 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Learning with Maximum Entropy Regularization: Rethinking Forgetting and Intransigence
Paper and Code
Feb 03, 2019
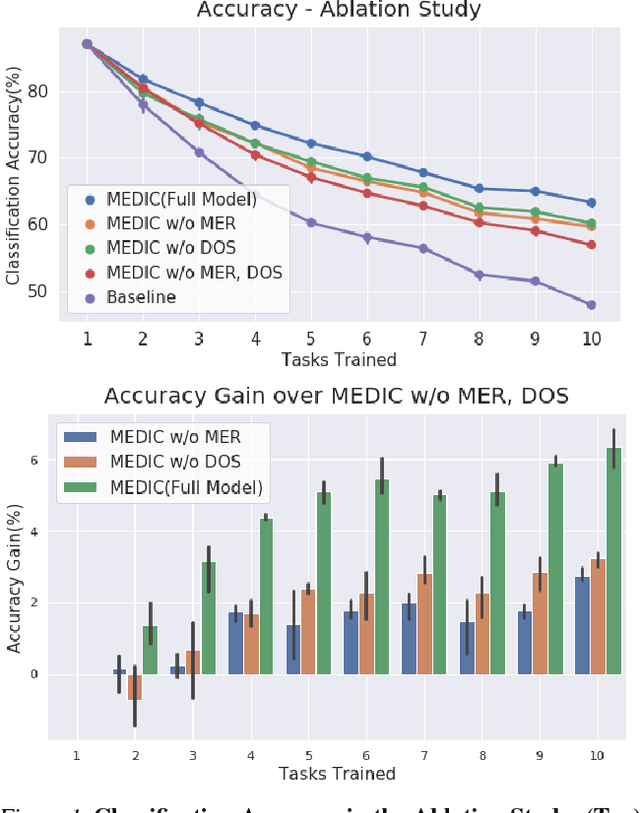
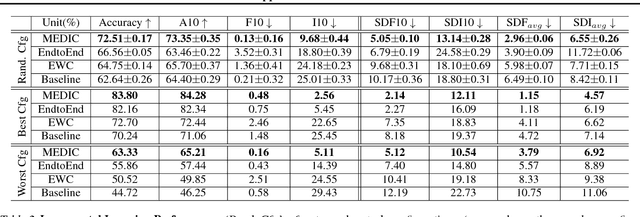
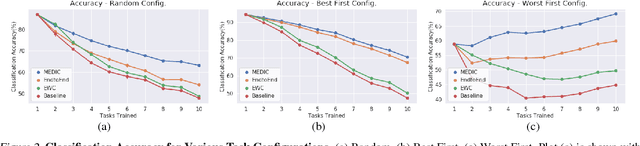
Incremental learning suffers from two challenging problems; forgetting of old knowledge and intransigence on learning new knowledge. Prediction by the model incrementally learned with a subset of the dataset are thus uncertain and the uncertainty accumulates through the tasks by knowledge transfer. To prevent overfitting to the uncertain knowledge, we propose to penalize confident fitting to the uncertain knowledge by the Maximum Entropy Regularizer (MER). Additionally, to reduce class imbalance and induce a self-paced curriculum on new classes, we exclude a few samples from the new classes in every mini-batch, which we call DropOut Sampling (DOS). We further rethink evaluation metrics for forgetting and intransigence in incremental learning by tracking each sample's confusion at the transition of a task since the existing metrics that compute the difference in accuracy are often misleading. We show that the proposed method, named 'MEDIC', outperforms the state-of-the-art incremental learning algorithms in accuracy, forgetting, and intransigence measured by both the existing and the proposed metrics by a large margin in extensive empirical validations on CIFAR100 and a popular subset of ImageNet dataset (TinyImageNet).