 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Reduction for 3D Point Cloud Self-Supervised Traversability Estimation
Nov 21, 2022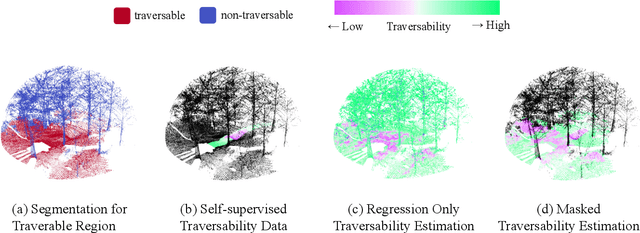
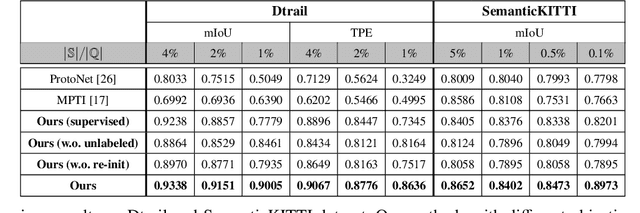
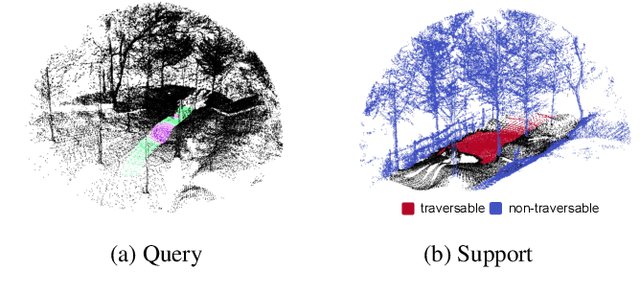

Traversability estimation in off-road environments requires a robust perception system. Recently, approaches to learning a traversability estimation from past vehicle experiences in a self-supervised manner are arising as they can greatly reduce human labeling costs and labeling errors. Nonetheless, the learning setting from self-supervised traversability estimation suffers from congenital uncertainties that appear according to the scarcity of negative information. Negative data are rarely harvested as the system can be severely damaged while logging the data. To mitigate the uncertainty, we introduce a method to incorporate unlabeled data in order to leverage the uncertainty. First, we design a learning architecture that inputs query and support data. Second, unlabeled data are assigned based on the proximity in the metric space. Third, a new metric for uncertainty measures is introduced. We evaluated our approach on our own dataset, `Dtrail', which is composed of a wide variety of negative data.
Derivative Action Control: Smooth Model Predictive Path Integral Control without Smoothing
Jan 13, 2022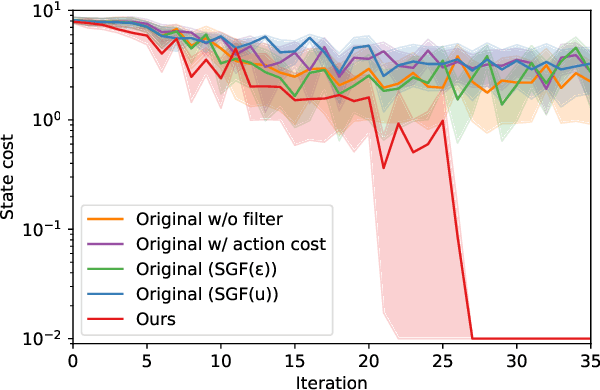

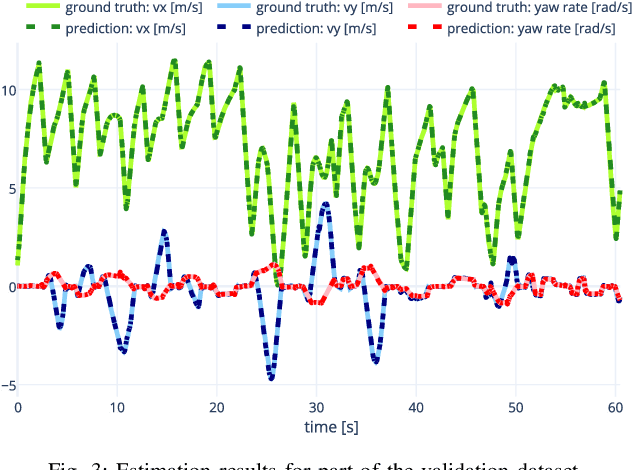

Here, we present a new approach to generate smooth control sequences in Model Predictive Path Integral control (MPPI) tasks without any additional smoothing algorithms. Our method effectively alleviates the chattering in sampling, while the information theoretic derivation of MPPI remains the same. We demonstrated the proposed method in a challenging autonomous driving task with quantitative evaluation of different algorithms. A neural network vehicle model for estimating system dynamics under varying road friction conditions is also presented. Our video can be found at: \url{https://youtu.be/o3Nmi0UJFqg}.
Incremental Learning with Maximum Entropy Regularization: Rethinking Forgetting and Intransigence
Feb 03, 2019
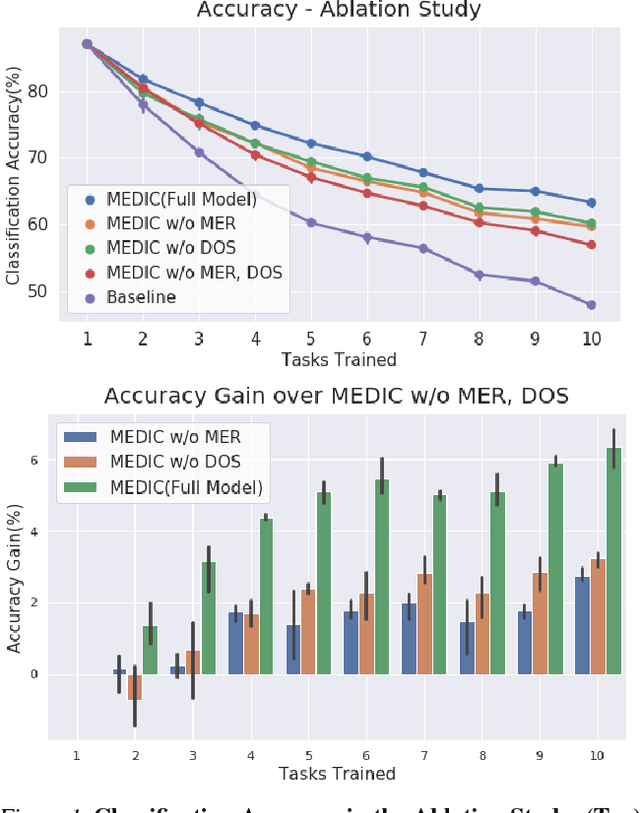
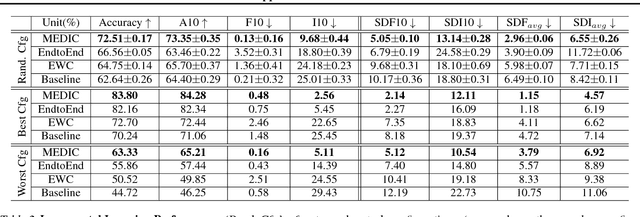
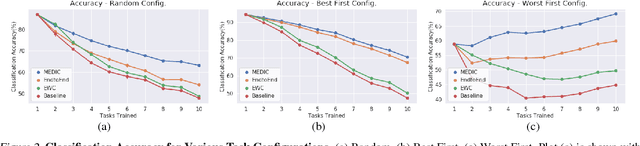
Incremental learning suffers from two challenging problems; forgetting of old knowledge and intransigence on learning new knowledge. Prediction by the model incrementally learned with a subset of the dataset are thus uncertain and the uncertainty accumulates through the tasks by knowledge transfer. To prevent overfitting to the uncertain knowledge, we propose to penalize confident fitting to the uncertain knowledge by the Maximum Entropy Regularizer (MER). Additionally, to reduce class imbalance and induce a self-paced curriculum on new classes, we exclude a few samples from the new classes in every mini-batch, which we call DropOut Sampling (DOS). We further rethink evaluation metrics for forgetting and intransigence in incremental learning by tracking each sample's confusion at the transition of a task since the existing metrics that compute the difference in accuracy are often misleading. We show that the proposed method, named 'MEDIC', outperforms the state-of-the-art incremental learning algorithms in accuracy, forgetting, and intransigence measured by both the existing and the proposed metrics by a large margin in extensive empirical validations on CIFAR100 and a popular subset of ImageNet dataset (TinyImageNet).