-art incremental learning algorithms in accuracy, forgetting, and intransigence measured by both the existing and the proposed metrics by a large margin in extensive empirical validations on CIFAR100 and a popular subset of ImageNet dataset (TinyImageNet).