 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOSS: Motion-based 3D Clothed Human Synthesis from Monocular Video
May 21, 2024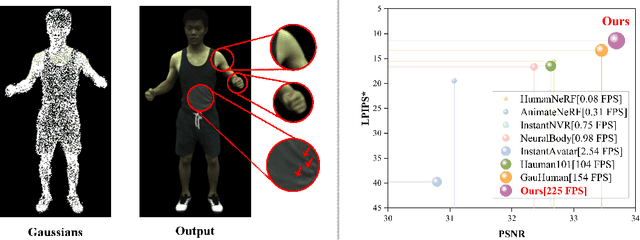
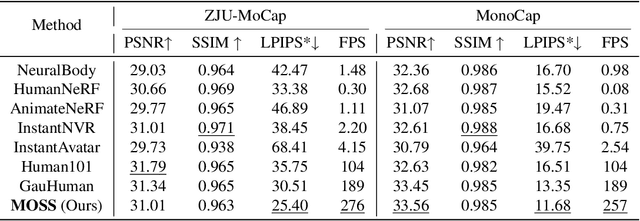
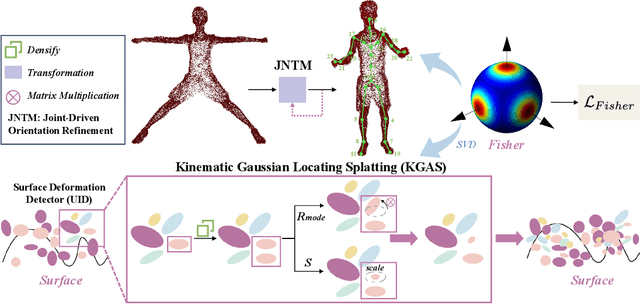

Single-view clothed human reconstruction holds a central position in virtual reality applications, especially in contexts involving intricate human motions. It presents notable challenges in achieving realistic clothing deformation. Current methodologies often overlook the influence of motion on surface deformation, resulting in surfaces lacking the constraints imposed by global motion. To overcome these limitations, we introduce an innovative framework, Motion-Based 3D Clothed Humans Synthesis (MOSS), which employs kinematic information to achieve motion-aware Gaussian split on the human surface. Our framework consists of two modules: Kinematic Gaussian Locating Splatting (KGAS) and Surface Deformation Detector (UID). KGAS incorporates matrix-Fisher distribution to propagate global motion across the body surface. The density and rotation factors of this distribution explicitly control the Gaussians, thereby enhancing the realism of the reconstructed surface. Additionally, to address local occlusions in single-view, based on KGAS, UID identifies significant surfaces, and geometric reconstruction is performed to compensate for these deformations. Experimental results demonstrate that MOSS achieves state-of-the-art visual quality in 3D clothed human synthesis from monocular videos. Notably, we improve the Human NeRF and the Gaussian Splatting by 33.94% and 16.75% in LPIPS* respectively. Codes are available at https://wanghongsheng01.github.io/MOSS/.
3DFusion, A real-time 3D object reconstruction pipeline based on streamed instance segmented data
Nov 11, 2023
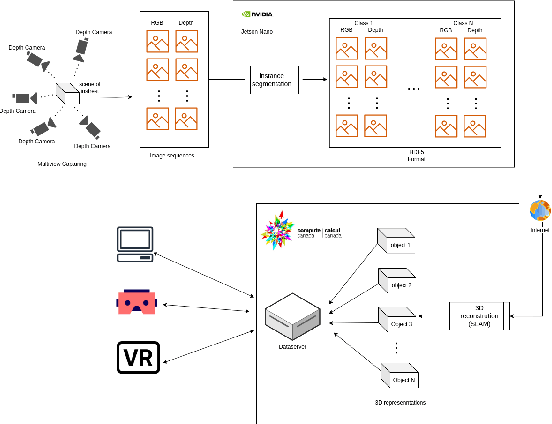
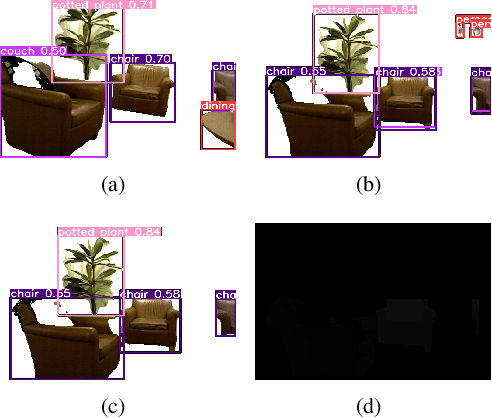
This paper presents a real-time segmentation and reconstruction system that utilizes RGB-D images to generate accurate and detailed individual 3D models of objects within a captured scene. Leveraging state-of-the-art instance segmentation techniques, the system performs pixel-level segmentation on RGB-D data, effectively separating foreground objects from the background. The segmented objects are then reconstructed into distinct 3D models in a high-performance computation platform. The real-time 3D modelling can be applied across various domains, including augmented/virtual reality, interior design, urban planning, road assistance, security systems, and more. To achieve real-time performance, the paper proposes a method that effectively samples consecutive frames to reduce network load while ensuring reconstruction quality. Additionally, a multi-process SLAM pipeline is adopted for parallel 3D reconstruction, enabling efficient cutting of the clustering objects into individuals. This system employs the industry-leading framework YOLO for instance segmentation. To improve YOLO's performance and accuracy, modifications were made to resolve duplicated or false detection of similar objects, ensuring the reconstructed models align with the targets. Overall, this work establishes a robust real-time system with a significant enhancement for object segmentation and reconstruction in the indoor environment. It can potentially be extended to the outdoor scenario, opening up numerous opportunities for real-world applications.
When We First Met: Visual-Inertial Person Localization for Co-Robot Rendezvous
Jun 17, 2020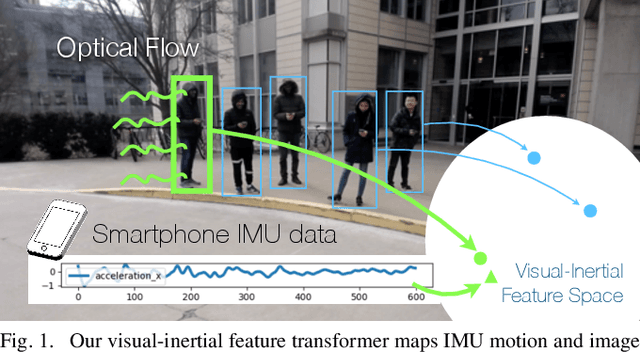

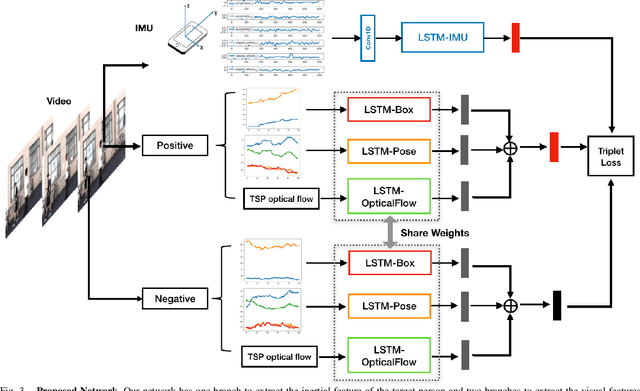
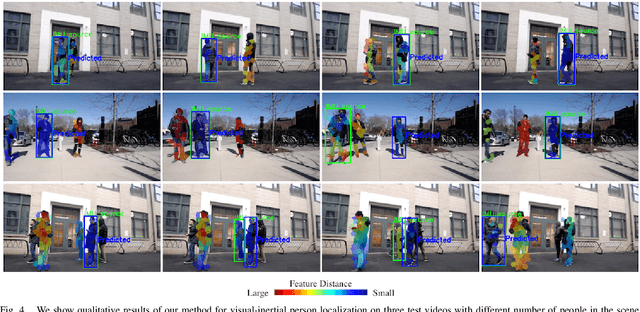
We aim to enable robots to visually localize a target person through the aid of an additional sensing modality -- the target person's 3D inertial measurements. The need for such technology may arise when a robot is to meet person in a crowd for the first time or when an autonomous vehicle must rendezvous with a rider amongst a crowd without knowing the appearance of the person in advance. A person's inertial information can be measured with a wearable device such as a smart-phone and can be shared selectively with an autonomous system during the rendezvous. We propose a method to learn a visual-inertial feature space in which the motion of a person in video can be easily matched to the motion measured by a wearable inertial measurement unit (IMU). The transformation of the two modalities into the joint feature space is learned through the use of a contrastive loss which forces inertial motion features and video motion features generated by the same person to lie close in the joint feature space. To validate our approach, we compose a dataset of over 60,000 video segments of moving people along with wearable IMU data. Our experiments show that our proposed method is able to accurately localize a target person with 80.7% accuracy using only 5 seconds of IMU data and video.