 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVistaFormer: Scalable Vision Transformers for Satellite Image Time Series Segmentation
Sep 13, 2024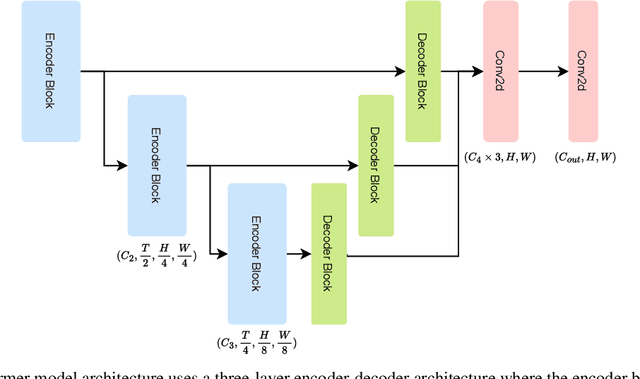

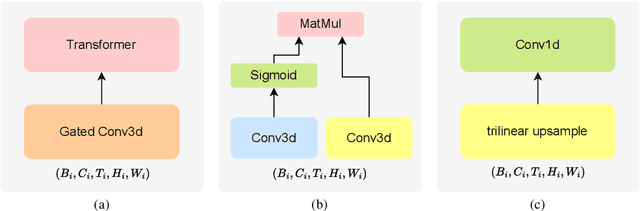

We introduce VistaFormer, a lightweight Transformer-based model architecture for the semantic segmentation of remote-sensing images. This model uses a multi-scale Transformer-based encoder with a lightweight decoder that aggregates global and local attention captured in the encoder blocks. VistaFormer uses position-free self-attention layers which simplifies the model architecture and removes the need to interpolate temporal and spatial codes, which can reduce model performance when training and testing image resolutions differ. We investigate simple techniques for filtering noisy input signals like clouds and demonstrate that improved model scalability can be achieved by substituting Multi-Head Self-Attention (MHSA) with Neighbourhood Attention (NA). Experiments on the PASTIS and MTLCC crop-type segmentation benchmarks show that VistaFormer achieves better performance than comparable models and requires only 8% of the floating point operations using MHSA and 11% using NA while also using fewer trainable parameters. VistaFormer with MHSA improves on state-of-the-art mIoU scores by 0.1% on the PASTIS benchmark and 3% on the MTLCC benchmark while VistaFormer with NA improves on the MTLCC benchmark by 3.7%.
Delta Tensor: Efficient Vector and Tensor Storage in Delta Lake
May 03, 2024The exponential growth of artificial intelligence (AI) and machine learning (ML) applications has necessitated the development of efficient storage solutions for vector and tensor data. This paper presents a novel approach for tensor storage in a Lakehouse architecture using Delta Lake. By adopting the multidimensional array storage strategy from array databases and sparse encoding methods to Delta Lake tables, experiments show that this approach has demonstrated notable improvements in both space and time efficiencies when compared to traditional serialization of tensors. These results provide valuable insights for the development and implementation of optimized vector and tensor storage solutions in data-intensive applications, contributing to the evolution of efficient data management practices in AI and ML domains in cloud-native environments
Using Texture to Classify Forests Separately from Vegetation
May 01, 2024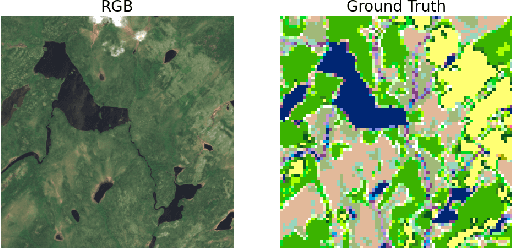
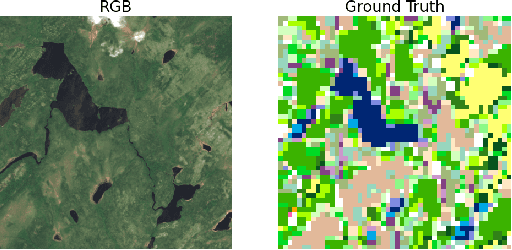


Identifying terrain within satellite image data is a key issue in geographical information sciences, with numerous environmental and safety implications. Many techniques exist to derive classifications from spectral data captured by satellites. However, the ability to reliably classify vegetation remains a challenge. In particular, no precise methods exist for classifying forest vs. non-forest vegetation in high-level satellite images. This paper provides an initial proposal for a static, algorithmic process to identify forest regions in satellite image data through texture features created from detected edges and the NDVI ratio captured by Sentinel-2 satellite images. With strong initial results, this paper also identifies the next steps to improve the accuracy of the classification and verification processes.
Human Latency Conversational Turns for Spoken Avatar Systems
Apr 11, 2024A problem with many current Large Language Model (LLM) driven spoken dialogues is the response time. Some efforts such as Groq address this issue by lightning fast processing of the LLM, but we know from the cognitive psychology literature that in human-to-human dialogue often responses occur prior to the speaker completing their utterance. No amount of delay for LLM processing is acceptable if we wish to maintain human dialogue latencies. In this paper, we discuss methods for understanding an utterance in close to real time and generating a response so that the system can comply with human-level conversational turn delays. This means that the information content of the final part of the speaker's utterance is lost to the LLM. Using the Google NaturalQuestions (NQ) database, our results show GPT-4 can effectively fill in missing context from a dropped word at the end of a question over 60% of the time. We also provide some examples of utterances and the impacts of this information loss on the quality of LLM response in the context of an avatar that is currently under development. These results indicate that a simple classifier could be used to determine whether a question is semantically complete, or requires a filler phrase to allow a response to be generated within human dialogue time constraints.
3DFusion, A real-time 3D object reconstruction pipeline based on streamed instance segmented data
Nov 11, 2023
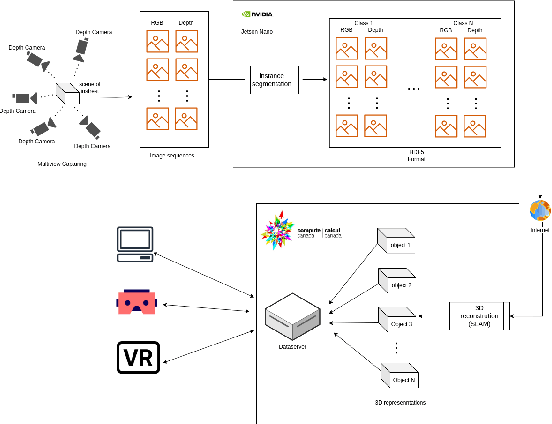
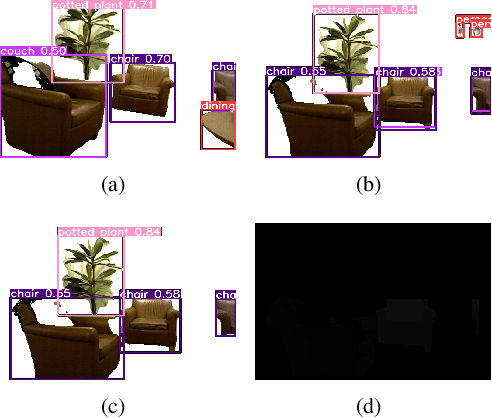
This paper presents a real-time segmentation and reconstruction system that utilizes RGB-D images to generate accurate and detailed individual 3D models of objects within a captured scene. Leveraging state-of-the-art instance segmentation techniques, the system performs pixel-level segmentation on RGB-D data, effectively separating foreground objects from the background. The segmented objects are then reconstructed into distinct 3D models in a high-performance computation platform. The real-time 3D modelling can be applied across various domains, including augmented/virtual reality, interior design, urban planning, road assistance, security systems, and more. To achieve real-time performance, the paper proposes a method that effectively samples consecutive frames to reduce network load while ensuring reconstruction quality. Additionally, a multi-process SLAM pipeline is adopted for parallel 3D reconstruction, enabling efficient cutting of the clustering objects into individuals. This system employs the industry-leading framework YOLO for instance segmentation. To improve YOLO's performance and accuracy, modifications were made to resolve duplicated or false detection of similar objects, ensuring the reconstructed models align with the targets. Overall, this work establishes a robust real-time system with a significant enhancement for object segmentation and reconstruction in the indoor environment. It can potentially be extended to the outdoor scenario, opening up numerous opportunities for real-world applications.
Intentional Biases in LLM Responses
Nov 11, 2023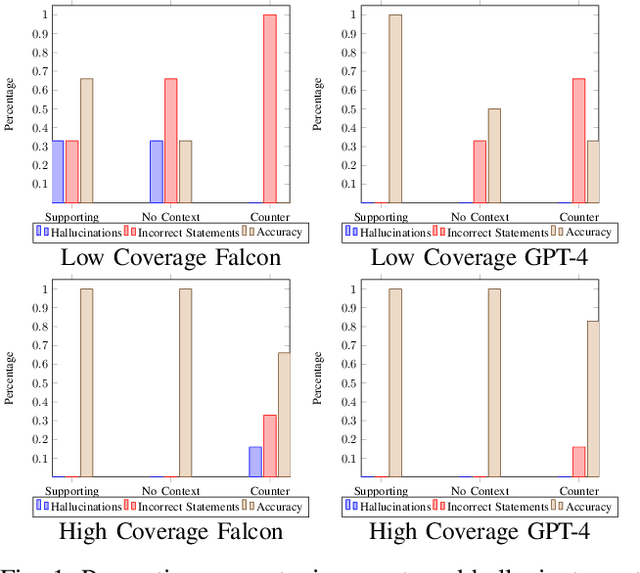
In this study we intentionally introduce biases into large language model responses in an attempt to create specific personas for interactive media purposes. We explore the differences between open source models such as Falcon-7b and the GPT-4 model from Open AI, and we quantify some differences in responses afforded by the two systems. We find that the guardrails in the GPT-4 mixture of experts models with a supervisor, while useful in assuring AI alignment in general, are detrimental in trying to construct personas with a variety of uncommon viewpoints. This study aims to set the groundwork for future exploration in intentional biases of large language models such that these practices can be applied in the creative field, and new forms of media.
MineSegSAT: An automated system to evaluate mining disturbed area extents from Sentinel-2 imagery
Nov 03, 2023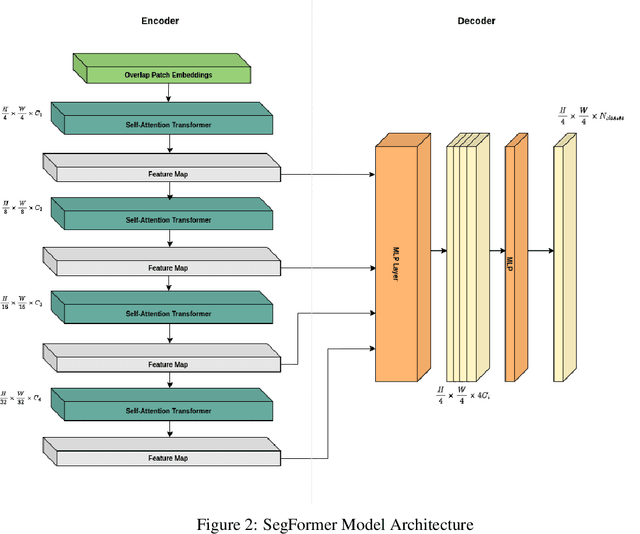
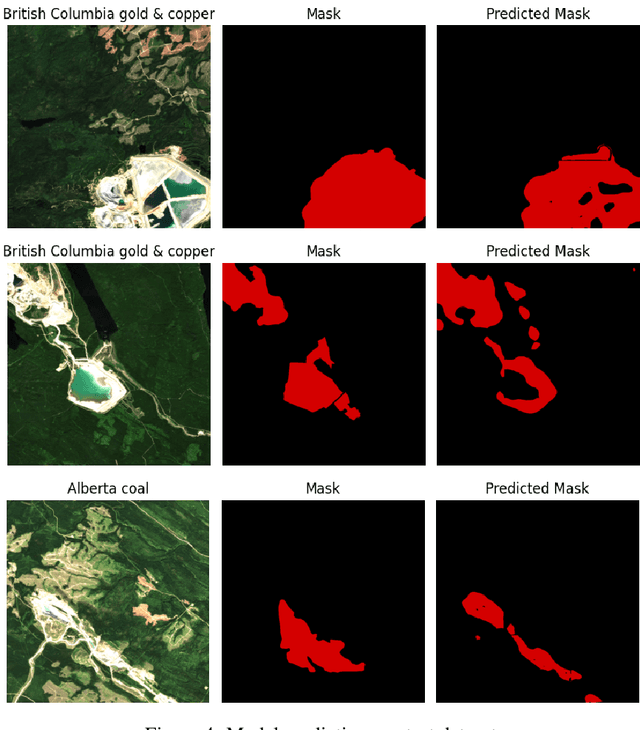
Assessing the environmental impact of the mineral extraction industry plays a critical role in understanding and mitigating the ecological consequences of extractive activities. This paper presents MineSegSAT, a model that presents a novel approach to predicting environmentally impacted areas of mineral extraction sites using the SegFormer deep learning segmentation architecture trained on Sentinel-2 data. The data was collected from non-overlapping regions over Western Canada in 2021 containing areas of land that have been environmentally impacted by mining activities that were identified from high-resolution satellite imagery in 2021. The SegFormer architecture, a state-of-the-art semantic segmentation framework, is employed to leverage its advanced spatial understanding capabilities for accurate land cover classification. We investigate the efficacy of loss functions including Dice, Tversky, and Lovasz loss respectively. The trained model was utilized for inference over the test region in the ensuing year to identify potential areas of expansion or contraction over these same periods. The Sentinel-2 data is made available on Amazon Web Services through a collaboration with Earth Daily Analytics which provides corrected and tiled analytics-ready data on the AWS platform. The model and ongoing API to access the data on AWS allow the creation of an automated tool to monitor the extent of disturbed areas surrounding known mining sites to ensure compliance with their environmental impact goals.
Efficient Cloud Pipelines for Neural Radiance Fields
Nov 03, 2023
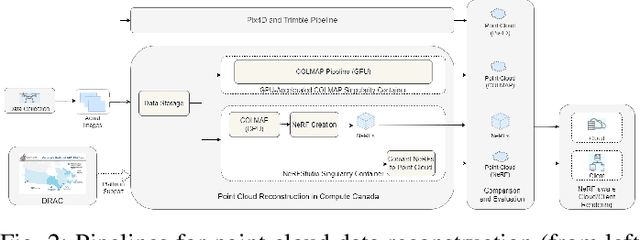
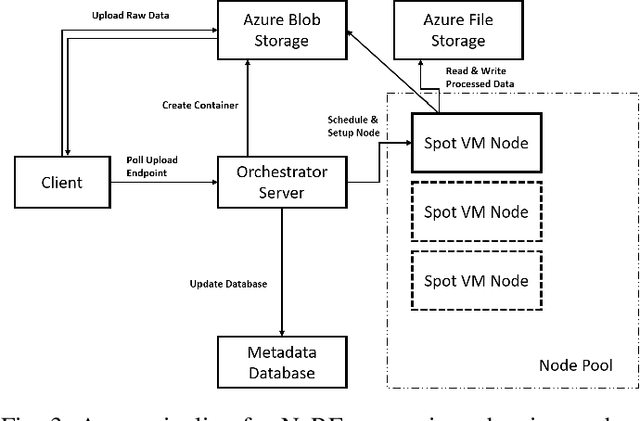

Since their introduction in 2020, Neural Radiance Fields (NeRFs) have taken the computer vision community by storm. They provide a multi-view representation of a scene or object that is ideal for eXtended Reality (XR) applications and for creative endeavors such as virtual production, as well as change detection operations in geospatial analytics. The computational cost of these generative AI models is quite high, however, and the construction of cloud pipelines to generate NeRFs is neccesary to realize their potential in client applications. In this paper, we present pipelines on a high performance academic computing cluster and compare it with a pipeline implemented on Microsoft Azure. Along the way, we describe some uses of NeRFs in enabling novel user interaction scenarios.
GPS Alignment from Multiple Sources to Extract Aircraft Bearing in Aerial Surveys
May 10, 2023
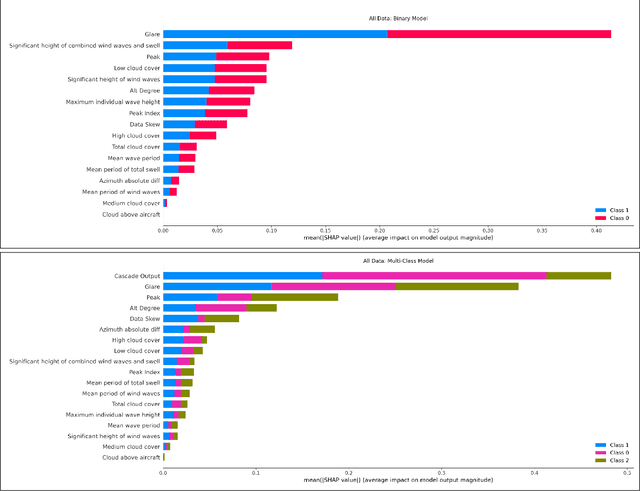
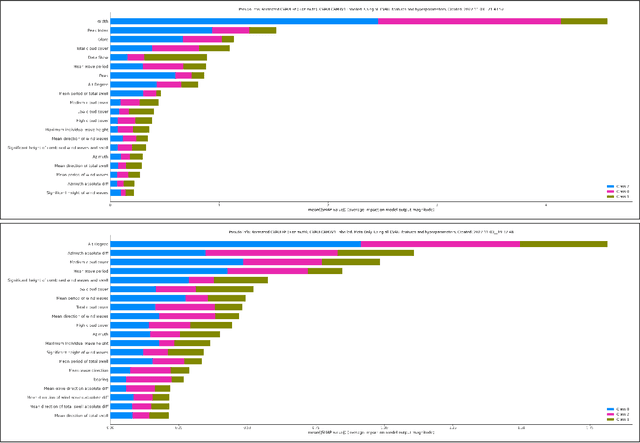
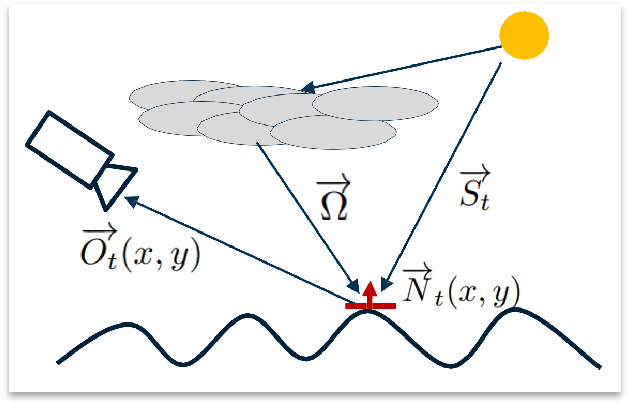
Methodical aerial population surveys monitoring critically endangered species in Canadian North Atlantic waters are instrumental in influencing government policies both in economic and conservational efforts. The primary factor hindering the success of these missions is poor visibility caused by glare. This paper builds off our foundational paper [1] and pushes the envelope toward a data-driven glare modelling system. Said data-driven system makes use of meteorological and astronomical data to assist aircraft in navigating in order to mitigate acquisition errors and optimize the quality of acquired data. It is found that reliably extracting aircraft orientation is critical to our approach, to that end, we present a GPS alignment methodology which makes use of the fusion of two GPS signals. Using the complementary strengths and weaknesses of these two signals a synthetic interpolation of fused data is used to generate more reliable flight tracks, substantially improving glare modelling. This methodology could be applied to any other applications with similar signal restrictions.